





周末了,用 Python 代码给大家带来一个好玩的视频特效:
摄像头拍摄的视频中,右上角出现了一个可以跟随脑袋移动的虚拟对话框,可以实时展示说话内容。
你可能会问:就只是做了个摄像头特效,这也算 AR,还 AR 对话框?哈哈,请看AR定义:
增强现实技术(Augmented Reality,简称 AR),是一种实时地计算摄影机影像的位置及角度并加上相应图像、视频、3D 模型的技术,这种技术的目标是在屏幕上把虚拟世界套在现实世界并进行互动。
所以这么说来,我们做的摄像头特效,实时地进行了语音识别、面部识别定位,再通过图像处理为视频添加对话框效果,妥妥算是 AR 对话框了!
Talk is cheap, 接下来说设计思路和代码。
设计思路
我在之前分享过调用语音识别的文章,也尝试过调用面部识别来为摄像头视频增加特效,这是两个基础。此次通过将文字写入图片,将以上二者结合,生成最终效果。
我们仍然通过百度语音 API 来进行语音识别,把语音信息转化成文字。同时调用摄像头实时拍摄,对抓拍到的图片进行面部识别定位,在理想位置添加对话框特效。此外,随着语音文字信息的生成,动态地将文字添加到图片中,最终实现视频中的 AR 对话框。
语音识别
语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的技术,微信中将语音消息转文字,以及 “Hi Siri” 启用 Siri 时对其进行发号施令,都是语音识别的现实应用。
语音识别 API 其实就是帮你语音转文字的
百度语音识别通过 REST API 的方式给开发者提供一个通用的 HTTP 接口。任意操作系统、任意编程语言,只要可以对百度语音服务器发起 http 请求,均可使用此接口来实现语音识别。调用 API 的流程在百度语音官方文档中有说明。
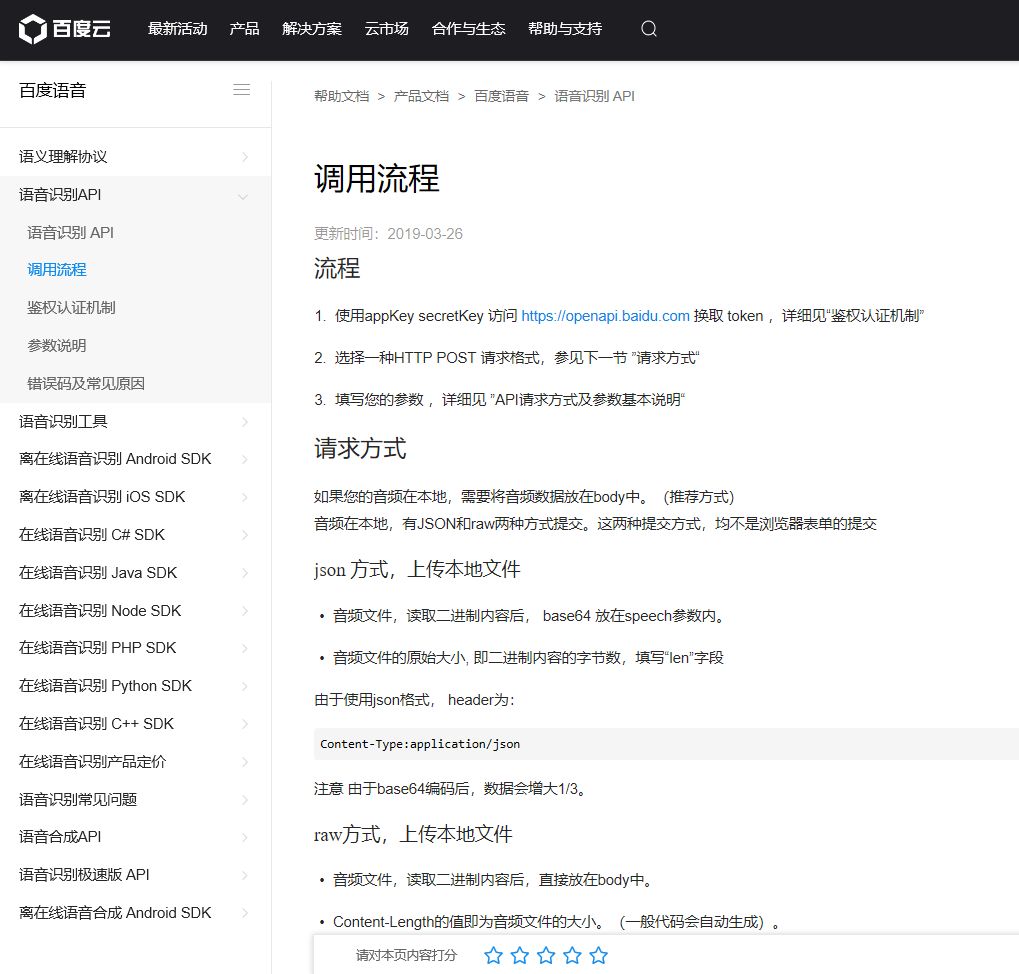

语音识别步骤 其实就是你得按人家的规矩来走流程
先注册百度云的账号,控制台中创建百度语音的应用,获取 API Key 和 Secret Key
通过 API Key 和 Secret Key 获取 token
将 token 和本地音频数据上传到 API 链接
根据 API 返回结果获取解析后的文字结果
注意上述过程中我们使用的是本地音频数据,那么如何将自己的语音转为相应的数据呢?只要调用麦克风记录我们的语音信息存为 wav 格式的文件即可;而实时语音识别,即一直保持检测麦克风,只要有声音就生成 wav 文件向 API 发送请求;当识别不到语音信息时,自动停止。代码中我参考了调用谷歌语音的 speech_recognition 模块,因为它调用麦克风的命令特别简单,而且会根据检测麦克风来自动结束录音。
import speech_recognition as srr = sr.Recognizer()#启用麦克风mic = sr.Microphone()with mic as source: #降噪 r.adjust_for_ambient_noise(source) audio = r.listen(source)视频特效
我们都知道摄像头视频是通过摄像头捕获每时每刻的图片,将图片连续展示生成视频效果。视频特效同理,本质上是对一帧帧图片进行图像处理添加特效。
通过 OpenCv 模块启用电脑摄像头,将拍到的图片利用 dlib 模块进行面部识别,定位头部右上方区域,通过 PIL 模块将对话框贴图并在对应区域写入文字,最终将生成图实时展示,形成最终效果。
OpenCv 其实就是用来调摄像头的
OpenCv 是一个很神奇的计算机视觉库,实现了图像处理和计算机视觉方面的很多通用算法。
计算机视觉是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。
要注意的是下载时是 opencv-python, 代码中导入时是 import cv2, 之后通过 cv2 中的函数即可调用摄像头拍摄,获取拍到的图片进行操作。最终生成效果图后,再将效果图实时展现,形成摄像头视频画面。
import cv2#opencv启用摄像头cap = cv2.VideoCapture(0)#退出摄像头、关闭窗口cap.release()cv2.destroyAllWindows()dlib 其实就是定位视频中人脸位置的
dlib 是一个包含机器学习算法的开源工具包。目前 dlib 已经被广泛的用在行业和学术领域,包括机器人,嵌入式设备,移动电话和大型高性能计算环境。
拿到拍摄的图片后,我们要定位脸部坐标来确定对话框添加位置。Python 可以直接调用 dlib 库进行面部模式识别,根据特征点位获取位置坐标:

获取16号点位置坐标定位脸部右侧,获取其右上方坐标位置用来放置聊天框及文本信息。
import dlib#dlib面部识别模块相关detector = dlib.get_frontal_face_detector()predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")#获取面部模式landmarks = predictor(gray,face)x1, y1 = landmarks.part(16).x, landmarks.part(16).yPIL 其实就是用来贴对话框和文字的
PIL (Python Image Library) 是 Python 的第三方图像处理库,但是由于其强大的功能与众多的使用人数,几乎已经被认为是 python 官方图像处理库了。
我们利用 PIIL 模块中 Image,ImageDraw 和 ImageFont 的相关函数,实现贴图、文本字体的选择以及将文字写入图片中。
from PIL import Image, ImageDraw, ImageFontchatBox= Image.open(chatpng)resized1 = chatBox.resize((300, 200))im.paste(resized1, (int(x1), int(y1-200)), resized1)im.save(result)draw = ImageDraw.Draw(im)font = ImageFont.truetype('simhei.ttf', 20)draw.text((int(x1+50), int(y1-150)),talk,fill="rgb(255,255,255)",font=font)多线程
以上便是代码运行时要同时执行的两项任务,正好可以拿来练习多线程的使用:
import threadingthreads = []t1 = threading.Thread(target=chatbox, args=())threads.append(t1)t2 = threading.Thread(target=yuyin, args=())threads.append(t2)if __name__ == "__main__": for i in threads: i.start() for i in threads: i.join()最终效果
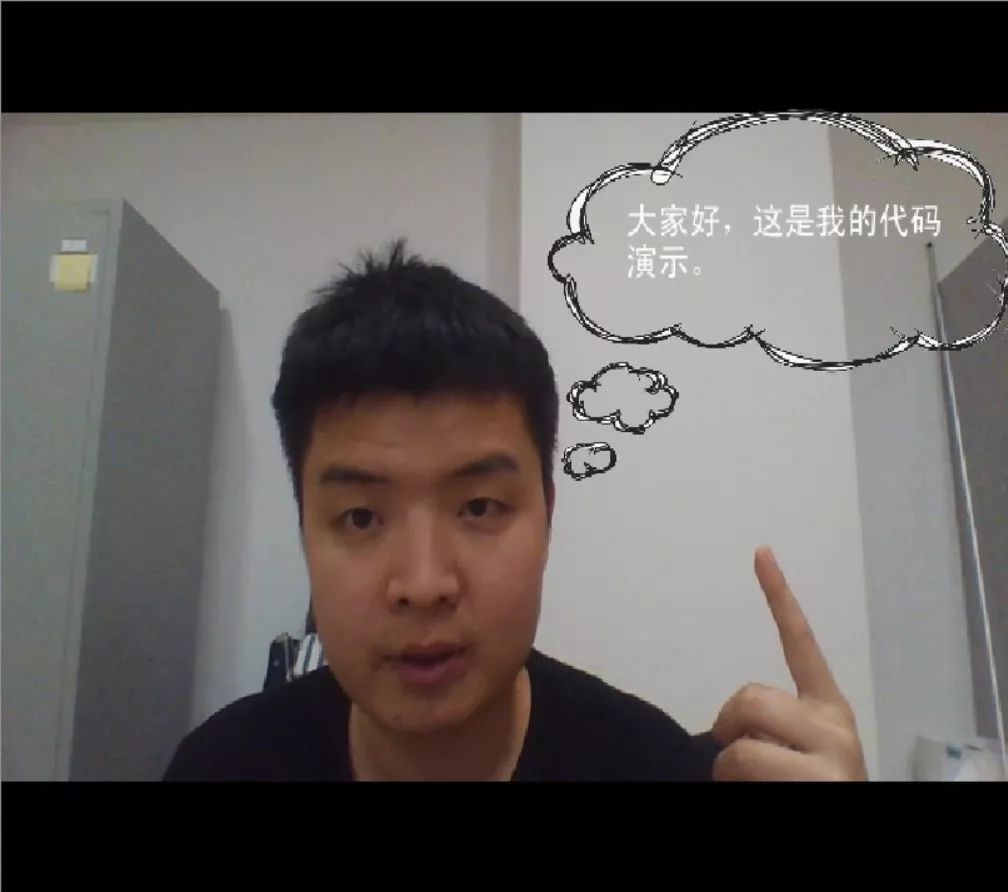
最终效果如文章开头的视频以及上图所示,电脑摄像头拍到的视频中会动态出现一个对话框,它随着我脑袋位置的变化而移动。当我说完一段话后,语音识别到的文字信息会被加载到对话框中。
因为要调用麦克风检测声音形成一段语音,再将语音信息通过百度语音 API 来完成识别,在视频中我们看到很明显的延迟。此外我使用的是最基础的免费语音识别 API,速度和准确度也不能保证,例如我最后一句“展示完毕”因为没标准发音被识别成了“感受完毕”。
后续联想
这次的代码可以看作一个思路的展示 (Demo),即语音识别和图像处理、视频特效的结合。
最近恰好注意到朋友那儿收到的反馈信息:
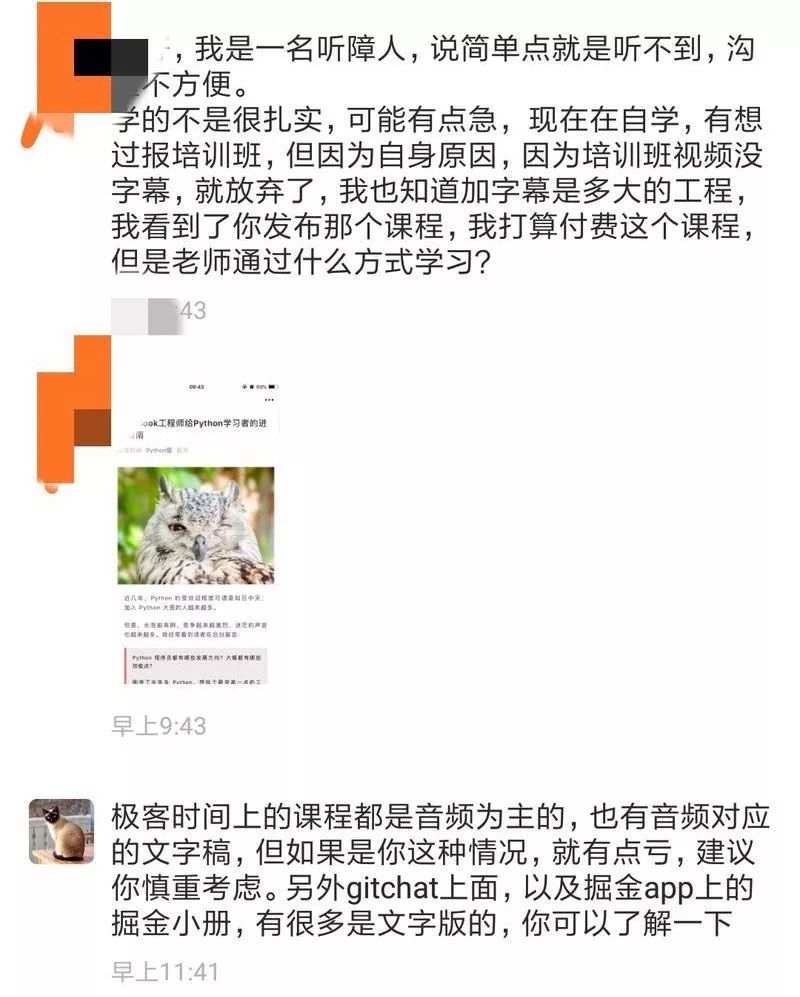
现在网络上有很多视频、音频课程,因为工作量或者时间关系,可能并不配备字幕或者文字稿。那么我们此次展示的视频特效,将语音识别速度和准确度提升一下,没准可以在这方面有所应用。
此外在直播 APP、网站中,除了画面特效,动态地识别主播语音并展示到直播字幕内容中,貌似也是个挺不错的点子。
代码下载
后台回复 对话框 获取代码文件下载链接。下载到的文件中, chat.png 是特效中展示的对话框图片,SimHei.ttf 是写入图片中文字的字体文件,shape 开头的 dat 文件是用来面部识别的文件。
运行代码时,只有检测到面部信息才会出现对话框。当检测到语音信息时,文件夹中会生成 wav 音频文件。按 Esc 键退出摄像头视频时,文件夹中会生成截图。
后记
这份代码的创作还挺神奇的,之前我就分别写过语音识别和视频特效的代码但并未联系起来。正好最近加了个学习 Python 的星球,其中有个用 Python 描述五一假期的题目:

作业截止日期是5月10号20:00,我在9号晚上看到有位球友的写法是将文字写入图片来展示,觉得特别有新意。再一联想之前自己尝试的视频特效,完全可以把文字贴到摄像头视频中。如果再加个对话框?这文字可不可以语音识别自动生成?一连串的问题和琢磨,终于赶在截止时间完成了这份代码。
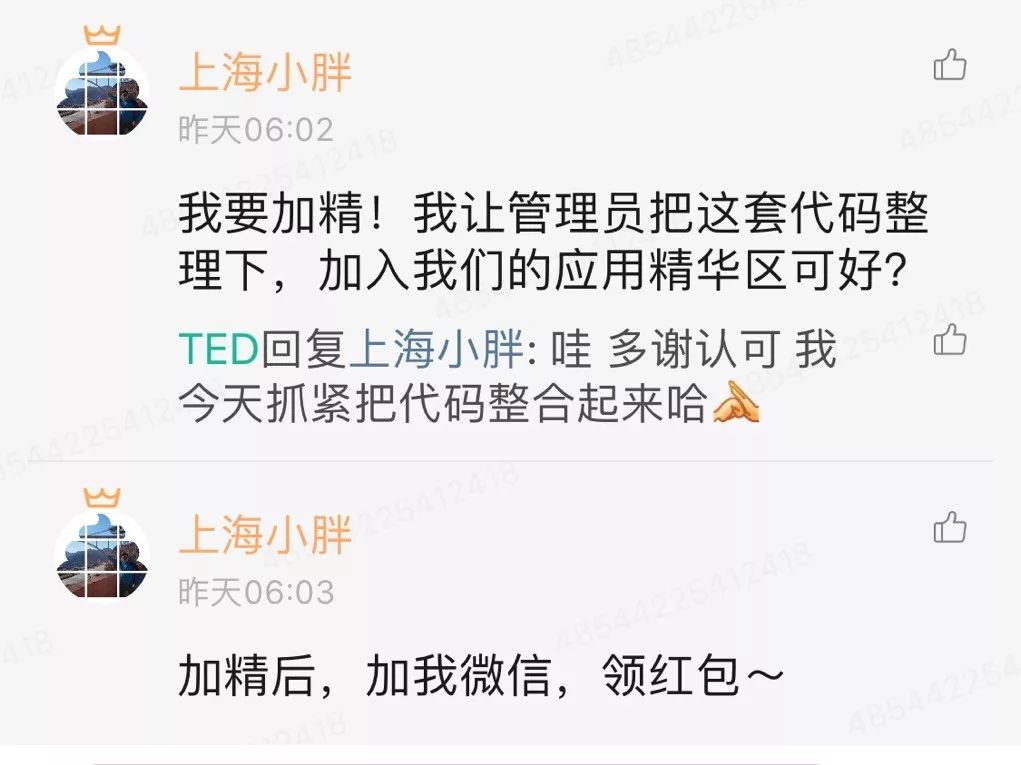
出乎意料地得到了星主肯定,美滋滋哈哈。最近工作有些忙,公众号好久没更,挺打脸的。没有自我感觉良好的内容也不好意思打扰各位,所以我会继续积累、争取分享更多有意思的内容~
如果感觉还不错,帮点个在看或者分享一下吧。给我一个向你的圈子展示的机会,这是对我最大的肯定了,感谢!
相关阅读
正常技术类:
Python 实时语音识别
沙雕特效类:
Python:变身超级赛亚人
Python:修炼写轮眼
Python:我的眼里只有你
以及 超越杯编程大赛前线报道 的结尾处视频特效















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









