





本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
以下文章来源于腾讯云 作者:py3study
本文目标
获取 Ajax 请求,解析 JSON 中所需字段
数据保存到 Excel 中
数据保存到 MySQL, 方便分析
简单分析
五个城市 Python 岗位平均薪资水平

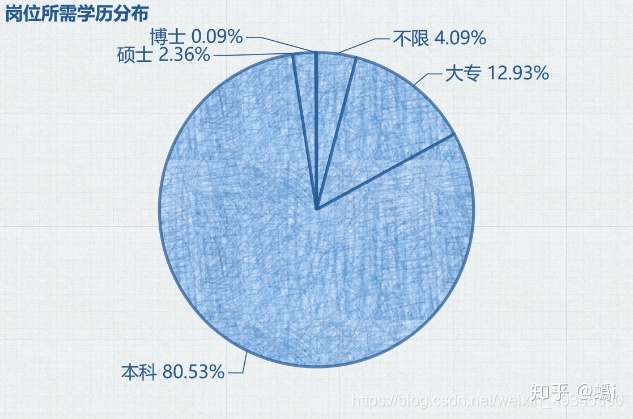
Python 岗位要求学历分布
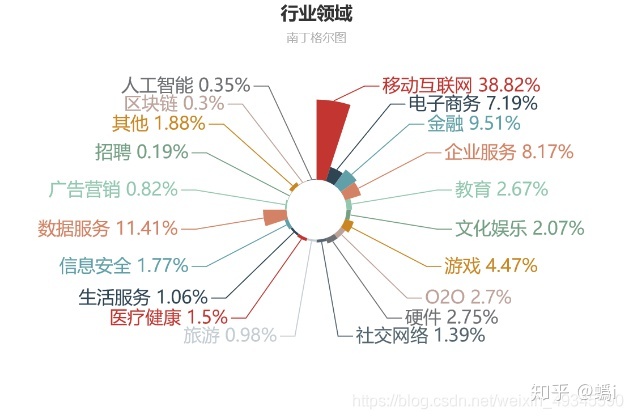
Python 行业领域分布
Python 公司规模分布

查看页面结构
我们输入查询条件以 Python 为例,其他条件默认不选,点击查询,就能看到所有 Python 的岗位了,然后我们打开控制台,点击网络标签可以看到如下请求:
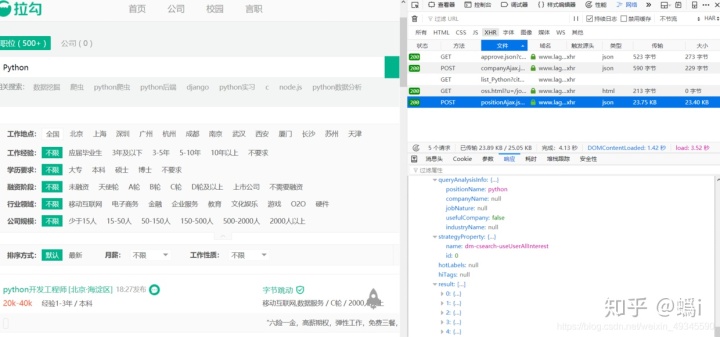
从响应结果来看,这个请求正是我们需要的内容。后面我们直接请求这个地址就好了。从图中可以看出 result 下面就是各个岗位信息。
到这里我们知道了从哪里请求数据,从哪里获取结果。但是 result 列表中只有第一页 15 条数据,其他页面数据怎么获取呢?
分析请求参数
我们点击参数选项卡,如下:
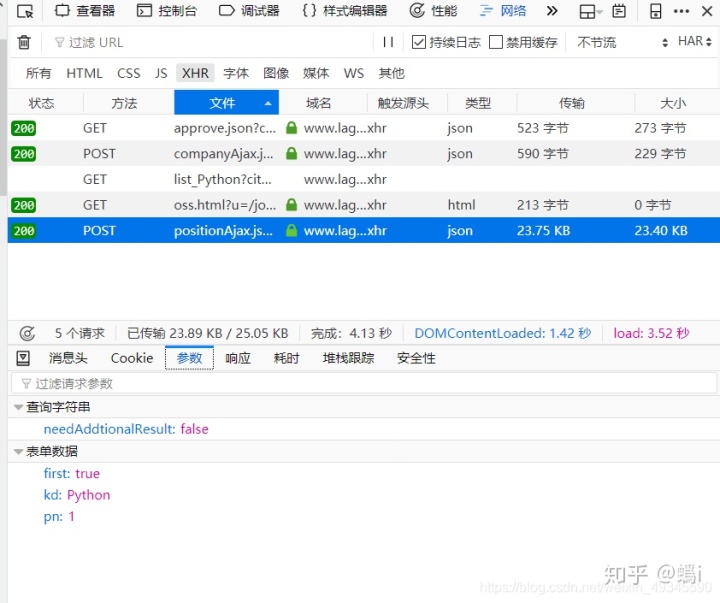
发现提交了三个表单数据,很明显看出来 kd 就是我们搜索的关键词,pn 就是当前页码。first 默认就行了,不用管它。剩下的事情就是构造请求,来下载 30 个页面的数据了。
构造请求,并解析数据
构造请求很简单,我们还是用 requests 库来搞定。首先我们构造出表单数据 data = {‘first’: ‘true’, ‘pn’: page, ‘kd’: lang_name} 之后用 requests 来请求url地址,解析得到的 Json 数据就算大功告成了。由于拉勾对爬虫限制比较严格,我们需要把浏览器中 headers 字段全部加上,而且把爬虫间隔调大一点,我后面设置的为 10-20s,然后就能正常获取数据了。
import 获取所有数据
了解了如何解析数据,剩下的就是连续请求所有页面了,我们构造一个函数来请求所有 30 页的数据。
def 完整代码
import 














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









