






01 什么是Hive
在关系数据库中,我们创建一张表,我们会指定表名称、列名称、列的类型、这些是表的Schema,而HDFS,文件仅仅是一个文件,他没有Schema,我们没有办法通过SQL的方式对HDFS上的数据进行查询。这时我们要对HDFS上的大数据进行处理的话,我们需要通过MapReduce进行处理。通过前面MapReduce的文章我们可以知道,MapReduce是Hadoop生态中的一个离线计算框架,通过他我们可以将HDFS中存储的文件数据进行解析、运算,并得到想要分析的统计分析结果。在通过MapReduce进行统计计算的时候,我们需要通过Java、MapReduce进行编程,定义Map、Reduce函数,定义统计计算方式等等,这都需要进行大量的编程,学习门槛较高,并且需要花费更多的时间。
Hive,提供了一种通过SQL语句的方式,让程序员可以像操作关系数据库一样,操作HDFS中的数据,并通过MapReduce或者其他方式对数据进行统计分析。
Hive,是一个建立在HDFS、MapReduce基础上的数据仓库工具。现在,除了MapReduce,Hive还支持不同的执行引擎,如Spark、Tez。
02 Hive的好处
Hive的好处,一是上面所说的,可以通过类SQL语句的方式,降低开发成本和代价,并且可以支持不同的计算执行引擎:Hive on MapReduce、Hive on Tez、Hive on Spark。二是他提供了统一的元数据管理。
2.1 统一的元数据管理
元数据是什么在前面的文章中介绍过,这里不再赘述。我们这里可以简单再认识一下,对于Hive中的一张表,他的表名称是什么、对应的数据库是哪个、这个表里包括什么字段、每列是什么、每列对应的数据类型又是什么、表分隔符是什么等等,这些都是这个表的元数据,元数据是描述数据(数据库表)的数据。
Hive提供的元数据统一管理,可以让你在Hive中创建的表,在Presto、impala、SparkSql中直接使用,同样的在Presto、impala、SparkSql中创建的表,也可以在Hive中使用。
03 Hive的构成
Hive主要由三个模块构成:用户接口模块、驱动模块和元数据存储模块。
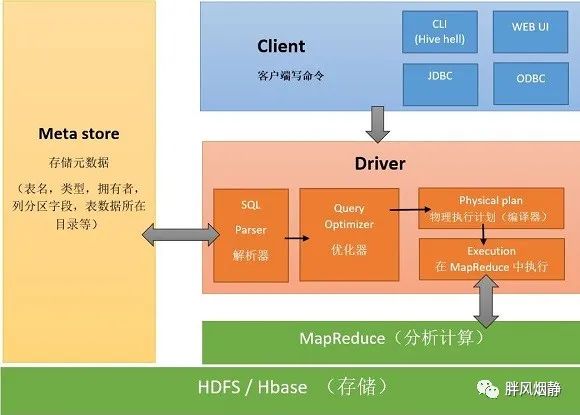
3.1 用户接口模块
Hive支持通过命令行,或者通过Thrift协议按照编译JDBC的方式来完成对Hive 中数据的操作。对于命令行方式,Hive自带有命令行界面CLI,也有一个简单的网页界面HWI;JDBC、ODBC以及Thtift Server可向用户提供进行编程的接口,其中Thrift Server是基于Thrift软件框架开发的,提供Hive的RPC通信接口。
3.2 驱动模块 Driver
驱动模块包括编译器、优化器、执行器,负责把HiveQL语句转化为一系列MR作业。
SQL语句仅仅是一段普通的字符串,想把这段字符串转换成执行任务,需要经过很多步骤。SQL Parse把语句解析成抽象语法树,到这一步后会生成逻辑性执行计划。查询优化工具Query Optimizer会对逻辑性执行计划进行优化。
Hive把HQL语句转化为MR任务的步骤:
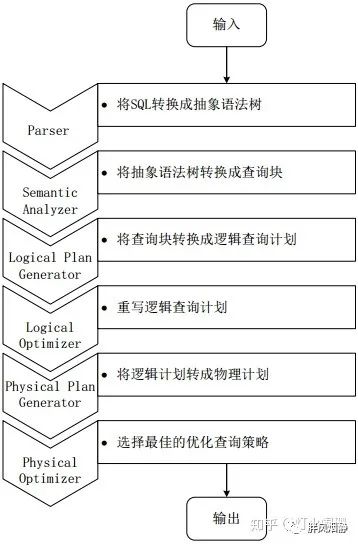
Step 1:
驱动模块中的编译器-Antrl语言识别工具,对用户输入的SQL语句进行词法和语法解析,将HQL语句转化为抽象语法树(AST Tree)的形式;
Step 2:
遍历抽象语法树,转化为QueryBlock查询单元,因为AST结构复杂,不便直接翻译成MR算法程序。其中QueryBlock是一条最基本的SQL语法组成单元,包括输入源、计算过程和输出三个部分;
Step 3:
遍历QueryBlock,生成OperatorTree(操作树),OperatorTree由很多逻辑操作符组成,如TableScanOperator、SelectOperator、FilterOperator、JoinOperator、GroupByOperator和ReduceSinkOperator等。这些逻辑操作符可在Map、Reduce阶段完成某一特定操作;
Step 4:
逻辑优化器对OperatorTree进行优化,变换OperatorTree的形式,合并多余的操作符,减少MR任务树以及Shuffle阶段的数据量;
Step 5:
遍历优化后的OperatorTree,根据其中的逻辑操作符生成需要执行的MR任务;
Step 6:
启动Hive中的物理优化器对生成的MR任务进行优化,生成最终的MR执行任务;
Step 7:
最后,由Hive驱动模块中的执行器,对最终的MR任务执行输出。
Hive驱动模块中的执行器执行最终的MR任务时,Hive本身不会生成MR算法程序。它通过一个表示“Job执行计划”的XML文件,来驱动内置的、原生的Mapper和Reducer模块。Hive通过和JobTracker通信来初始化MR任务,而不需直接部署在JobTracker所在管理节点上执行。通常在大型集群中,会有专门的网关机来部署Hive工具,这些网关机的作用主要是远程操作和管理节点上的JobTracker通信来执行任务。Hive要处理的数据文件常存储在HDFS上,HDFS由名称节点(NameNode)来管理。
3.3 元数据存储模块 MetaStore
MetaStore是一个独立的关系数据库,Hive自带一个Derby数据库实例,但是Derby只支持单用户访问,因此一般我们通过与MySQL数据库连接后创建一个MySQL实例进行元数据存储。
04 Hive工作原理示例
4.1 用MR实现连接操作
假设连接(join)的两个表分别是用户表User(uid,name)和订单表Order(uid,orderid),具体的SQL命令:
SELECT name, orderid FROM User u JOIN Order o ON u.uid=o.uid;
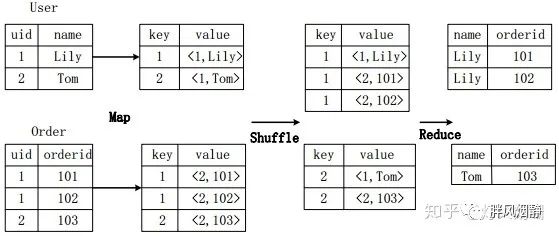
上图描述了连接操作转换为MapReduce操作任务的具体执行过程。首先,在Map阶段,
User表以uid为key,以name和表的标记位(这里User的标记位记为1)为value,进行Map操作,把表中记录转换生成一系列KV对的形式。比如,User表中记录(1,Lily)转换为键值对(1,<1,Lily>),其中第一个“1”是uid的值,第二个“1”是表User的标记位,用来标示这个键值对来自User表;
同样,Order表以uid为key,以orderid和表的标记位(这里表Order的标记位记为2)为值进行Map操作,把表中的记录转换生成一系列KV对的形式;
接着,在Shuffle阶段,把User表和Order表生成的KV对按键值进行Hash,然后传送给对应的Reduce机器执行。比如KV对(1,<1,Lily>)、(1,<2,101>)、(1,<2,102>)传送到同一台Reduce机器上。当Reduce机器接收到这些KV对时,还需按表的标记位对这些键值对进行排序,以优化连接操作;
最后,在Reduce阶段,对同一台Reduce机器上的键值对,根据“值”(value)中的表标记位,对来自表User和Order的数据进行笛卡尔积连接操作,以生成最终的结果。比如键值对(1,<1,Lily>)与键值对(1,<2,101>)、(1,<2,102>)的连接结果是(Lily,101)、(Lily,102)。
4.2 用MR实现分组操作
假设分数表Score(rank, level),具有rank(排名)和level(级别)两个属性,需要进行一个分组(Group By)操作,功能是把表Score的不同片段按照rank和level的组合值进行合并,并计算不同的组合值有几条记录。SQL语句命令如下:
SELECT rank,level,count(*) as value FROM score GROUP BY rank,level;
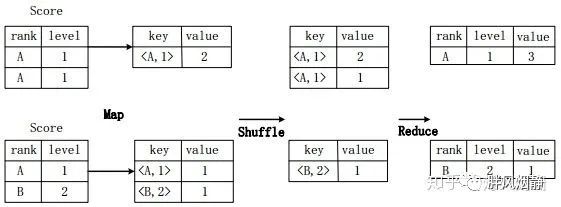
上图描述分组操作转化为MapReduce任务的具体执行过程。
首先,在Map阶段,对表Score进行Map操作,生成一系列KV对,其键为,值为“拥有该组合值的记录的条数”。比如,Score表的第一片段中有两条记录(A,1),所以进行Map操作后,转化为键值对(,2);
接着在Shuffle阶段,对Score表生成的键值对,按照“键”的值进行Hash,然后根据Hash结果传送给对应的Reduce机器去执行。比如,键值对(,2)、(,1)传送到同一台Reduce机器上,键值对(,1)传送另一Reduce机器上。然后,Reduce机器对接收到的这些键值对,按“键”的值进行排序;
在Reduce阶段,把具有相同键的所有键值对的“值”进行累加,生成分组的最终结果。比如,在同一台Reduce机器上的键值对(,2)和(,1)Reduce操作后的输出结果为(A,1,3)。
05 用Hive构建数据仓库
5.1 创建表
Hive建表方式共有三种:直接建表法、查询建表法、Like建表法。
5.1.1 直接建表法
直接建表法,是用户直接通过建表语句建立新表,先看两个例子;
例1:
CREATE EXTERNAL TABLE IF NOT EXISTS `t1`(
id int,
name string,
hobby array,
add map)
ROW FORMAT delimited fields terminated by ‘,'
collection items terminated by '-'
map keys terminated by ‘:';
例2:
CREATE TABLE test_1(id int, name string, pid int, price int)
ROW FORMAT delimited fields terminated by ‘\t
stored as textFile ;
里面有一些建表语句和关系数据库一样,不再赘述,我们来看一下与关系数据库不同的部分。
1)Row Format
Hive将HDFS上的文件映射成表结构,通过分隔符来区分列(比如’,’ ‘;’ or ‘^’ 等),Row Format就是用于指定序列化和反序列化的规则。
比如对于以下记录:
1,xiaoming,book-TV-code,beijing:chaoyang-shagnhai:pudong
2,lilei,book-code,nanjing:jiangning-taiwan:taibei
3,lihua,music-book,heilongjiang:haerbin
对应ID、name、hobby(数组形式,COLLECTION ITEMS TERMINATED BY char)、address(键值对形式map,MAP KEYS TERMINATED BY char)),而LINES TERMINATED BY char 用于区分不同条的数据,默认是换行符;
2)External
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table);
区别:
内部表数据由Hive自身管理,外部表数据由HDFS管理;
内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定;
删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
3)File Format(HDFS文件存放的格式)
stored as指定文件的存储格式,Hive中提供两种文件格式:SEQUENCEFILE和TEXTFILE,序列文件是一种压缩的格式,通常可以提供更高的性能。
如果文件数据是纯文本,可以使用 stored as textFile,默认也是 textFile 格式。
5.1.2 查询建表法
通过AS 查询语句完成建表:把一张表的某些字段抽取出来,创建成一张新表;
例如:
CREATE TABLE new_key_value_store
ROW FORMAT SERDE “org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe"
STORED AS RCFile
AS
SELECT (key % 1024) new_key, concat(key, value) key_value_pair
FROM key_value_store
SORT BY new_key, key_value_pair;
其中,
as只会复制属性以及属性值到新的表中
使用as创建的表,并不会带原表的分区(分区丢失),包括一些字段的约束等(可以通过describe formatted查看)
新表中会将原表的分区当做字段出现在新表中。
5.1.3 Like建表法
会创建结构完全相同的表,但是没有数据。
例如:
CREATE TABLE empty_key_value_store
LIKE key_value_store;
5.2 加载数据
1)加载本地文件
load data local inpath '/home/username/test1.txt' into table test1;
关键字[LOCAL]是指你加载文件的来源为本地文件,否则根据 inpath 中的 uri 查找文件即hdfs的文件。
2)加载指定位置的文件
load data inpath '/user/username/databasename/user_log_1/*' into table user_log_1;
根据 inpath 中的 uri 查找文件(hdfs的文件)
延伸阅读:抽象语法树
1.1 什么是抽象语法树
抽象语法树(AST)或语法树是用编程语言编写的源代码的抽象语法结构的树表示。树的每个节点表示在源代码中出现的构造。语法是“抽象的”,因为它不代表真实语法中出现的每个细节,而只是结构,内容相关的细节。
抽象语法树用于程序分析和程序转换系统。
1.2 抽象语法树的特点
1.2.1 不依赖于具体的文法
无论是LL(1)文法,还是LR(1),或者还是其它的方法,都要求在语法分析时候,构造出相同的语法树,这样可以给编译器后端提供了清晰,统一的接口。即使是前端采用了不同的文法,都只需要改变前端代码,而不用连累到后端。即减少了工作量,也提高的编译器的可维护性。
1.2.2 不依赖于语言的细节
在编译器家族中,大名鼎鼎的GCC算得上是一个老大哥了,它可以编译多种语言,例如c,c++,java,ADA,Object C, FORTRAN, PASCAL, COBOL等等。在前端gcc对不同的语言进行词法,语法分析和语义分析后,产生抽象语法树形成中间代码作为输出,供后端处理。要做到这一点,就必须在构造语法树时,不依赖于语言的细节,例如在不同的语言中,类似于if-condition-then这样的语句有不同的表示方法。但在抽象语法树中,构造if-condition-then语句的抽象语法树时,只需要用两个分支节点来表于,一个为condition,一个为if_body。















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









