






原地址:https://www.cnblogs.com/blfshiye/p/5059748.html
https://www.2cto.com/database/201607/524821.html
数据库经常是我们存储和訪问数据的经常使用介质。随着负载的增大,对数据库读写性能的要求往往成为非常大的挑战。在这种情况下我们能够考虑数据库相关的replication机制提高读写的性能。因为一般採用一写多读的replication机制(写master同步到多个slaves),导致这种机制往往会有缺陷。首先它依赖于读写的比例,假设写的操作过多,导致master往往成为性能的瓶颈所在,从而使得slaves的数据同步延迟也变大,进而大大消耗CPU的资源,而且导致数据的不一致从而影响到用户的体验。
这个时候我们就要考虑使用数据库的sharding(分片)机制,这里面我们所说sharding机制并非一个数据库软件的附属功能,而是一种相对简朴的软件理念。
一般我们把sharding机制分成水平扩展(横向扩展,或者向外扩展)和垂直扩展两种方式。
详细什么是数据库的水平扩展和垂直扩展呢?我们以以下的样例来说明。
比方我们如今有两个表:用户信息表 产品订单表
水平的拆分的方案,即不改动数据库表结构。通过对表中数据的拆分而达到分片的目的:
1)使用用户id做hash,分解数据库,在訪问数据库的使用用户id做路由。
2)将产品订单表依照已下单和未下单区分成两个表。
一般水平拆分在查询数据库的时候可能会用到union操作。
垂直拆分的方案:将表和表分离,或者改动表结构,依照訪问的差异将某些列拆分出去。
1)将用户信息表放到一个数据库server,将产品订单表放到一个数据库server。
2)将用户信息表中主码(通常是user id)和一些经常使用的信息放到一个表,将主码和不经常使用的信息放到另外的表。这导致一般查询数据的时候可能会用到join操作。
在数据库的设计中,我们更关注数据库的水平扩展的能力。
一、数据库水平扩展
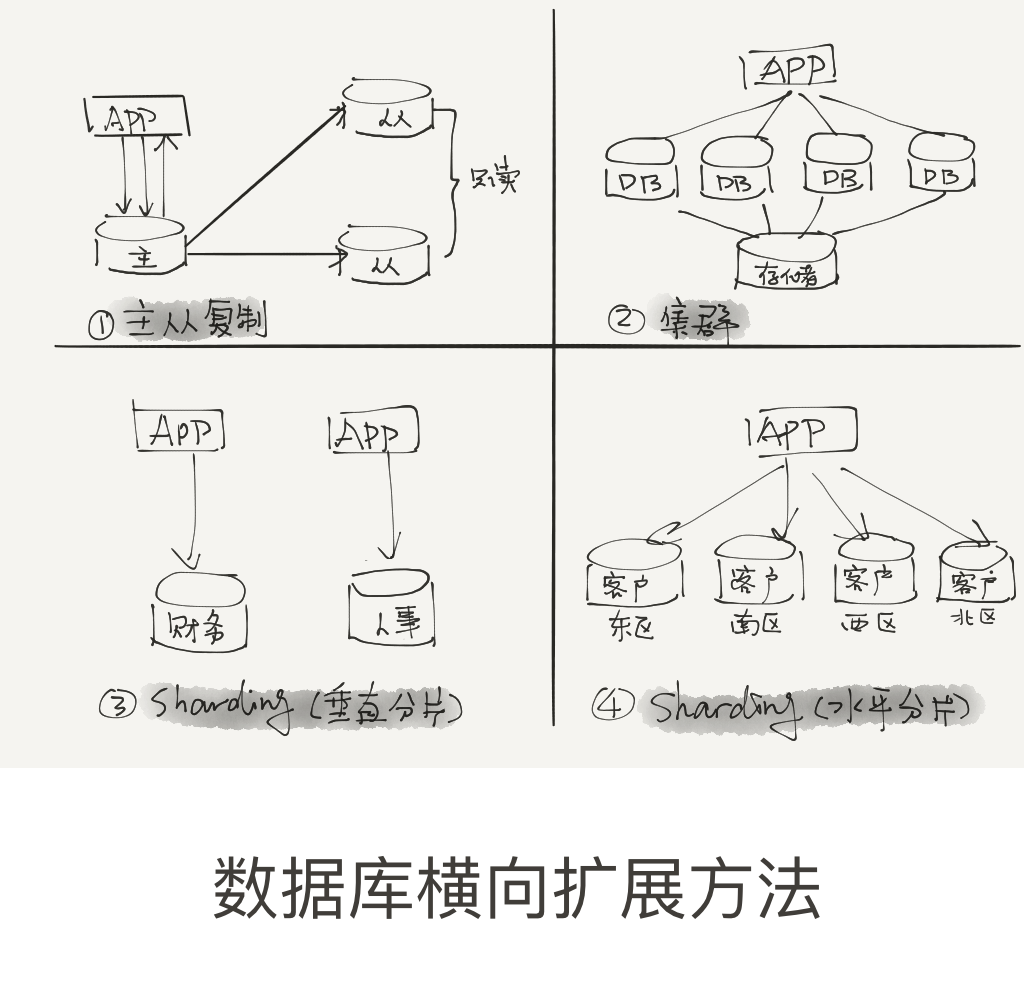
数据库的横向扩展支持三种方法,即主从复制,集群和分片(sharding)。
主从复制
主从复制(Master-slave replication),最易配置,对应用改动最小,并可以减轻主库的负担。
主数据库可以读写,从数据库只读。最常用的场景就是实现读写分离,或业务分离,即运行报表,备份,数据仓库等应用。
这种方法的问题是主与从之间数据非完全同步,可能会读到两个不同的版本。另一个问题是,如果只有主库接受读写,那么主库迟早会过载,因此不算是真正的scale out。
不过主从库数据的延迟,有的业务是可以接受的。另外,利用一些实时复制的工具如GoldenGate,从库也是可以写的,这时可以利用从库做其它的业务,从而达到横向扩展的目的。这也算是主从复制的一个新趋势。
集群(Clustering)
集群也称为shared everything或shared disk架构。最知名的就是Oracle RAC。
1个数据库可以有多个实例,来访问共享存储上的数据库。
每一个节点都可以读写,从应用角度来看,代码无需改变。负载均衡也是自动的。
集群存在的问题包括:
* 写数据时需要内存中数据的同步,数据加速带来竞争,影响扩展性
* 难以设置和管理
* 由于存储是共享的,读操作也不能无限扩展
集群适合于读密集的应用,如数据仓库和BI。
分片(Sharding)
分区(Partition)是库内的,分片(Sharding)是库外的,也叫分表分库, 是shared nothing的架构。
Sharding即将一个大的库拆分成很多小库。如何拆和业务规则有关,可以按用户ID拆,按业务拆。如果需要Join,相关的表需要放到一个库里,避免数据库间的通讯。
Sharding也可以有两种方法,即垂直分区和水平分区。
垂直分区是按业务分,简称为分库,即不同的业务使用不同的库,互不相干。垂直分区到一定程度,也无法扩展,这时需要水平分区。
水平分区则是将一个大表拆分为小表,每个小表位于不同的库。每一个建立相同的schema。如根据主键的hash值来分区。
sharding的不足在于:
* 加大了应用代码的复杂性,需要路由到正确的shard。
* 后期增加shard需要修改应用逻辑,并需要迁移数据
* 查询和聚集(aggregation)不再简单,需要跨库联合操作
* 主数据和参照数据需要复制到所有shard,以避免跨库操作。主数据和参照数据虽然偏静态,但一旦修改,可能会有数据一致性问题。
* 跨库修改需要分布式交易处理,会限制可扩展性。因此应尽量避免。
* 单个shard的失效可能会使整个系统不可用(其实也不一定)。因此通常需要为每个shard再配置HA方案,如主从复制。
主从复制
主从复制(Master-slave replication),最易配置,对应用改动最小,并可以减轻主库的负担。
主数据库可以读写,从数据库只读。最常用的场景就是实现读写分离,或业务分离,即运行报表,备份,数据仓库等应用。
这种方法的问题是主与从之间数据非完全同步,可能会读到两个不同的版本。另一个问题是,如果只有主库接受读写,那么主库迟早会过载,因此不算是真正的scale out。
不过主从库数据的延迟,有的业务是可以接受的。另外,利用一些实时复制的工具如GoldenGate,从库也是可以写的,这时可以利用从库做其它的业务,从而达到横向扩展的目的。这也算是主从复制的一个新趋势。
集群(Clustering)
集群也称为shared everything或shared disk架构。最知名的就是Oracle RAC。
1个数据库可以有多个实例,来访问共享存储上的数据库。
每一个节点都可以读写,从应用角度来看,代码无需改变。负载均衡也是自动的。
集群存在的问题包括:
* 写数据时需要内存中数据的同步,数据加速带来竞争,影响扩展性
* 难以设置和管理
* 由于存储是共享的,读操作也不能无限扩展
集群适合于读密集的应用,如数据仓库和BI。
分片(Sharding)
分区(Partition)是库内的,分片(Sharding)是库外的,也叫分表分库, 是shared nothing的架构。
Sharding即将一个大的库拆分成很多小库。如何拆和业务规则有关,可以按用户ID拆,按业务拆。如果需要Join,相关的表需要放到一个库里,避免数据库间的通讯。
Sharding也可以有两种方法,即垂直分区和水平分区。
垂直分区是按业务分,简称为分库,即不同的业务使用不同的库,互不相干。垂直分区到一定程度,也无法扩展,这时需要水平分区。
水平分区则是将一个大表拆分为小表,每个小表位于不同的库。每一个建立相同的schema。如根据主键的hash值来分区。
sharding的不足在于:
* 加大了应用代码的复杂性,需要路由到正确的shard。
* 后期增加shard需要修改应用逻辑,并需要迁移数据
* 查询和聚集(aggregation)不再简单,需要跨库联合操作
* 主数据和参照数据需要复制到所有shard,以避免跨库操作。主数据和参照数据虽然偏静态,但一旦修改,可能会有数据一致性问题。
* 跨库修改需要分布式交易处理,会限制可扩展性。因此应尽量避免。
* 单个shard的失效可能会使整个系统不可用(其实也不一定)。因此通常需要为每个shard再配置HA方案,如主从复制。















 641
641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









