





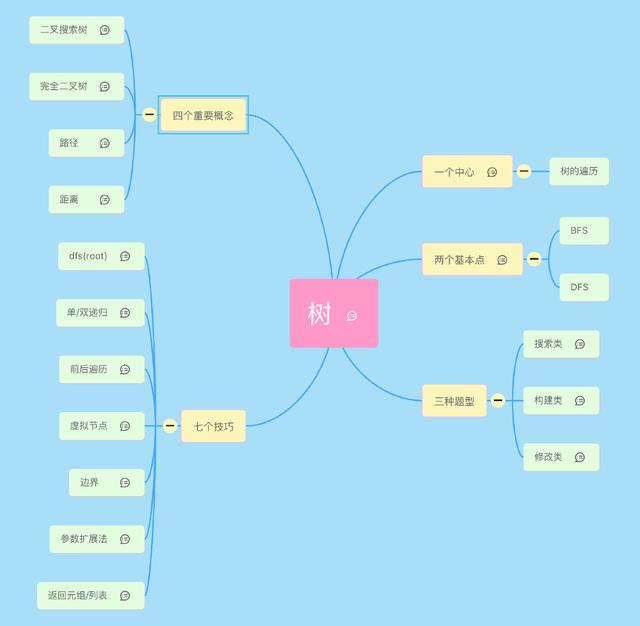
先上下本文的提纲,这个是我用 mindmap 画的一个脑图,之后我会继续完善,将其他专题逐步完善起来。
❝
大家也可以使用 vscode blink-mind 打开源文件查看,里面有一些笔记可以点开查看。源文件可以去我的公众号《力扣加加》回复脑图获取,以后脑图也会持续更新更多内容。vscode 插件地址:https://marketplace.visualstudio.com/items?itemName=awehook.vscode-blink-mind
❞
本系列包含以下专题:
- 几乎刷完了力扣所有的链表题,我发现了这些东西。。。
- 几乎刷完了力扣所有的树题,我发现了这些东西。。。(就是本文)
一点絮叨
首先亮一下本文的主角 - 树(我的化妆技术还行吧^_^):

树标签[1]在 leetcode 一共有 「175 道题」。 为了准备这个专题,我花了几天时间将 leetcode 几乎所有的树题目都刷了一遍。
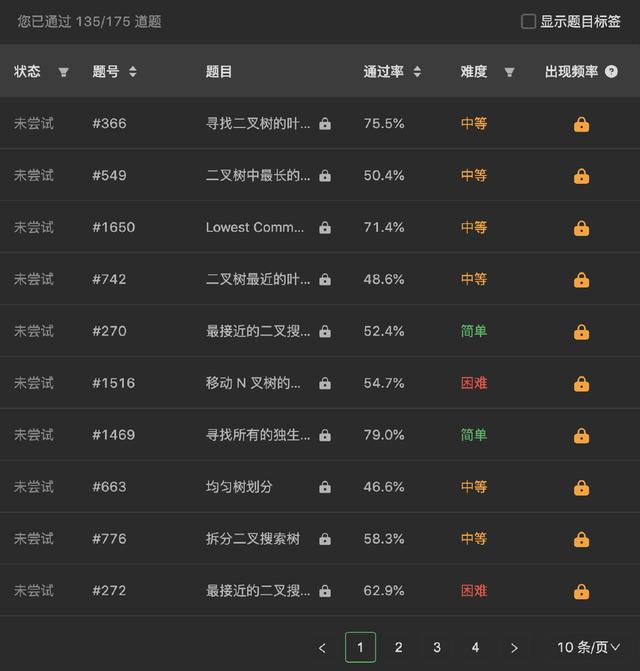
除了 35 个上锁的,1 个不能做的题(1628 题不知道为啥做不了), 4 个标着树的标签但却是图的题目,其他我都刷了一遍。通过集中刷这些题,我发现了一些有趣的信息,今天就分享给大家。
食用指南
大家好,我是 lucifer。今天给大家带来的是《树》专题。另外为了保持章节的聚焦性和实用性,省去了一些内容,比如哈夫曼树,前缀树,平衡二叉树(红黑树等),二叉堆。这些内容相对来说实用性没有那么强,如果大家对这些内容也感兴趣,可以关注下我的仓库 leetcode 算法题解[2],大家有想看的内容也可以留言告诉我哦~
另外要提前告知大家的是本文所讲的很多内容都很依赖于递归。关于递归的练习我推荐大家把递归过程画到纸上,手动代入几次。等大脑熟悉了递归之后就不用这么辛苦了。 实在懒得画图的同学也可以找一个可视化递归的网站,比如 https://recursion.now.sh/。 等你对递归有了一定的理解之后就仔细研究一下树的各种遍历方法,再把本文看完,最后把文章末尾的题目做一做,搞定个递归问题不大。
❝
文章的后面《两个基本点 - 深度优先遍历》部分,对于如何练习树的遍历的递归思维我也提出了一种方法
❞
最后要强调的是,本文只是帮助你搞定树题目的常见套路,但不是说树的所有题目涉及的考点都讲。比如树状 DP 这种不在本文的讨论范围,因为这种题更侧重的是 DP,如果你不懂 DP 多半是做不出来的,你需要的是学完树和 DP 之后再去学树状 DP。如果你对这些内容感兴趣,可以期待我的后续专题。
前言
提到树大家更熟悉的是现实中的树,而现实中的树是这样的:

而计算机中的树其实是现实中的树的倒影。

计算机的数据结构是对现实世界物体间关系的一种抽象。比如家族的族谱,公司架构中的人员组织关系,电脑中的文件夹结构,html 渲染的 dom 结构等等,这些有层次关系的结构在计算机领域都叫做树。
首先明确一下,树其实是一种逻辑结构。比如笔者平时写复杂递归的时候,尽管笔者做的题目不是树,也会画一个递归树帮助自己理解。
❝
树是一种重要的思维工具
❞
以最简单的计算 fibonacci 数列为例:
function fn(n) { if (n == 0 || n == 1) return n; return fn(n - 1) + fn(n - 2);}很明显它的入参和返回值都不是树,但是却不影响我们用树的思维去思考。
继续回到上面的代码,根据上面的代码可以画出如下的递归树。
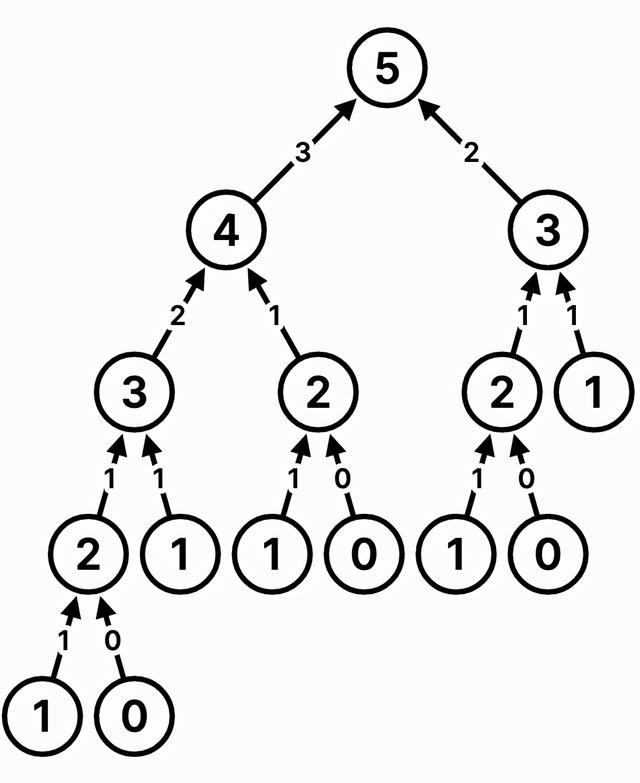
其中树的边表示的是返回值,树节点表示的是需要计算的值,即 fn(n)。
以计算 5 的 fibbonacci 为例,过程大概是这样的(动图演示):

「这其实就是一个树的后序遍历」,你说树(逻辑上的树)是不是很重要?关于后序遍历咱们后面再讲,现在大家知道是这么回事就行。
大家也可以去 这个网站[3] 查看上面算法的单步执行效果。当然这个网站还有更多的算法的动画演示。
❝
上面的图箭头方向是为了方便大家理解。其实箭头方向变成向下的才是真的树结构。
❞
广义的树真的很有用,但是它范围太大了。 本文所讲的树的题目是比较狭隘的树,指的是输入(参数)或者输出(返回值)是树结构的题目。
基本概念
❝
树的基本概念难度都不大,为了节省篇幅,我这里简单过一下。对于你不熟悉的点,大家自行去查找一下相关资料。我相信大家也不是来看这些的,大家应该想看一些不一样的东西,比如说一些做题的套路。
❞
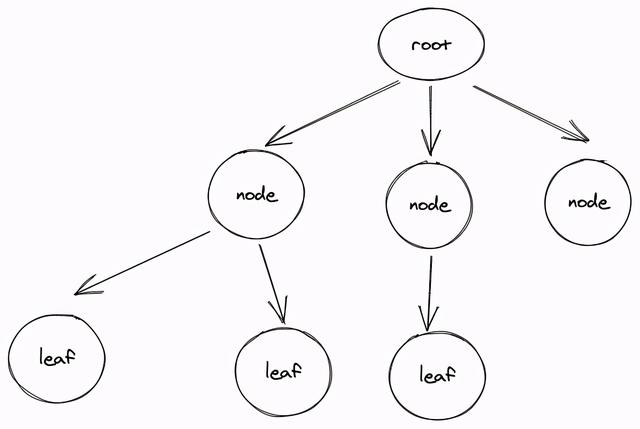
树是一种非线性数据结构。树结构的基本单位是节点。节点之间的链接,称为分支(branch)。节点与分支形成树状,结构的开端,称为根(root),或根结点。根节点之外的节点,称为子节点(child)。没有链接到其他子节点的节点,称为叶节点(leaf)。如下图是一个典型的树结构:
每个节点可以用以下数据结构来表示:
Node { value: any; // 当前节点的值 children: Array; // 指向其儿子}其他重要概念:
- 树的高度:节点到叶子节点的最大值就是其高度。
- 树的深度:高度和深度是相反的,高度是从下往上数,深度是从上往下。因此根节点的深度和叶子节点的高度是 0。
- 树的层:根开始定义,根为第一层,根的孩子为第二层。
- 二叉树,三叉树,。。。 N 叉树,由其子节点最多可以有几个决定,最多有 N 个就是 N 叉树。
二叉树
二叉树是树结构的一种,两个叉就是说每个节点「最多」只有两个子节点,我们习惯称之为左节点和右节点。
❝
注意这个只是名字而已,并不是实际位置上的左右
❞
二叉树也是我们做算法题最常见的一种树,因此我们花大篇幅介绍它,大家也要花大量时间重点掌握。
二叉树可以用以下数据结构表示:
Node { value: any; // 当前节点的值 left: Node | null; // 左儿子 right: Node | null; // 右儿子}二叉树分类
- 完全二叉树
- 满二叉树
- 二叉搜索树
- 平衡二叉树[4]
- 红黑树
- 。。。
二叉树的表示
- 链表存储
- 数组存储。非常适合完全二叉树
树题难度几何?
很多人觉得树是一个很难的专题。实际上,只要你掌握了诀窍,它并没那么难。
从官方的难度标签来看,树的题目处于困难难度的一共是 14 道, 这其中还有 1 个标着树的标签但是却是图的题目,因此困难率是 13 / 175 ,也就是 7.4 % 左右。如果排除上锁的 5 道,困难的只有 9 道。大多数困难题,相信你看完本节的内容,也可以做出来。
从通过率来看,只有「不到三分之一」的题目平均通过率在 50% 以下,其他(绝大多数的题目)通过率都是 50%以上。50% 是一个什么概念呢?这其实很高了。举个例子来说, BFS 的平均通过率差不多在 50%。 而大家认为比较难的二分法和动态规划的平均通过率差不多 40%。
大家不要对树有压力, 树和链表一样是相对容易的专题,今天 lucifer 给大家带来了一个口诀「一个中心,两个基本点,三种题型,四个重要概念,七个技巧」,帮助你克服树这个难关。
一个中心
一个中心指的是「树的遍历」。整个树的专题只有一个中心点,那就是树的遍历,大家务必牢牢记住。
不管是什么题目,核心就是树的遍历,这是一切的基础,不会树的遍历后面讲的都是白搭。
其实树的遍历的本质就是去把树里边儿的每个元素都访问一遍(任何数据结构的遍历不都是如此么?)。但怎么访问的?我不能直接访问叶子节点啊,我必须得从根节点开始访问,然后根据子节点指针访问子节点,但是子节点有多个(二叉树最多两个)方向,所以又有了先访问哪个的问题,这造成了不同的遍历方式。
❝
左右子节点的访问顺序通常不重要,极个别情况下会有一些微妙区别。比如说我们想要访问一棵树的最左下角节点,那么顺序就会产生影响,但这种题目会比较少一点。
❞
而遍历不是目的,遍历是为了更好地做处理,这里的处理包括搜索,修改树等。树虽然只能从根开始访问,但是我们可以「选择」在访问完毕回来的时候做处理,还是在访问回来之前做处理,这两种不同的方式就是「后序遍历」和「先序遍历」。
❝
关于具体的遍历,后面会给大家详细讲,现在只要知道这些遍历是怎么来的就行了。
❞
而树的遍历又可以分为两个基本类型,分别是深度优先遍历和广度优先遍历。这两种遍历方式并不是树特有的,但却伴随树的所有题目。值得注意的是,这两种遍历方式只是一种逻辑而已,因此理论可以应用于任何数据结构,比如 365. 水壶问题[5] 中,就可以对水壶的状态使用广度优先遍历,而水壶的状态可以用「一个二元组」来表示。
❝
遗憾的是这道题的广度优先遍历解法在 LeetCode 上提交会超时
❞
树的遍历迭代写法
很多小朋友表示二叉树前中后序的递归写法没问题,但是迭代就写不出来,问我有什么好的方法没有。
这里就给大家介绍一种写迭代遍历树的实操技巧,统一三种树的遍历方式,包你不会错,这个方法叫做双色标记法。 如果你会了这个技巧,那么你平时练习大可「只用递归」。然后面试的时候,真的要求用迭代或者是对性能有特别要求的那种题目,那你就用我的方法套就行了,下面我来详细讲一下这种方法。
我们知道垃圾回收算法中,有一种算法叫三色标记法。 即:
- 用白色表示尚未访问
- 灰色表示尚未完全访问子节点
- 黑色表示子节点全部访问
那么我们可以模仿其思想,使用双色标记法来统一三种遍历。
其核心思想如下:
- 使用颜色标记节点的状态,新节点为白色,已访问的节点为灰色。
- 如果遇到的节点为白色,则将其标记为灰色,然后将其右子节点、自身、左子节点依次入栈。
- 如果遇到的节点为灰色,则将节点的值输出。
使用这种方法实现的中序遍历如下:
class Solution: def inorderTraversal(self, root: TreeNode) -> List[int]: WHITE, GRAY = 0, 1 res = [] stack = [(WHITE, root)] while stack: color, node = stack.pop() if node is None: continue if color == WHITE: stack.append((WHITE, node.right)) stack.append((GRAY, node)) stack.append((WHITE, node.left)) else: res.append(node.val) return res可以看出,实现上 WHITE 就表示的是递归中的第一次进入过程,Gray 则表示递归中的从叶子节点返回的过程。 因此这种迭代的写法更接近递归写法的本质。
如要「实现前序、后序遍历,也只需要调整左右子节点的入栈顺序即可,其他部分是无需做任何变化」。
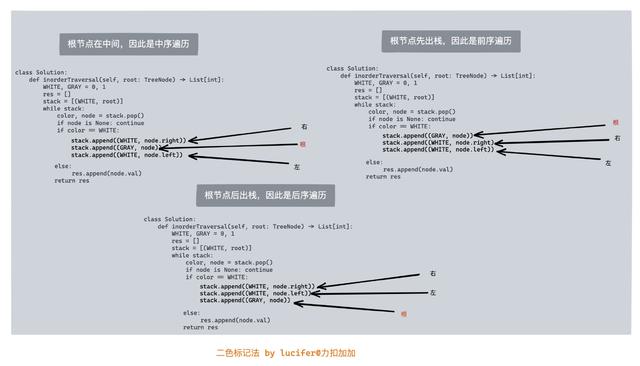
(前中后序遍历只需要调整这三句话的位置即可)
可以看出使用三色标记法,其写法类似递归的形式,因此便于记忆和书写。
有的同学可能会说,这里的每一个节点都会入栈出栈两次,相比普通的迭代入栈和出栈次数整整加了一倍,这性能可以接受么?我要说的是这种时间和空间的增加仅仅是常数项的增加,大多数情况并不会都程序造成太大的影响。 除了有时候比赛会比较恶心人,会「卡常」(卡常是指通过计算机原理相关的、与理论复杂度无关的方法对代码运行速度进行优化)。反过来看,大家写的代码大多数是递归,要知道递归由于内存栈的开销,性能通常比这里的二色标记法更差才对, 那为啥不用一次入栈的迭代呢?更极端一点,为啥大家不都用 morris 遍历 呢?
❝
morris 遍历 是可以在常数的空间复杂度完成树的遍历的一种算法。
❞
我认为在大多数情况下,大家对这种细小的差异可以不用太关注。另外如果这种遍历方式完全掌握了,再根据递归的思想去写一次入栈的迭代也不是难事。 无非就是调用函数的时候入栈,函数 return 时候出栈罢了。更多二叉树遍历的内容,大家也可以访问我之前写的专题《二叉树的遍历》[6]。
小结
简单总结一下,树的题目一个中心就是树的遍历。树的遍历分为两种,分别是深度优先遍历和广度优先遍历。关于树的不同深度优先遍历(前序,中序和后序遍历)的迭代写法是大多数人容易犯错的地方,因此我介绍了一种统一三种遍历的方法 - 二色标记法,这样大家以后写迭代的树的前中后序遍历就再也不用怕了。如果大家彻底熟悉了这种写法,再去记忆和练习一次入栈甚至是 Morris 遍历即可。
其实用一次入栈和出栈的迭代实现递归也很简单,无非就是还是用递归思想,只不过你把递归体放到循环里边而已。大家可以在熟悉递归之后再回头看看就容易理解了。树的深度遍历的递归技巧,我们会在后面的《两个基本点》部分讲解。
两个基本点
上面提到了树的遍历有两种基本方式,分别是「深度优先遍历(以下简称 DFS)和广度优先遍历(以下简称 BFS),这就是两个基本点」。这两种遍历方式下面又会细分几种方式。比如 「DFS 细分为前中后序遍历, BFS 细分为带层的和不带层的」。
「DFS 适合做一些暴力枚举的题目,DFS 如果借助函数调用栈,则可以轻松地使用递归来实现。」
BFS 不是 层次遍历
而 BFS 适合求最短距离,这个和层次遍历是不一样的,很多人搞混。这里强调一下,层次遍历和 BFS 是「完全不一样」的东西。
层次遍历就是一层层遍历树,按照树的层次顺序进行访问。
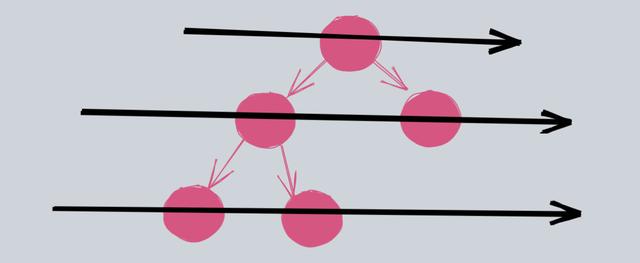
(层次遍历图示)
「BFS 的核心在于求最短问题时候可以提前终止,这才是它的核心价值,层次遍历是一种不需要提前终止的 BFS 的副产物」。这个提前终止不同于 DFS 的剪枝的提前终止,而是找到最近目标的提前终止。比如我要找距离最近的目标节点,BFS 找到目标节点就可以直接返回。而 DFS 要穷举所有可能才能找到最近的,这才是 BFS 的核心价值。实际上,我们也可以使用 DFS 实现层次遍历的效果,借助于递归,代码甚至会更简单。
❝
如果找到任意一个满足条件的节点就好了,不必最近的,那么 DFS 和 BFS 没有太大差别。同时为了书写简单,我通常会选择 DFS。
❞
以上就是两种遍历方式的简单介绍,下面我们对两者进行一个详细的讲解。
深度优先遍历
深度优先搜索算法(英语:Depth-First-Search,DFS)是一种用于遍历树或图的算法。沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点 v 的所在边都己被探寻过,搜索将回溯到发现节点 v 的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止,属于「盲目搜索」。
深度优先搜索是图论中的经典算法,利用深度优先搜索算法可以产生目标图的相应拓扑排序表,利用拓扑排序表可以方便的解决很多相关的图论问题,如最大路径问题等等。因发明「深度优先搜索算法」,约翰 · 霍普克洛夫特与罗伯特 · 塔扬在 1986 年共同获得计算机领域的最高奖:图灵奖。
截止目前(2020-02-21),深度优先遍历在 LeetCode 中的题目是 129 道。在 LeetCode 中的题型绝对是超级大户了。而对于树的题目,我们基本上都可以使用 DFS 来解决,甚至我们可以基于 DFS 来做层次遍历,而且由于 DFS 可以基于递归去做,因此算法会更简洁。 在对性能有很高要求的场合,我建议你使用迭代,否则尽量使用递归,不仅写起来简单快速,还不容易出错。
DFS 图解:
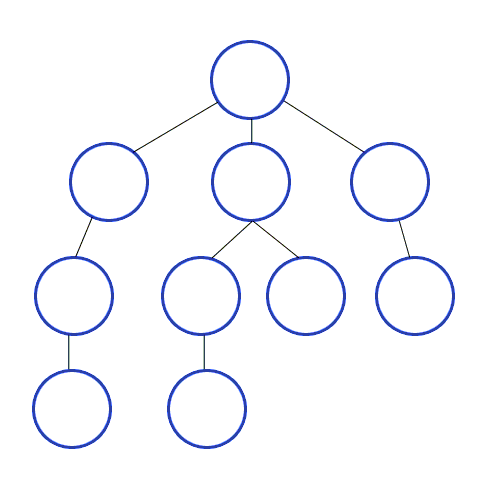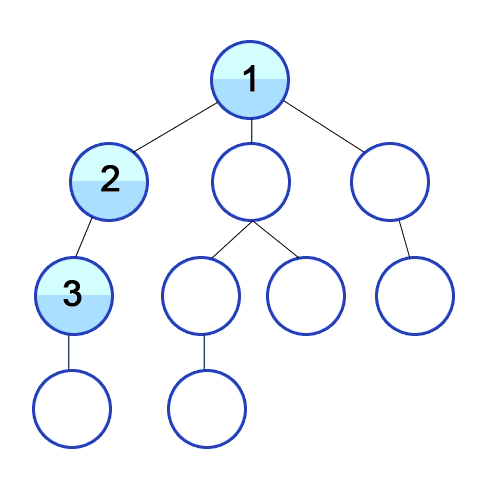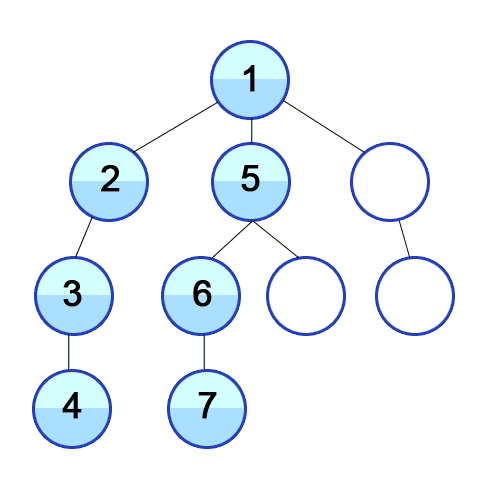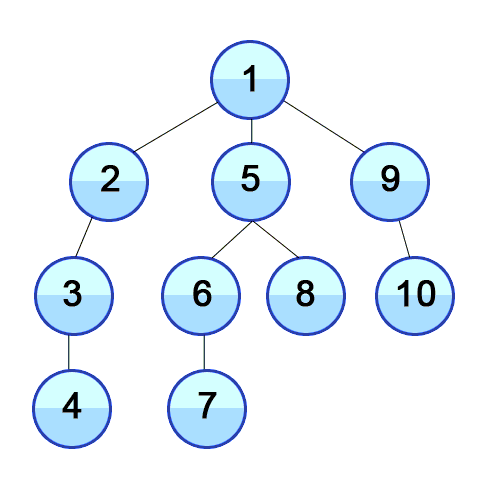
binary-tree-traversal-dfs
(图片来自 https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/tree/depth-first-search)
算法流程
- 首先将根节点放入「stack」中。
- 从stack中取出第一个节点,并检验它是否为目标。如果找到所有的节点,则结束搜寻并回传结果。否则将它某一个尚未检验过的直接子节点加入「stack」中。
- 重复步骤 2。
- 如果不存在未检测过的直接子节点。将上一级节点加入「stack」中。 重复步骤 2。
- 重复步骤 4。
- 若「stack」为空,表示整张图都检查过了——亦即图中没有欲搜寻的目标。结束搜寻并回传“找不到目标”。
「这里的 stack 可以理解为自己实现的栈,也可以理解为调用栈。如果是调用栈的时候就是递归,如果是自己实现的栈的话就是迭代。」
算法模板
一个典型的通用的 DFS 模板可能是这样的:
const visited = {}function dfs(i) { if (满足特定条件){ // 返回结果 or 退出搜索空间 } visited[i] = true // 将当前状态标为已搜索 for (根据i能到达的下个状态j) { if (!visited[j]) { // 如果状态j没有被搜索过 dfs(j) } }}上面的 visited 是为了防止由于环的存在造成的死循环的。 而我们知道树是不存在环的,因此树的题目大多数不需要 visited,除非你对树的结构做了修改,比如就左子树的 left 指针指向自身,此时会有环。再比如 138. 复制带随机指针的链表 这道题需要记录已经复制的节点,这些需要记录 visited 信息的树的题目「少之又少」。
因此一个树的 DFS 更多是:
function dfs(root) { if (满足特定条件){ // 返回结果 or 退出搜索空间 } for (const child of root.children) { dfs(child) }}而几乎所有的题目几乎都是二叉树,因此下面这个模板更常见。
function dfs(root) { if (满足特定条件){ // 返回结果 or 退出搜索空间 } dfs(root.left) dfs(root.right)}而我们不同的题目除了 if (满足特定条件部分不同之外),还会写一些特有的逻辑,这些逻辑写的位置不同,效果也截然不同。那么位置不同会有什么影响,什么时候应该写哪里呢?接下来,我们就聊聊两种常见的 DFS 方式。
两种常见分类
前序遍历和后序遍历是最常见的两种 DFS 方式。而另外一种遍历方式 (中序遍历)一般用于平衡二叉树,这个我们后面的「四个重要概念」部分再讲。
前序遍历
如果你的代码大概是这么写的(注意主要逻辑的位置):
function dfs(root) { if (满足特定条件){ // 返回结果 or 退出搜索空间 } // 主要逻辑 dfs(root.left) dfs(root.right)}那么此时我们称为前序遍历。
后续遍历
而如果你的代码大概是这么写的(注意主要逻辑的位置):
function dfs(root) { if (满足特定条件){ // 返回结果 or 退出搜索空间 } dfs(root.left) dfs(root.right) // 主要逻辑}那么此时我们称为后序遍历。
值得注意的是, 我们有时也会会写出这样的代码:
function dfs(root) { if (满足特定条件){ // 返回结果 or 退出搜索空间 } // 做一些事 dfs(root.left) dfs(root.right) // 做另外的事}如上代码,我们在进入和退出左右子树的时候分别执行了一些代码。那么这个时候,是前序遍历还是后续遍历呢?实际上,这属于混合遍历了。不过我们这里只考虑「主逻辑」的位置,关键词是「主逻辑」。
如果代码主逻辑在左右子树之前执行,那么就是前序遍历。如果代码主逻辑在左右子树之后执行,那么就是后序遍历。关于更详细的内容, 我会在「七个技巧」 中的「前后遍历」部分讲解,大家先留个印象,知道有着两种方式就好。
递归遍历的学习技巧
上面的《一个中心》部分,给大家介绍了一种干货技巧《双色遍历》统一三种遍历的迭代写法。 而树的遍历的递归的写法其实大多数人都没问题。为什么递归写的没问题,用栈写迭代就有问题呢? 本质上其实还是对递归的理解不够。那 lucifer 今天给大家介绍一种练习递归的技巧。其实文章开头也提到了,那就是画图 + 手动代入。有的同学不知道怎么画,这里我抛砖引玉分享一下我学习递归的画法。
比如我们要前序遍历一棵这样的树:
1 / 2 3 / 4 5
图画的还算比较清楚, 就不多解释了。大家遇到题目多画几次这样的递归图,慢慢就对递归有感觉了。
广度优先遍历
树的遍历的两种方式分别是 DFS 和 BFS,刚才的 DFS 我们简单过了一下前序和后序遍历,对它们有了一个简单印象。这一小节,我们来看下树的另外一种遍历方式 - BFS。
BFS 也是图论中算法的一种,不同于 DFS, BFS 采用横向搜索的方式,在数据结构上通常采用队列结构。 注意,DFS 我们借助的是栈来完成,而这里借助的是队列。
BFS 比较适合找「最短距离/路径」和「某一个距离的目标」。比如给定一个二叉树,在树的最后一行找到最左边的值。,此题是力扣 513 的原题。这不就是求距离根节点「最远距离」的目标么? 一个 BFS 模板就解决了。
BFS 图解:
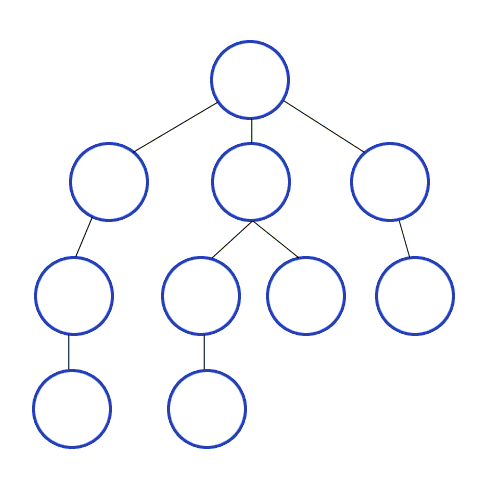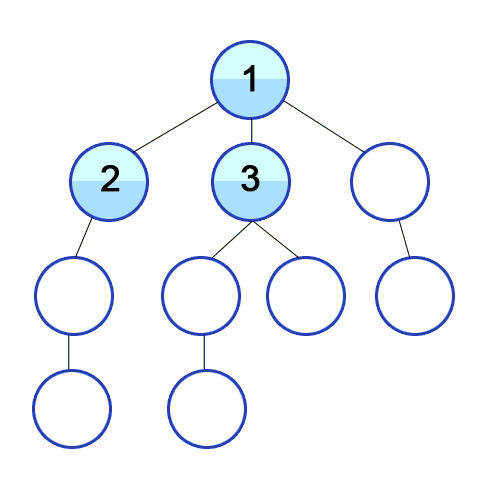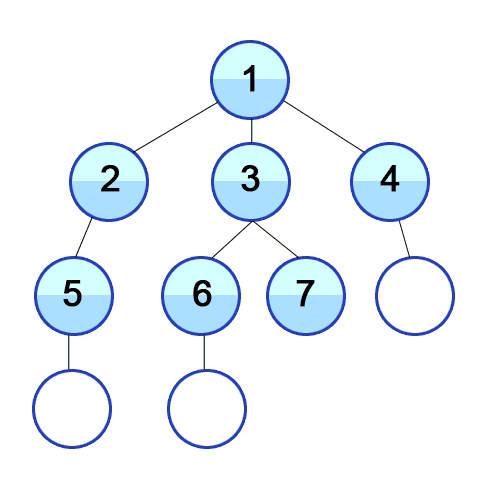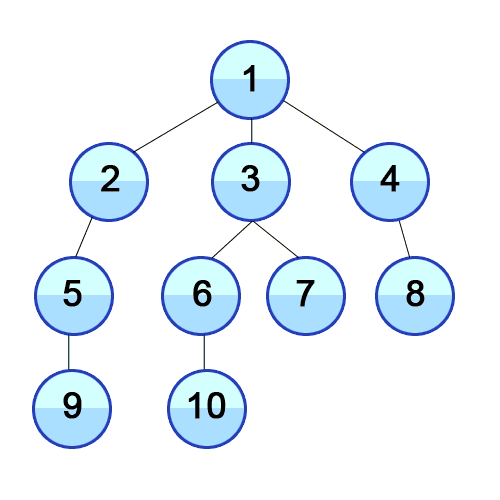
binary-tree-traversal-bfs
(图片来自 https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/tree/breadth-first-search)
算法流程
- 首先将根节点放入队列中。
- 从队列中取出第一个节点,并检验它是否为目标。 如果找到目标,则结束搜索并回传结果。否则将它所有尚未检验过的直接子节点加入队列中。
- 若队列为空,表示整张图都检查过了——亦即图中没有欲搜索的目标。结束搜索并回传“找不到目标”。
- 重复步骤 2。
算法模板
const visited = {}function bfs() { let q = new Queue() q.push(初始状态) while(q.length) { let i = q.pop() if (visited[i]) continue if (i 是我们要找的目标) return 结果 for (i的可抵达状态j) { if (j 合法) { q.push(j) } } } return 没找到}两种常见分类
BFS 我目前使用的模板就两种,这两个模板可以解决所有的树的 BFS 问题。
前面我提到了“BFS 比较适合找「最短距离/路径」和「某一个距离的目标」”。 如果我需要求的是最短距离/路径,我是不关心我走到第几步的,这个时候可是用不标记层的目标。而如果我需要求距离某个节点距离等于 k 的所有节点,这个时候第几步这个信息就值得被记录了。
❝
小于 k 或者 大于 k 也是同理。
❞
标记层
一个常见的 BFS 模板,代入题目只需要根据题目微调即可。
class Solution: def bfs(k): # 使用双端队列,而不是数组。因为数组从头部删除元素的时间复杂度为 N,双端队列的底层实现其实是链表。 queue = collections.deque([root]) # 记录层数 steps = 0 # 需要返回的节点 ans = [] # 队列不空,生命不止! while queue: size = len(queue) # 遍历当前层的所有节点 for _ in range(size): node = queue.popleft() if (step == k) ans.append(node) if node.right: queue.append(node.right) if node.left: queue.append(node.left) # 遍历完当前层所有的节点后 steps + 1 steps += 1 return ans不标记层
不带层的模板更简单,因此大家其实只需要掌握带层信息的目标就够了。
一个常见的 BFS 模板,代入题目只需要根据题目微调即可。
class Solution: def bfs(k): # 使用双端队列,而不是数组。因为数组从头部删除元素的时间复杂度为 N,双端队列的底层实现其实是链表。 queue = collections.deque([root]) # 队列不空,生命不止! while queue: node = queue.popleft() # 由于没有记录 steps,因此我们肯定是不需要根据层的信息去判断的。否则就用带层的模板了。 if (node 是我们要找到的) return node if node.right: queue.append(node.right) if node.left: queue.append(node.left) return -1以上就是 BFS 的两种基本方式,即带层和不带层,具体使用哪种看题目是否需要根据层信息做判断即可。
小结
树的遍历是后面所有内容的基础,而树的遍历的两种方式 DFS 和 BFS 到这里就简单告一段落,现在大家只要知道 DFS 和 BFS 分别有两种常见的方式就够了,后面我会给大家详细补充。

三种题型
树的题目就三种类型,分别是:「搜索类,构建类和修改类,而这三类题型的比例也是逐渐降低的」,即搜索类的题目最多,其次是构建类,最后是修改类。这一点和链表有很大的不同,链表更多的是修改类。
接下来,lucifer 给大家逐一讲解这三种题型。
搜索类
搜索类的题目是树的题目的绝对大头。而搜索类只有两种解法,那就是 DFS 和 BFS,下面分别介绍。
几乎所有的搜索类题目都可以方便地使用递归来实现,关于递归的技巧会在「七个技巧中的单/双递归」部分讲解。还有一小部分使用递归不好实现,我们可以使用 BFS,借助队列轻松实现,比如最经典的是求二叉树任意两点的距离,树的距离其实就是最短距离,因此可以用 BFS 模板解决。这也是为啥我说「DFS 和 BFS」是树的题目的两个基本点的原因。
所有搜索类的题目只要把握三个核心点,即「开始点」,「结束点」 和 「目标」即可。
DFS 搜索
DFS 搜索类的基本套路就是从入口开始做 dfs,然后在 dfs 内部判断是否是结束点,这个结束点通常是「叶子节点」或「空节点」,关于结束这个话题我们放在「七个技巧中的边界」部分介绍,如果目标是一个基本值(比如数字)直接返回或者使用一个全局变量记录即可,如果是一个数组,则可以通过扩展参数的技巧来完成,关于扩展参数,会在「七个技巧中的参数扩展」部分介绍。 这基本就是搜索问题的全部了,当你读完后面的七个技巧,回头再回来看这个会更清晰。
套路模板:
# 其中 path 是树的路径, 如果需要就带上,不需要就不带def dfs(root, path): # 空节点 if not root: return # 叶子节点 if not root.left and not root.right: return path.append(root) # 逻辑可以写这里,此时是前序遍历 dfs(root.left) dfs(root.right) # 需要弹出,不然会错误计算。 # 比如对于如下树: """ 5 / 4 8 / / 11 13 4 / / 7 2 5 1 """ # 如果不 pop,那么 5 -> 4 -> 11 -> 2 这条路径会变成 5 -> 4 -> 11 -> 7 -> 2,其 7 被错误地添加到了 path path.pop() # 逻辑也可以写这里,此时是后序遍历 return 你想返回的数据比如剑指 Offer 34. 二叉树中和为某一值的路径 这道题,题目是:输入一棵二叉树和一个整数,打印出二叉树中节点值的和为输入整数的所有路径。从树的根节点开始往下一直到叶节点所经过的节点形成一条路径。 这不就是从根节点开始,到叶子节点结束的所有路径「搜索出来」,挑选出和为目标值的路径么?这里的开始点是根节点, 结束点是叶子节点,目标就是路径。
对于求这种满足「特定和」的题目,我们都可以方便地使用「前序遍历 + 参数扩展的形式」,关于这个,我会在「七个技巧中的前后序部分」展开。
❝
由于需要找到所有的路径,而不仅仅是一条,因此这里适合使用回溯暴力枚举。关于回溯,可以参考我的 回溯专题[7]
❞
class Solution: def pathSum(self, root: TreeNode, target: int) -> List[List[int]]: def backtrack(nodes, path, cur, remain): # 空节点 if not cur: return # 叶子节点 if cur and not cur.left and not cur.right: if remain == cur.val: res.append((path + [cur.val]).copy()) return # 选择 tepathmp.append(cur.val) # 递归左右子树 backtrack(nodes, path, cur.left, remain - cur.val) backtrack(nodes, path, cur.right, remain - cur.val) # 撤销选择 path.pop(-1) ans = [] # 入口,路径,目标值全部传进去,其中路径和path都是扩展的参数 dfs(ans, [], root, target, ) return ans再比如:1372. 二叉树中的最长交错路径,题目描述:
给你一棵以 root 为根的二叉树,二叉树中的交错路径定义如下:选择二叉树中 任意 节点和一个方向(左或者右)。如果前进方向为右,那么移动到当前节点的的右子节点,否则移动到它的左子节点。改变前进方向:左变右或者右变左。重复第二步和第三步,直到你在树中无法继续移动。交错路径的长度定义为:访问过的节点数目 - 1(单个节点的路径长度为 0 )。请你返回给定树中最长 交错路径 的长度。比如: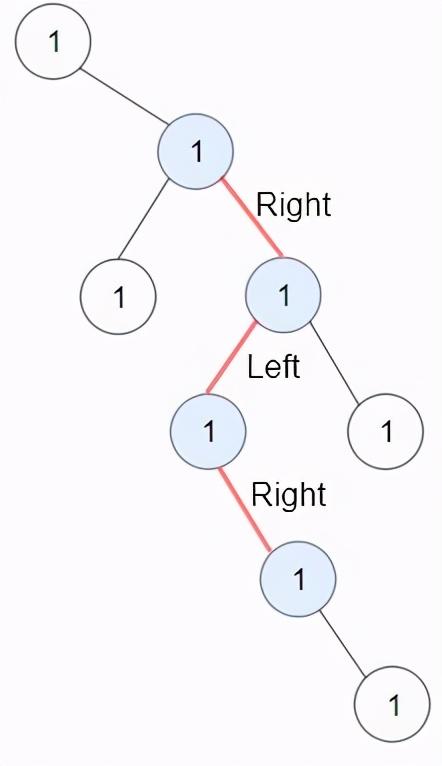
此时需要返回 3解释:蓝色节点为树中最长交错路径(右 -> 左 -> 右)。这不就是从任意节点「开始」,到任意节点「结束」的所有交错「路径」全部「搜索出来」,挑选出最长的么?这里的开始点是树中的任意节点,结束点也是任意节点,目标就是最长的交错路径。
对于入口是任意节点的题目,我们都可以方便地使用「双递归」来完成,关于这个,我会在「七个技巧中的单/双递归部分」展开。
对于这种交错类的题目,一个好用的技巧是使用 -1 和 1 来记录方向,这样我们就可以通过乘以 -1 得到另外一个方向。
❝
886. 可能的二分法 和 785. 判断二分图 都用了这个技巧。
❞
用代码表示就是:
next_direction = cur_direction * - 1这里我们使用双递归即可解决。 如果题目限定了只从根节点开始,那就可以用单递归解决了。值得注意的是,这里内部递归需要 cache 一下 , 不然容易因为重复计算导致超时。
❝
我的代码是 Python,这里的 lru_cache 就是一个缓存,大家可以使用自己语言的字典模拟实现。
❞
class Solution: @lru_cache(None) def dfs(self, root, dir): if not root: return 0 if dir == -1: return int(root.left != None) + self.dfs(root.left, dir * -1) return int(root.right != None) + self.dfs(root.right, dir * -1) def longestZigZag(self, root: TreeNode) -> int: if not root: return 0 return max(self.dfs(root, 1), self.dfs(root, -1), self.longestZigZag(root.left), self.longestZigZag(root.right))这个代码不懂没关系,大家只有知道搜索类题目的大方向即可,具体做法我们后面会介绍,大家留个印象就行。更多的题目以及这些技巧的详细使用方式放在「七个技巧部分」展开。
BFS 搜索
这种类型相比 DFS,题目数量明显降低,套路也少很多。题目大多是求距离,套用我上面的两种 BFS 模板基本都可以轻松解决,这个不多介绍了。
构建类
除了搜索类,另外一个大头是构建类。构建类又分为两种:普通二叉树的构建和二叉搜索树的构建。
普通二叉树的构建
而普通二叉树的构建又分为三种:
- 给你两种 DFS 的遍历的结果数组,让你构建出原始的树结构。比如根据先序遍历和后序遍历的数组,构造原始二叉树。这种题我在构造二叉树系列 系列里讲的很清楚了,大家可以去看看。
❝
这种题目假设输入的遍历的序列中都不含重复的数字,想想这是为什么。
❞
- 给你一个 BFS 的遍历的结果数组,让你构建出原始的树结构。
最经典的就是 剑指 Offer 37. 序列化二叉树。我们知道力扣的所有的树表示都是使用数字来表示的,而这个数组就是一棵树的层次遍历结果,部分叶子节点的子节点(空节点)也会被打印。比如:[1,2,3,null,null,4,5],就表示的是如下的一颗二叉树:
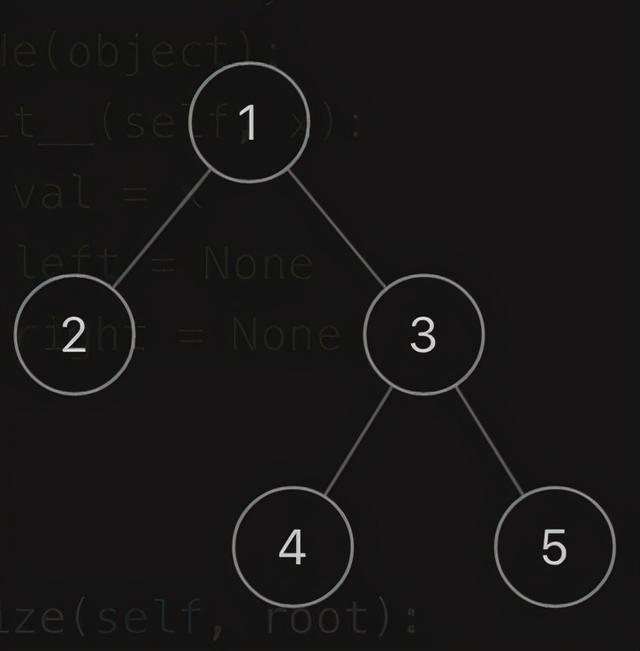
我们是如何根据这样的一个层次遍历结果构造出原始二叉树的呢?这其实就属于构造二叉树的内容,这个类型目前力扣就这一道题。这道题如果你彻底理解 BFS,那么就难不倒你。
- 还有一种是给你描述一种场景,让你构造一个符合条件的二叉树。这种题和上面的没啥区别,套路简直不要太像,比如 654. 最大二叉树,我就不多说了,大家通过这道题练习一下就知道了。
除了这种静态构建,还有一种很很罕见的动态构建二叉树的,比如 894. 所有可能的满二叉树 ,对于这个题,直接 BFS 就好了。由于这种题很少,因此不做多的介绍。大家只要把最核心的掌握了,这种东西自然水到渠成。
二叉搜索树的构建
普通二叉树无法根据一种序列重构的原因是只知道根节点,无法区分左右子树。如果是二叉搜索树,那么就有可能根据「一种遍历序列」构造出来。 原因就在于二叉搜索树的根节点的值大于所有的左子树的值,且小于所有的右子树的值。因此我们可以根据这一特性去确定左右子树的位置,经过这样的转换就和上面的普通二叉树没有啥区别了。比如 1008. 前序遍历构造二叉搜索树
修改类
上面介绍了两种常见的题型:搜索类和构建类。还有一种比例相对比较小的题目类型是修改类。
❝
当然修改类的题目也是要基于搜索算法的,不找到目标怎么删呢?
❞
修改类的题目有两种基本类型。
七个技巧
由于头条的发文限制字数,因此剩下的贴不了,大家可以去我的公众号《力扣加加》解锁全部内容
我整理的 1000 多页的电子书已经开发下载了,大家可以去我的公众号《力扣加加》后台回复电子书获取。


Reference
[1]
树标签: https://leetcode-cn.com/tag/tree/
[2]
leetcode 算法题解: https://github.com/azl397985856/leetcode
[3]
递归可视化网站: https://recursion.now.sh/
[4]
平衡二叉树: https://github.com/azl397985856/leetcode/blob/master/thinkings/balanced-tree.md
[5]
365. 水壶问题: https://github.com/azl397985856/leetcode/blob/master/problems/365.water-and-jug-problem.md
[6]
二叉树的遍历: https://github.com/azl397985856/leetcode/blob/master/thinkings/binary-tree-traversal.md
[7]
回溯专题: https://github.com/azl397985856/leetcode/blob/master/thinkings/backtrack.md
[8]
113. 路径总和 I: https://github.com/azl397985856/leetcode/blob/master/problems/113.path-sum-ii.md
[9]
几乎刷完了力扣所有的链表题,我发现了这些东西。。。: https://lucifer.ren/blog/2020/11/08/linked-list/















 2567
2567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









