







数据分析的核心就是要从数据中获取“信息”。近年来,随着数据量的增加,尤其是非结构化数据量的增加,通过传统分析方法,我们越来越难获得相关且理想的信息了,但如今,机器学习和自然语言处理领域已开发出一些强大的方法,可用于挖掘数据并获取正在寻找的信息。
主题模型(Topic Model)就是其中用于在一系列文档中发现抽象主题的一种统计模型。

不同于使用正则表达式或基于字典的关键字搜索技术的基于规则的文本挖掘方法,主题模型是一种无监督的方法,用于查找和观察大量文本集中的一堆单词(称为“主题”)。
这里的主题并不是也不需要是具体的,它可以定义抽象的“语料库中同时出现的术语的重复模式”。打个比方,假设我们有100个文本集合。在遍历每个文本后,发现其中有十个包含“机器学习”,“培训”,“监督”,“无监督”,“数据集”等词,这些词是什么意思并不重要,重要的是我们发现了100个文本中有10%包含了这些词,我们能够将这10篇文章归为同一“主题”。当我们得到从未见过的新文本时,主题模型就更加见效了,即使我们一个单词都看不懂,我们依旧可以得出结论:“啊!这10篇文章在讲同一个‘主题’!”
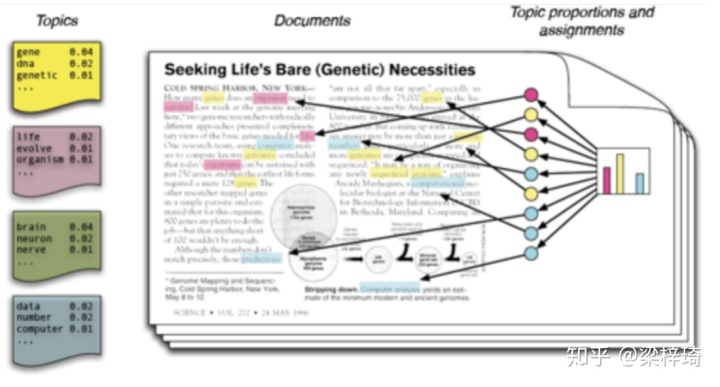
主题模型对于文档聚类,组织大量文本数据,从非结构化文本中检索信息以及选择都非常有用。例如,《纽约时报》就在使用主题模型来提升其用户–文章推荐引擎。在招聘行业中主题模型的使用也尤为频繁,猎头们通过提取职位描述的潜在特征,将其映射到合适的候选人上,这能有效提高他们的招聘效率和质量。除此之外,主题模型也被用于组织电子邮件,客户评论和用户社交媒体资料的大型数据集。
LDA:隐含狄利克雷分配
隐含狄利克雷分配是主题建模里最常见的模型之一,是David M. Blei、Andrew Y. Ng、Michael I. Jordan 在2003年提出的,目前在文本挖掘领域包括文本主题识别、文本分类以及文本相似度计算方面都有广泛应用。
LDA是一种典型的词袋模型(Bag of Words Model),它假设每个主题都是一组基础单词的混合,而每个文档都是一组主题概率的混合。即它认为一篇文档是由一组词构成的一个集合,词与词之间没有顺序以及先后的关系。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。
首先我们先从整体上感知一下LDA的生成过程:
给定M个文档,N个单词和先前K个主题,模型训练输出的是psi(每个主题的单词分布)以及phi(每个文档的主题分布)
其实,LDA主要运用的是矩阵分解技术和采样技术ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1949
1949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









