






准备
要执行Map reduce程序,首先得安装hadoop,hadoop安装可以参考hadoop安装
启动hdfs和yarn
start-dfs.cmdstart-yarn.cmd
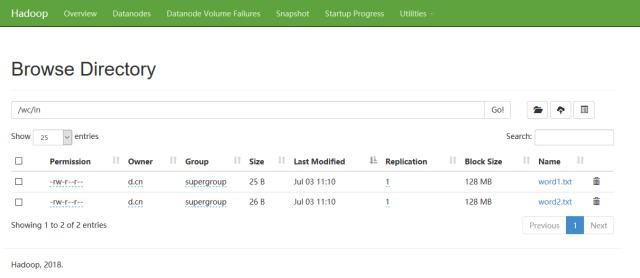
创建待处理数据目录:
hadoop fs -mkdir /wchadoop fs -mkdir /wc/in# 查看目录hadoop fs -ls -R /
上传待处理数据文件:
hadoop fs -put file:///G:\note\bigdata\hadoop\wordcount\word1.txt /wc/inhadoop fs -put file:///G:\note\bigdata\hadoop\wordcount\word2.txt /wc/in
其中数据文件内容如下: word1.txt
hello worldhello hadoop
word2.txt
hadoop worldhadoop learn
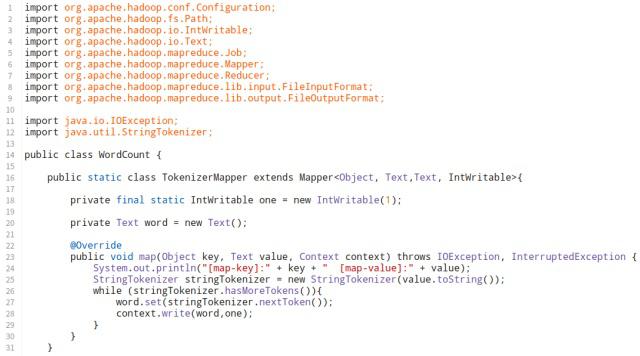
WordCount与Map Reduce流程
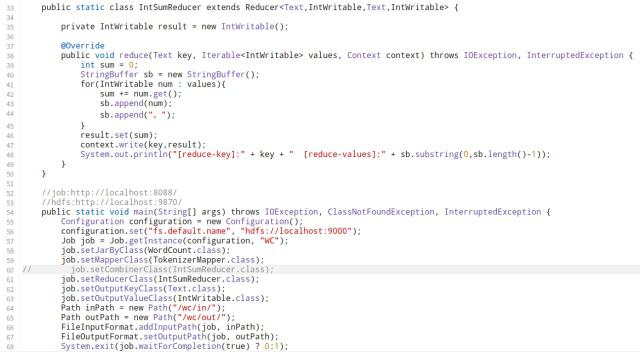

如果输出目录已经存在,可以使用下面的命令删除:
hadoop fs -rm -r /wc/out
我们先来看一下程序的输出:
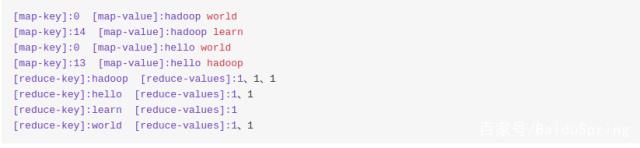
从输出我们可以推测hadoop的map过程是:hadoop把待处理的文件按行拆分,每一行调用map函数,map函数的key就是每一行的起始位置,值就是这一行的值。
map处理之后,再按key-value的形式写中间值。
reduce函数就是处理这些中间过程,参数的key就是map写入的key,value就是,map之后按key分组的value。
Combin过程
再Map和Reduce中间还可以加入Combin过程,用于处理中间结果,减少网络间数据传输的数据量。
Map->Reduce->Combin
我们把上面程序中job.setCombinerClass(IntSumReducer.class);注释去掉就可以获取到有Combiner的输出:
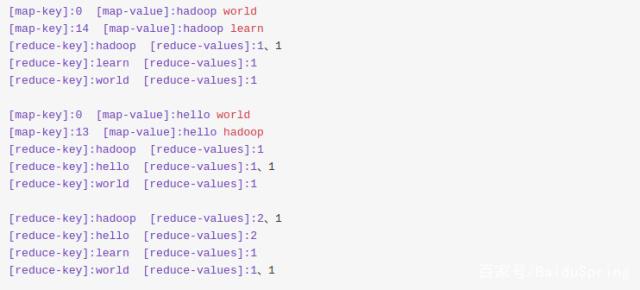
从上面的输出我们可以看到,map之后有一个reduce输出,其实是combin操作,combin和reduce的区别是combin是在单节点内部执行的,为了减小中间数据。
注意:combin操作必须满足结合律,例如:
加法,求总和:a+b+c+d = (a+b) + (c+d)最大值:max(a+b+c+d) = max(max(a,b),max(c,d))均值就不能使用combin操作: (a+b+c+d)/4 明显不等价于 ((a+b)/2 + (c+d)/2)/2
pom文件
















 1785
1785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









