





前两天突然间脑子抽风想要用python来爬一下视频网站,获取视频。一开始无从下手,在网上搜了很多相关的博客,然而也并未找到一个理想的解决方案,但是好在最终能够将视频网站的视频给爬下来,尽管吃相难看了点。特此将整个过程以及思考给记录下来。
我的目标是爬取腾讯视频的视频内容,在网上搜索出来的结果是利用第三方解析网站对视频进行解析,然后在爬取,这是最简单的解决方案。于是乎也就照搬照做了。详细过程如下:

仔细的查看下这些ts文件发现并没有需要携带的其他参数直接访问其url便可实现下载,当然了下载下来的也只是一小段视频片段。
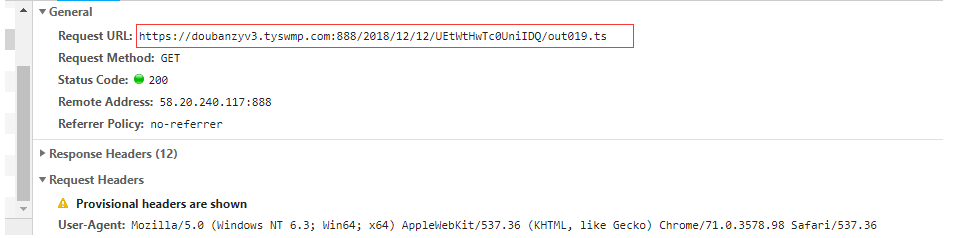
按照网上的一种做法直接请求这些url将其下载下来然后在合并成一个完整的视频片段。这种做法的代码我先贴出来以供参考。
1 importtime2 importrequests3
4
5 defloder(i):6 """直接请求ts文件的url然后在写入到本地"""
7 url = 'https://doubanzyv3.tyswmp.com:888/2018/12/12/UEtWtHwTc0UniIDQ/out%03d.ts' % i #%03d 左边补0方式
8 html =requests.get(url).content9
10 with open(r"D:\txsp_test\%s%03d.ts" % ("a", i), "wb") as f:11 f.write(html)12
13
14 if __name__ == "__main__":15 pool.map(loder, range(400))16 pool.join()17 pool.close()
这里你可以使用多进程或者多线程来进行优化,我在这里就不将代码贴出来了。通过这种方式下载下来的ts文件很可能会因为网络的问题出现漏下,少下的情况,为此我也是尝试了各种方法都没有找到一个最优解。我尝试了一个方法是为进程加锁,以信号量的形式对文件进行下载,确保ts文件的完整,同时也能保证异步、并发。但是这样做的话就相当于开启了400个进程。你的内存一定会溢出。(有兴趣的可以试下线程锁)
1 importtime2 importrequests3
4
5 defloder(i, sem):6 """直接请求ts文件的url然后在写入到本地"""
7 sem.acquire() #获取钥匙
8 url = 'https://doubanzyv3.tyswmp.com:888/2018/12/12/UEtWtHwTc0UniIDQ/out%03d.ts' % i #%03d 左边补0方式
9 html =requests.get(url).content10
11 with open(r"D:\txsp_test\%s%03d.ts" % ("a", i), "wb") as f:12 f.write(html)13 sem.release()14
15
16 if __name__ == "__main__":17 start_time =time.time()18 print(start_time)19 sem = Semaphore(5) #规定锁的个数
20 #pool = Pool(5)
21 p_l =[]22 for i in range(400):23 p = Process(target=loder, args=(i, sem))24 p.start()25 p_l.append(p)26 for i inp_l:27 i.join()28 print(time.time()-start_time)
然后在对下载好的文件进行合成
1 file_dir = r"D:\txsp_test" #文件的保存路径
2 new_file = u"%s\out.ts" % file_dir #合并之后的视频
3 f = open(new_file, 'wb+') #二进制文件写操作
4
5 for i in range(0, 338):6 file_path = r"D:\txsp_test\%s%03d.ts" % ("a", i) #视频片段名称
7 print(file_path)8 for line in open(file_path, "rb"):9 f.write(line)10 f.flush()11
12 f.close()
ok上面的是一种做法,很显然可以将视频的下载与合并发在一起。我也不贴出来了。接下来就是另外一种做法。
这种做法相对来说更加的合理,就是先找到.m3u8的文件。

然后向其发送get请求,得到的响应结果就是一段段的.ts集合。(不知道我在说什么的请看上面的博客,或者自己动手requests.get()试下)这时可以通过正则匹配出.ts的文件然后在下载下来。最后合并成完整的视频。
代码如下:(采用了多线程对.ts文件进行下载)
1 importre2 importos3 importshutil4 from concurrent.futures importThreadPoolExecutor5 from urllib.request importurlretrieve6
7 importrequests8 from scrapy importSelector9
10
11 classVideoDownLoader(object):12 def __init__(self, url):13 self.api = 'https://jx.618g.com'
14 self.get_url = 'https://jx.618g.com/?url=' +url15 self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
16 'Chrome/63.0.3239.132 Safari/537.36'}17
18 self.thread_num = 32
19 self.i =020 html =self.get_page(self.get_url)21 ifhtml:22 self.parse_page(html)23
24 defget_page(self, get_url):25 """获取网页"""
26 try:27 print('正在请求目标网页....', get_url)28 response = requests.get(get_url, headers=self.headers)29 if response.status_code == 200:30 #print(response.text)
31 print('请求目标网页完成....\n准备解析....')32 self.headers['referer'] =get_url33 returnresponse.text34 exceptException:35 print('请求目标网页失败,请检查错误重试')36 returnNone37
38 defparse_page(self, html):39 """解析网页"""
40 print('目标信息正在解析........')41 selector = Selector(text=html)42 self.title = selector.xpath("//head/title/text()").extract_first() #获取标题(电影名称)
43 print(self.title)44 m3u8_url = selector.xpath("//div[@id='a1']/iframe/@src").extract_first()[14:] #获取视频地址(m3u8)
45 self.ts_list = self.get_ts(m3u8_url) #得到一个包含ts文件的列表
46 print('解析完成,下载ts文件.........')47 self.pool()48
49 defget_ts(self, m3u8_url):50 """解析m3u8文件获取ts文件"""
51 try:52 response = requests.get(m3u8_url, headers=self.headers)53 html =response.text54 print('获取ts文件成功,准备提取信息')55 ret_list = re.findall("(out.*?ts)+", html) #匹配.ts的字段
56 ts_list =[]57 for ret inret_list:58 ts_url = m3u8_url[:-13] +ret59 ts_list.append(ts_url)60 returnts_list61 exceptException:62 print('缓存文件请求错误1,请检查错误')63
64 defpool(self):65 print('经计算需要下载%d个文件' %len(self.ts_list))66 if self.title not inos.listdir():67 os.mkdir(r"D:" + self.title) #新建视频目录
68 print('正在下载...所需时间较长,请耐心等待..')69 #开启多进程下载
70 pool = pool = ThreadPoolExecutor(max_workers=16) # 多线程下载71 pool.map(self.save_ts, self.ts_list)72 pool.shutdown()73 print('下载完成')74 self.ts_to_mp4()75
76 defts_to_mp4(self):77 print('ts文件正在进行转录mp4......')78 str = 'copy /b' + self.title+'\*.ts' + self.title + '.mp4' #copy /b 命令
79 os.system(str)80 filename = self.title + '.mp4'
81 ifos.path.isfile(filename):82 print('转换完成,祝你观影愉快')83 shutil.rmtree(self.title)84
85 defsave_ts(self, ts_list):86 print(self.title)87 self.i += 1
88 print('当前进度%d' %self.i)89 urlretrieve(url=ts_list, filename=r"D:" + self.title + '\{}'.format(ts_list[-9:]))90
91
92 if __name__ == '__main__':93 url = "https://v.qq.com/x/cover/c949qjcugx9a7gh.html" #视频url
94 video_down_loader = VideoDownLoader(url)
运行代码,喝一杯coffee等待10来分钟视频就自动下载好了。但是这里依然会存在这下载下来的.ts文件不完整的情况,博客写到这里我脑海里面又想到了一种解决方法,明天试一试把。哦对了,关于视频的文件下载多线程,多进程我分别都试过,两者的下载速度区别并不大,因为这涉及到了网络的请求以及文件的读写等IO操作。所以采用多线程/进程没啥区别,建议还是用多线程来。结果如下所示:
1 #下载400个.ts文件测试线程、进程的性能
2
3 #>>> multiprocessing ——> 196.01457595825195 默认开启4个进程
4 #>>> multiprocessing ——> 196.01457595825195 强制开启16个进程,实际上5个
5 #>>> threading ——> 174.57704424858093 默认开启4个线程
6 #>>> threading ——> 202.30066895484924 默认开启40个线程(网络卡顿)
7 #>>> threading ——> 155.5946135520935 默认开启16个线程
测试的结果表名,线程开启的速度确实比进程开启速度快。然并卵!















 1651
1651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









