







有头发且有趣的码农万里挑一~
65
有料叔 | 一位有故事的程序猿

解决UI自动化过程中的图文验证码问题,过程大致分为两个步骤:
1. 自动下载网页上指定的图片
2. 识别图片上的文本内容
本文以“识别页面上指定图片的文本“为例。
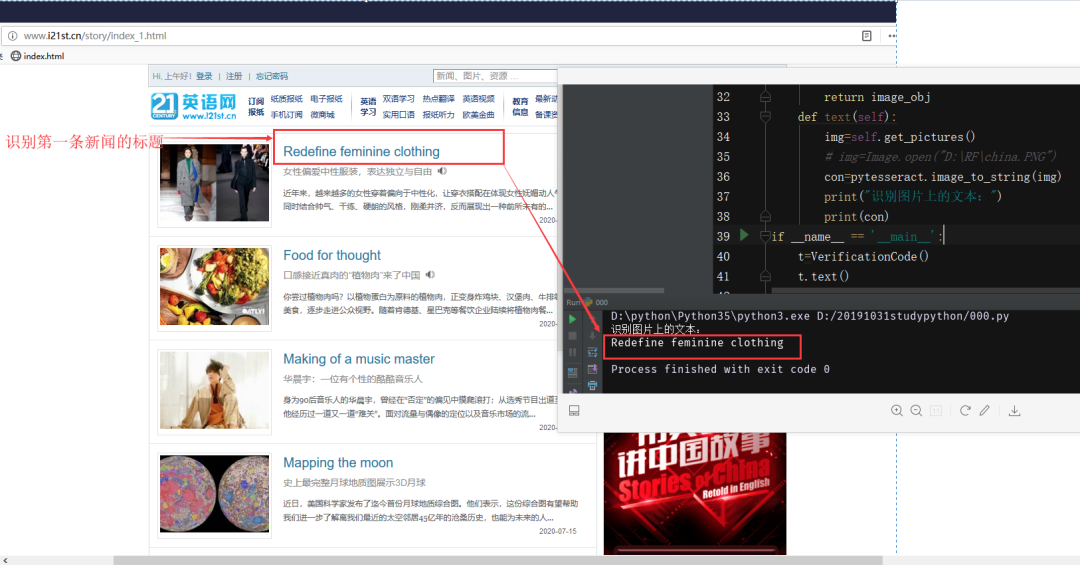
代码实现效果
Pytesseract
Tesseract-OCR
Pillow
手动安装pytesseract库
命令:pip install pytesseract

安装Tesseract-OCR.exe
下载地址
http://8rr.co/Krrw
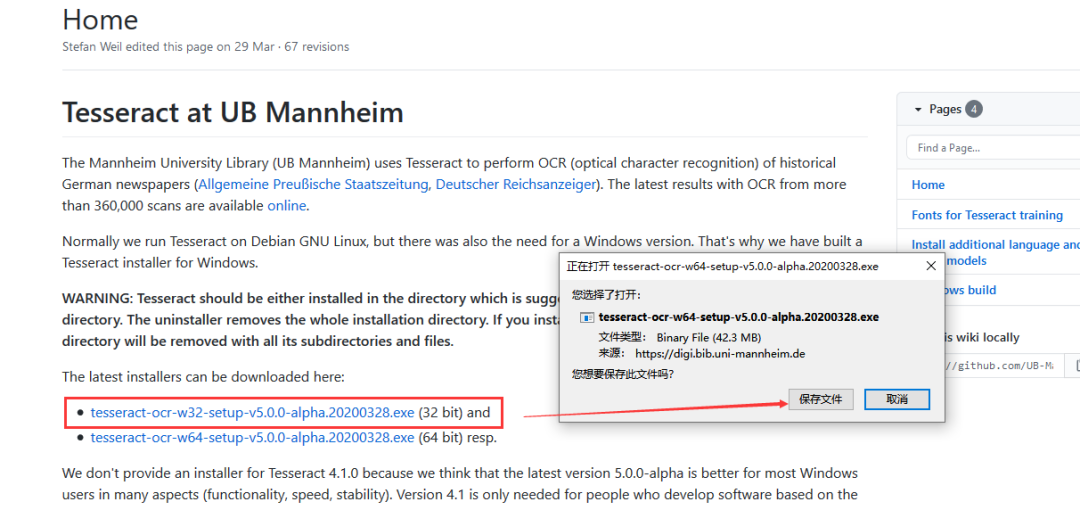
双击exe程序直接安装即可
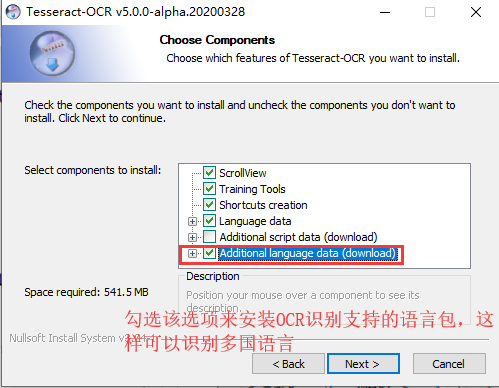
配置环境变量
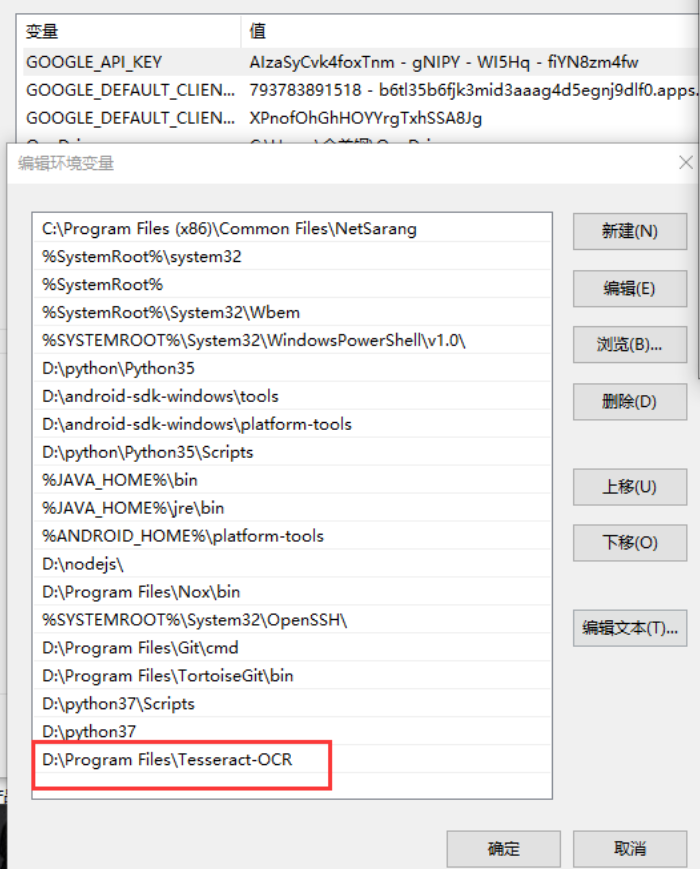
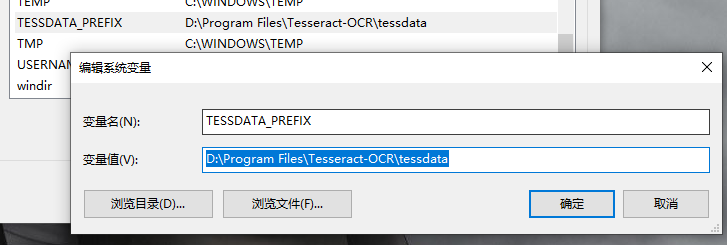
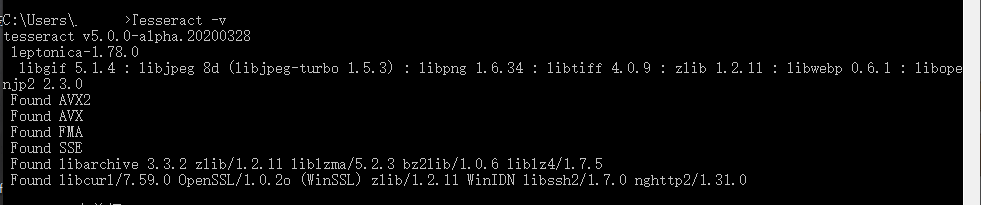
校验安装成功
安装Pillow包
Python自带的图文简单处理模块,正常安装Python的时候会自动安装,故无需另外手动安装。(若没自动安装则可手动安装:pip install Pillow)
代码正文
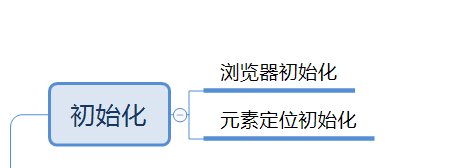
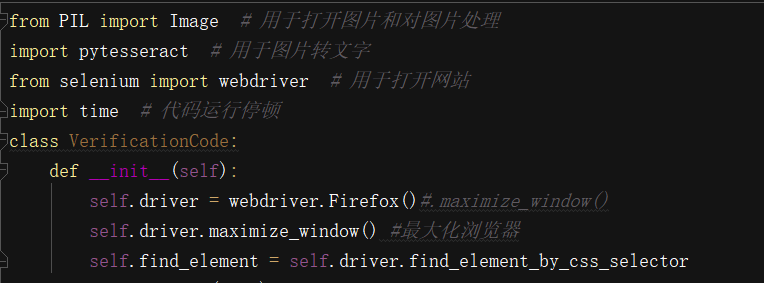
初始化浏览器和元素定位方式
初始化并放大浏览器
初始化元素定位方式:本文使用CSS选择器方式定位
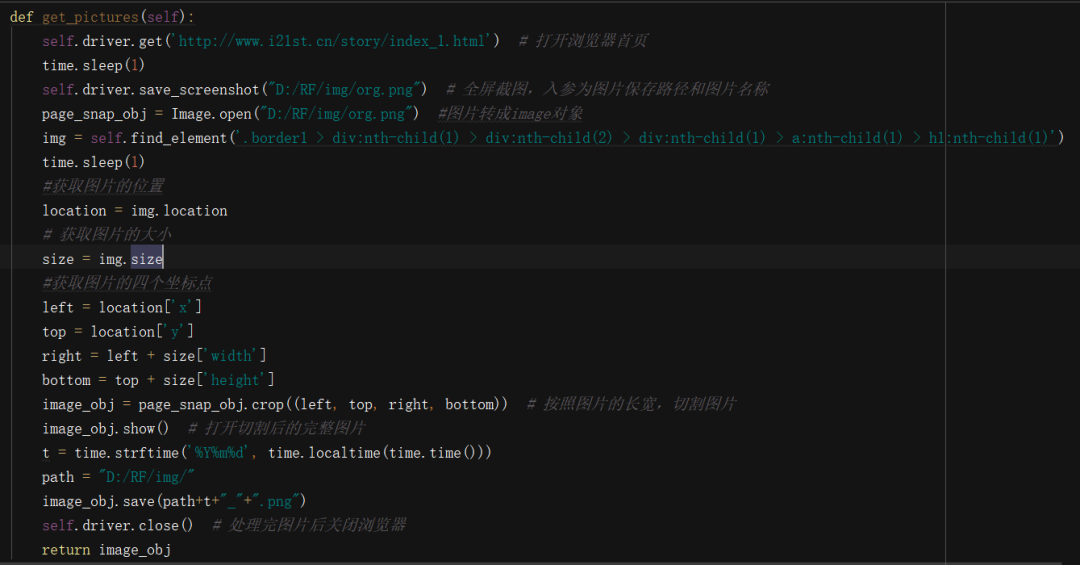
获取图片
页面全屏截图
截图转为Image对象
获取指定图片的大小和位置
裁剪图片

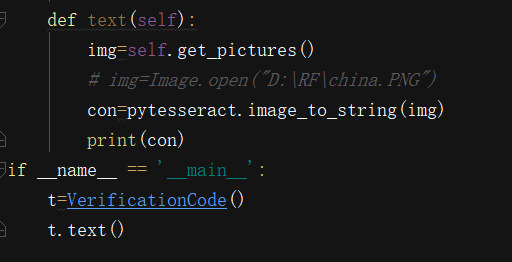
识别图片上的文本
识别裁剪后的图片上的文本内容

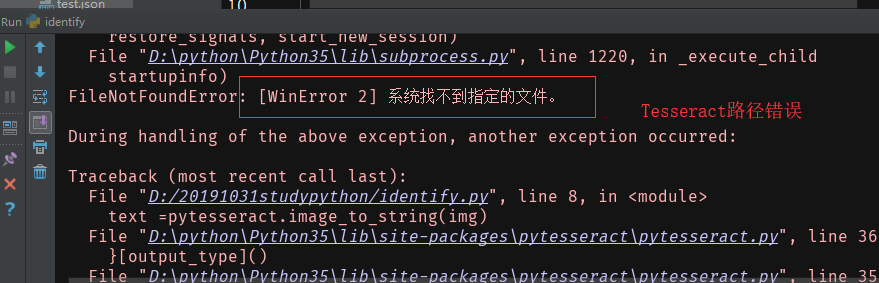
问题:
Python脚本运行报错:
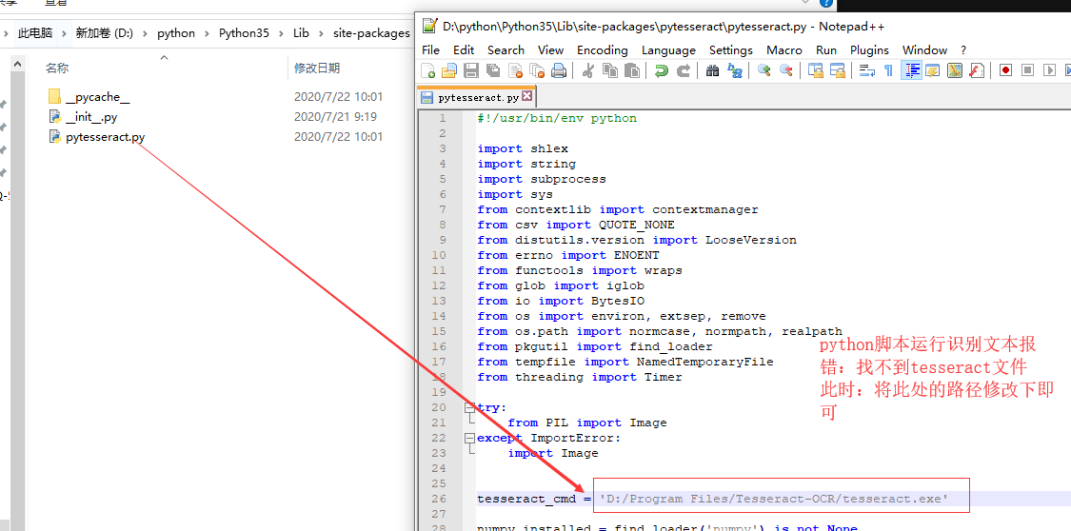
解决方案:
修改tesseract文件的默认路径
扫 码 学 习 码 同 学 福 利 课 程 哦

加 微 信 回 复 关 键 字 “训 练 营”

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









