






早前调研了知识图谱的基础概念和技术框架,最近这两个月倒腾了一个古诗词的图谱demo,仅以此文记录一下实验过程。从零开始做这个Demo,整个过程大致分为三大步骤:数据采集,数据存储以及图谱应用,全文将按这三步进行记录。
一、数据采集
既然是从零开始,那第一步就是要爬取数据。搜了几个诗词网站,对比网页排版结构和内容丰富程度,个人觉得古诗词网是个不错的选择,在这里感谢站长为经典文化传承作出的贡献。
1. 网页分析
F12打开诗词列表页的源码,查看头部信息如下图:
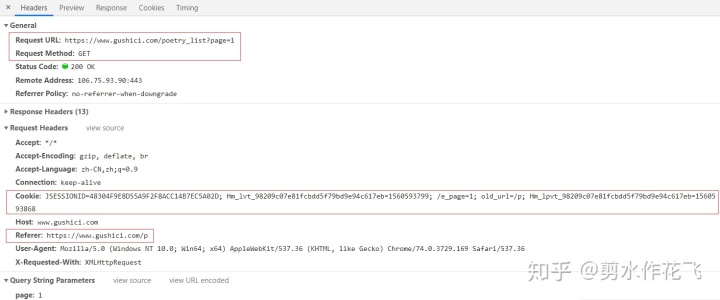
请求的url格式固定,只有页码改变;请求的类型为get。
多看几个页面,可以发现请求头中Cookie的hm_lvt和hm_lpvt为两个时间戳,不同页面只有hml_pvt发生改变;old_url取值为当前页码;Referer也是随页码改变的固定格式url。
请求列表页面的返回结果为json列表,可以非常方便地提取需要的信息,而不用去html中定位并解析目标元素,省去了爬虫中的一半工作量:
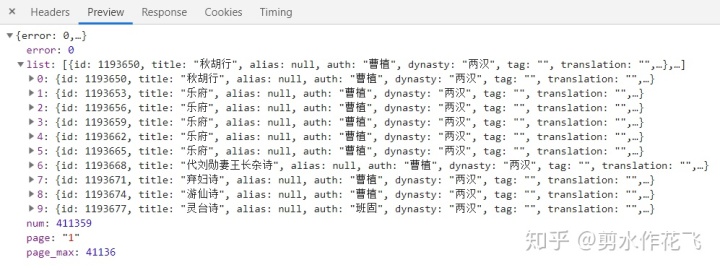
每一个json对应一首诗词,包含标题、正文、作者、朝代、标签、体裁、作者介绍、译注、赏析等信息,这种结构化的数据,也免去了数据抽取和整理的很多工作。
2. 爬虫代码
这一类网站广告很少,也没有收费业务,带有公益性质,网站服务器一般也扛不住爬虫的压力,常常会采取一些反爬措施,比如封禁IP。为了爬取这些网站,一方面要降低爬取速度;另一方面要维护代理池,在被封的时候更换IP。爬取过程中及时保存爬虫结果,并记录爬取失败的页面,方便以后再重爬。
def crawl_pages(page_list, save_path, ip_pool, retry_times=5):
fail_list = list()
lvt_code = int(time.time())
ip = random.choice(ip_pool)
for page in page_list:
time.sleep(3 * random.random())
lpvt_code = int(time.time())
page_url = 'https://www.gushici.com/poetry_list?page={0}'.format(page)
referer = 'https://www.gushici.com/p_{0}'.format(page)
headers = {
'Host': 'www.gushici.com',
'Connection': 'keep-alive',
'Accept': '*/*',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
'Referer': referer,
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









