





写这篇文章的初衷是,让很多学pandas制作统计图表的小伙伴们少走一点弯路。百度上有不少讲诉pandas的教程或者博文,但大都太片面,或者模棱两可,内容不全。小编在这里跟大家详细理一理pandas绘制图表相关的一些小技巧。
所有绘制pandas表的python脚本,都有一个固定的编码范式,见下文。
# coding=utf8
# !/usr/bin/env python3
import os
import sysimport pandas as pd
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsesys.path.insert(0, os.path.dirname(os.path.abspath(__file__)) + "/..")
这段代码放到脚本开头,就可以处理掉中文乱码,中文编码的问题。看不懂的小伙伴自行百度即可,这里小编不做过多的描述。
一般我们日常的图表都会有横轴,纵轴。这里我先以折线图为例:
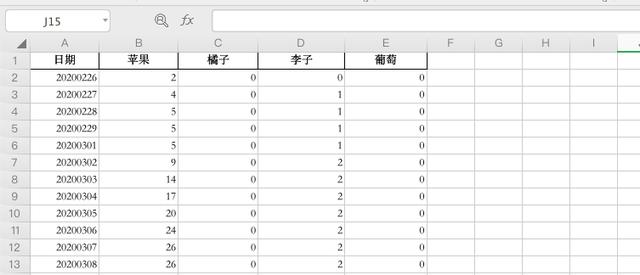
数据样例
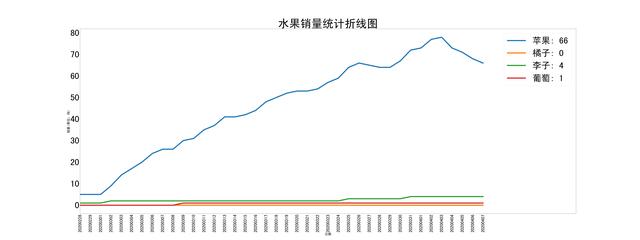
折线图
先上一段源码,用pandas来绘制上面的折线图
# coding=utf8
# !/usr/bin/env python3
# author = 小维python工作室
import os
import sys
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
sys.path.insert(0, os.path.dirname(os.path.abspath(__file__)) + "/..")
# 加载excel文件
df = pd.read_excel("./example.xlsx")
# 将日期这一列转换成字符串类型
df['日期'] = df['日期'].map(lambda x: str(int(x)))
# 设置日期一列为索引
ax = df.set_index('日期')
# 提取最后一行数据
current_record = df.tail(1)
# 修改dataFrame对象columns
columns = []
for goods in ax.columns:
count = current_record[goods].values[0]
columns.append("%s: %s" % (goods, count))
ax.columns = columns
# 画折线图,figsize为图片宽高像素值,linewidth可以加粗折线
ax.plot.line(figsize=(80, 30), linewidth=10)
# 设置x轴需要展示的日期数据,rotation为逆时针旋转角度, fontsize设置x轴字体大小
plt.xticks(df.index, df["日期"], rotation=90, fontsize=40)
# 设置x轴,y轴的名称
plt.xlabel("日期", fontsize=30)
plt.ylabel("销量(单位:吨)", fontsize=30)
# 隐藏y轴的值,并设置字体大小
plt.yticks(fontsize=80)
# 设置x轴的长度,和到坐标原点的间隔
plt.xlim(2, 8 + len(df['日期']))
# 设置画布字体大小
plt.legend(fontsize=80)
# 设置图表标题
plt.title("水果销量统计折线图", fontsize=100)
# 保存成png图片
plt.savefig("example.png")
小编加了详细的代码注释来标注每行代码的作用。再汇总一下用到的小技巧吧!
1,set_index函数可以指定dataframe对象某一列值为索引,索引列不参与统计
2,折线图右上角的分类线段描述可以通过修改columns属性实现
3,xticks,yticks可以重新自定义,不设置的画系统会默认处理,不会展示全部的值
4,xlim,ylim可以控制x,y轴有效的绘制区间。不设置的画右上角的标注会左右乱飘不固定
觉得小编的总结有帮助的,记得点波关注哦!!!















 5362
5362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









