





引言
本文介绍了一种数据位宽可变的乘法方法,由于避免了DSP的使用,可以充分利用LUT资源,在DSP数量少的芯片上也可以获得很高的计算量。这种方法更适合大矩阵乘法,矩阵越大,计算效率就会越高。
01
可变位宽乘算法
方法其实很简单,就是利用数据的二进制表示方法。一个有符号二进制数,用二进制表示为:
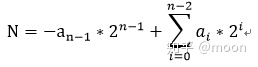
这样就将矩阵中每个数都分解成1bit数和一个权重数相乘的形式,而这个权重是2的幂次,在FPGA中可以通过简单移位操作来实现。论文中给出了一个简单的例子,求两个2x2矩阵的乘法,数据位宽为2bit。如下图1.1所示:首先将每个矩阵分解成两个矩阵之和,然后通过因式分解分别计算4个1bit矩阵乘法,然后根据权重大小进行移位操作,再求和。乘法只是1bit数,仅仅通过与操作就可以完成了,完全不需要乘法器。但是这样做也有一个缺点,就是延迟变大了。所以对于特大矩阵乘法来说,这些延迟可以通过增加计算量来弥补。以上方式用伪代码可以表示为图1.2。将这种方法进行推广,可以想到用4进制,8进制来进行数据表示,这样对于较大位宽数据来说可以降低延时。但是这样的低价就是增加了LUT资源。比如对于4进制表示,乘法数据为2bit,这个就会需要更多LUT来完成了。如果表示进制更高,比如16进制,那么用乘法器实现就更合适了。但是这无疑给我们提供了一种可变位宽乘法的设计思路。
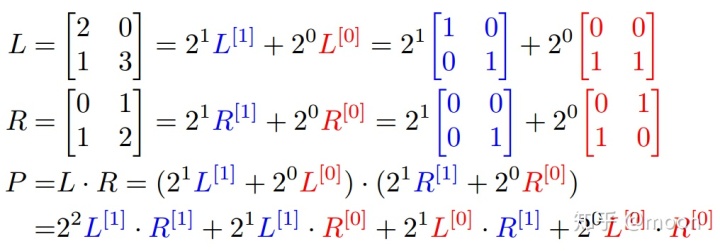
图1.1 2x2矩阵乘法分解过程

图1.2 可变位宽乘法算法
02
硬件架构
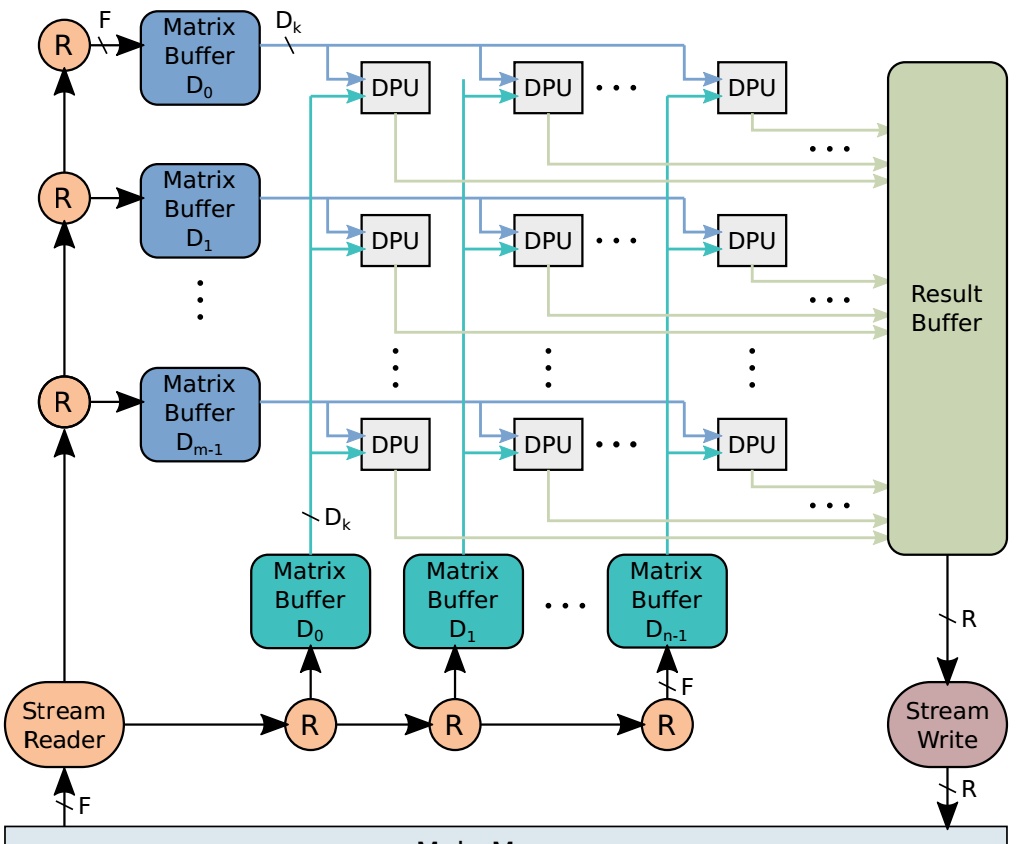
整体框架如图2.1所示,基本包括三部分:fetch,execute,result。
Fetch包含一个简单的DMA引擎,以及一个数据读取调度器,主要用于从DDR中获得指令和数据。数据被放于片上缓存中,片上缓存和计算单元通过大量走线互联,走线的带宽受到了DDR带宽的限制,而走线带宽取决于计算单元的算力。论文中参数化了这三个变量,可以根据不同平台来进行适配。
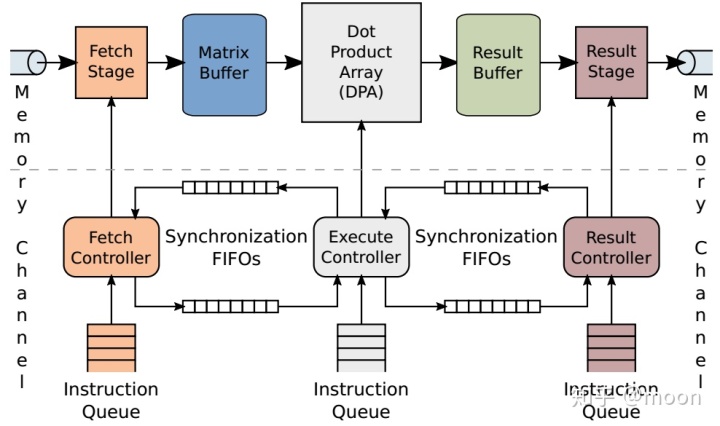
图2.1 硬件架构
Execute是最核心的计算单元,这部分由基本的DPU构成。DPU是专门处理数据乘法和累加的单元,这些DPU相互连接成二维平面结构,专门用于处理矩阵乘法。DPU结构主要由一个与门,求和,移位寄存器,累加器组成。与门和求和结构用于计算1bit矩阵乘法,移位寄存器用于乘以权重系数,累加器是用于大矩阵求和。一个大矩阵乘法是被分块的,然后每块乘法是用矩阵列x行的形式,这样计算阵列中的每行和每列对应的bufer中的数据都是被多次利用的,并且以广播形式传播到各个单元。这种方式增加了矩阵数据利用率,能够到达缓解搬运带宽。这方面计算还可以参见文章《在DNN中FPGA做了什么?》每个计算单元都会出来一个最终结果,这些结果通过并串转换分别进入result buffer。
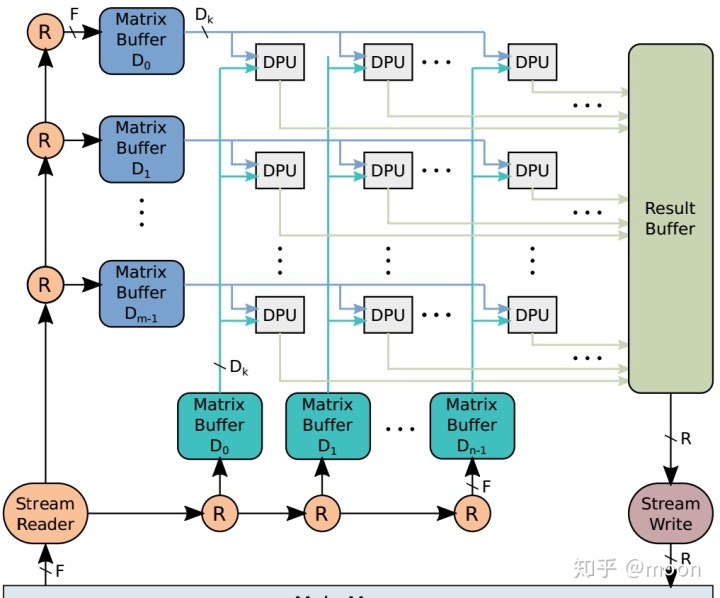
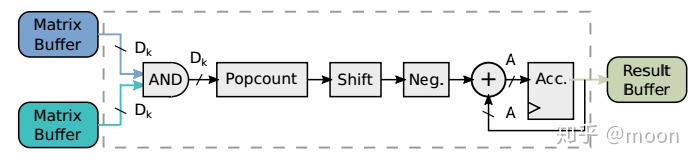
图2.2 计算结构
Result结构和fetch类似,只不过是写入DDR。也是通过DMA引擎来控制对DDR写入。
接下来介绍论文中指令架构,指令也是依据三种结构来设计成对应指令:fetch,execute,result。创新点主要在指令的pipeline设计上。其通过引入“锁”的机制来实现不同指令之间的依赖关系。用wait来阻塞下一条指令的执行,而用signal来接触wait,触发下一条指令执行。三种指令主要是fetch和result相对于execute的依赖。如果fetch完成,execute可以执行,在执行的同时,fetch可以读取下一次要用的数据,通过这样的流水来减少execute的等待时间。用一个简单过程来说明,如图2.3所示:首先execute进入等待,直到fetch了L和R矩阵数据,此时通过signal来触发execute的执行。当execute执行L*R的同时,fetch不需要等待,可以进一步下载数据。而在没有生成最终矩阵数据结果之前,result一直处于等待中,直到完成矩阵运算,execute通过signal来触发result的执行。
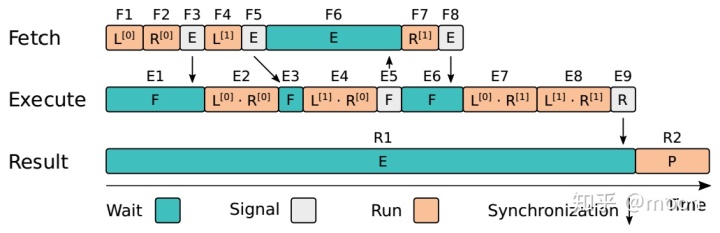
图2.3 指令依赖关系
03
结果
矩阵大小对计算效率影响很大,矩阵越大,那么矩阵元素的复用率就高,所以计算效率也越高。
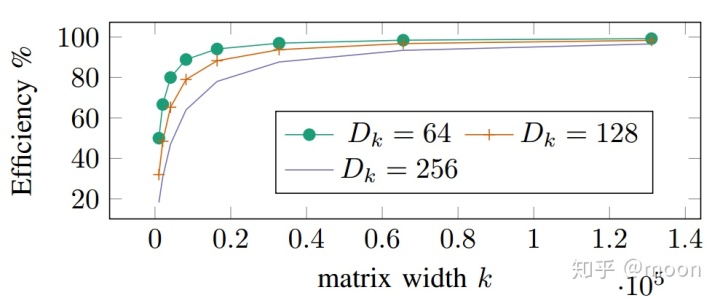
图3.1 计算效率和矩阵大小k以及数据位宽D_k关系
资源利用和峰值算力如图3.2,最大算力达到了3.2TOPS。主要对片上BRAM使用较多,这也是矩阵计算中受到限制的重要因素,因为通常限制计算的都是片上缓存以及带宽。
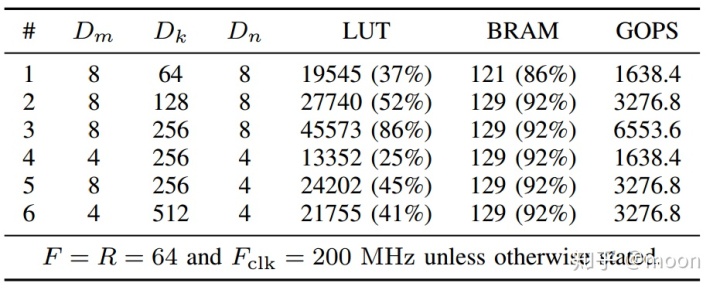
图3.2 资源利用
还有功耗估计如图3.3所示。
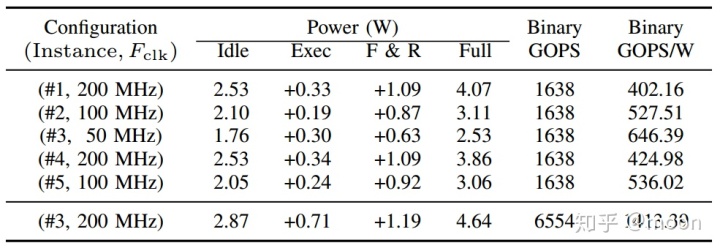
图3.3 功耗
总结
论文提出了一种可变位宽的计算矩阵乘法的方法,通过串行计算乘法来实现。这对于大规模矩阵乘计算比较有优势,但是对于较小矩阵或者数据位宽较大的乘法来说,效率会比较差。所以这种方法就当做是提供了一种可变bit乘法的思路。
文献
1. Yaman Umuroglu, L.R., Magnus Sjalander, BISMO: A Scalable Bit-Serial Matrix Multiplication Overlay for Reconfigurable Computing. arXiv preprint, 2018. 18
往期回顾
1. 在DNN中FPGA做了什么?
2. 稀疏LSTM硬件架构















 2569
2569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









