





我是谁?妙蛙种子

一般建模流程主要分为特征工程+建模两步,其中特征工程又可以分为数据预处理阶段和特征工程阶段。数据预处理一般有数据无量纲化处理(归一化、标准化),缺失值填补(0填补,均值填补,随机森林填补),分类特征编码(分类特征编码、onehot),连续变量分段(二值化、分箱)。特征工程一般有特征提取(从非结构化数据中提取到新消息作为特征),特征创造(对特征进行组合得到新特征),特征选择(从所有特征中选择出有意义的特征)。在进行特征工程之前第一步需要的是理解业务。
在特征工程中,特征提取与特征创造在不同的建模任务中是完全不同的,这两者更多的与业务相关联,而特征选择可以有一些普遍意义上的方法,例如过滤法(方差过滤--剔除方差小于某阈值的,相关性过滤--卡方过滤/F检验/互信息,一般可以考虑先方差过滤,再互信息)、嵌入法(Embedded,需要用某个机器学习算法进行训练计算所有特征权重,并根据权重大小选择特征)、包装法(借助算法选择特征,计算成本高)、降维算法(pca,降维后特征的含义消失了)。
基于上进行罗辑回归评分卡的案例分析。

案例:用逻辑回归制作评分卡
评分卡是一种以分数形式来衡量一个客户的信用风险大小的手段。其本身与一般的建模类似,但是在特征工程中会涉及到一些较为特别的转换,例如需要分箱、计算woe,iv,ks等等。
0.导入必要的库
如果数据特征比较多,可以用pd.set_option('display.max_columns', None):显示所有行,查看所有特征的情况,当然也可以修改参数看到所有列。
1.数据读取与准备

本案例数据特征为358维,因此使用另一份文件对每个特征进行标注,区分每个特征是什么类型对特征,是否是布尔特征。

2.数据预处理
剔除无效样本

此处剔除来缺失率大于0.9对样本,还有其他对参考标准,例如某些样本不符合常理,也同样可以进行剔除,可以通过data.describe()查看特征对分布情况。需注意,在对样本对行进行增删后必须重置索引,否则后续可能会出错。

分训练集和测试集也同样需要进行索引重置
剔除无效特征

首先从直观对角度来剔除无效特征,使用特征标注文件,将无关变量剔除,同时对特征进行描述统计,剔除缺失率>0.5,差异系数<0.01,枚举数=1的特征,当然此处的阈值可以自行决定。

对于分类特征进行编码,labelencoder,这份数据中有3个特征属于非数字编码,因此需要先编码称数字才能进行建模,而在数据中又涉及到大量的缺失值,采取的方式是先对缺失值填充为-99,再进行编码,相当于把缺失值也算为一类。

缺失值填补,对于某些特别有意义对特征可以采用随机森林进行缺失值填补,其余字段用-99进行填补,填补后进行分箱,相当于就是将缺失值集中插补为1类。
针对评分卡对制作一般不进行归一化或标准化,诚然进行归一化/标准化可以提高模型效果,加速模型优化,但是归一化后的数据无法被业务人员准确识别。
评分卡中的另一个问题是得到的样本一般都是不均衡的样本,毕竟大部分人是不愿意违约的。而逻辑回归中一般采用上采样的方式来平衡样本。可以使用imblearn库,本案例给到的数据是已经进行平衡来的,因此无需采取这一步。
训练集和测试集也可以在这一步再进行划分,减少之前几步特征工程都要分别对训练集和测试集进行的工作量。

分箱数的确定,可以依据WOE和IV
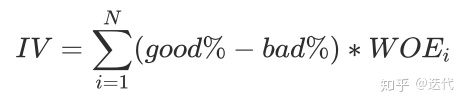

其中woe是针对于1个箱子的,而iv是针对于一个特征的。

分箱约多,IV越大,但是鲁棒性也会变差,本案例中多分箱IV值依然不高。
分箱的目的:组间差异大,组内差异小 。可以通过计算两个分箱之间的卡方值,如果两分箱差异不大,卡方检验p值会较大,那么两个分箱可以进行合并。
分箱步骤:
1)首先把连续型变量分成一组数量较多的分类变量,比如,将几万个样本分成100组,或50组
2)确保每组中都要包含两类样本,一类样本IV值会无法计算
3)对相邻的组进行卡方检验,若卡方检验的P值很大则进行合并,直到数据中的组数小于设定的箱数为止
4)一个特征分别分成[2,3,4.....20]箱,观察每个分箱个数下的IV值如何变化,找出最适合的分箱个数
5)分箱完后,计算每个箱的WOE值,观察分箱效果
在等频分箱的基础上可以将其升级为使用卡方检验检验两箱体之间是否存在显著差异,若无显著差异则合并两分箱。

将缺失值填补为‘-99’,使其成为单独一类
根据woe,iv,ks公式计算对应分值

根据iv和ks对计算结果筛选特征,这一步本质上依然是特征选择对过程。

依据上一步计算得到的每一个分箱的woe值,对原始数据进行woe编码映射,即在哪一分箱就用对应的woe值代替当前值。

分离x和y

在常规建模中会有特征衍生和特征筛选,但是在该建模任务中,效果均不佳。

基于上述数据进行建模,建模效果并没有很好

学习曲线调参
















 3093
3093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









