






整理自网络,整理/排版:付斌
不知大家有没遇到过像“横放着的金字塔”一样的 ifelse嵌套。过多的if else非常影响可读性,过多的if-else代码和嵌套,会使阅读代码的人很难理解到底是什么意思,尤其是没有注释的代码。
另外在可维护性上,因为if else特别多,想要新加一个分支的时候,就会很难添加,极其容易影响到其他的分支。 我不喜欢业务代码中航天飞机式if/else语句,它复杂而臃肿,至少从美感而言, switch就比if/else优雅很多. 如果跨语言比较的话, 私以为ReasonML的模式匹配比起寻常的switch语句又要强上太多. JS中对复杂判断的不同写法, 带来的感觉是很不同的, 这篇文章里, 我将简单介绍几种用于替代if/else的写法. 只有熟悉更多代码思路, 才能开阔我们的思维, 如果不能学习写代码的更多可能性, 也许我们就成了被代码控制住的人。


OK,熟练的程序猿应该已经发现Bug所在了,在第8行和第10行下面我没有添加关键字break; 这就导致这段代码的行为逻辑与我的设计初衷不符了。 缺点一. 语法正确,逻辑错误
这就是第一个理由为什么程序猿很少使用switch来做条件判断,对于新手来说忘记写break实在是再普通不过了,就算是老猿忘记写也是时有发生的事情,而这个语法错误在诸多的语法检查器上没有办法检查出来的,因为从语法角度来说是正确的!可是代码的处理逻辑却是错误的!用if来重写这段代码的话,就不会发生这种错误。
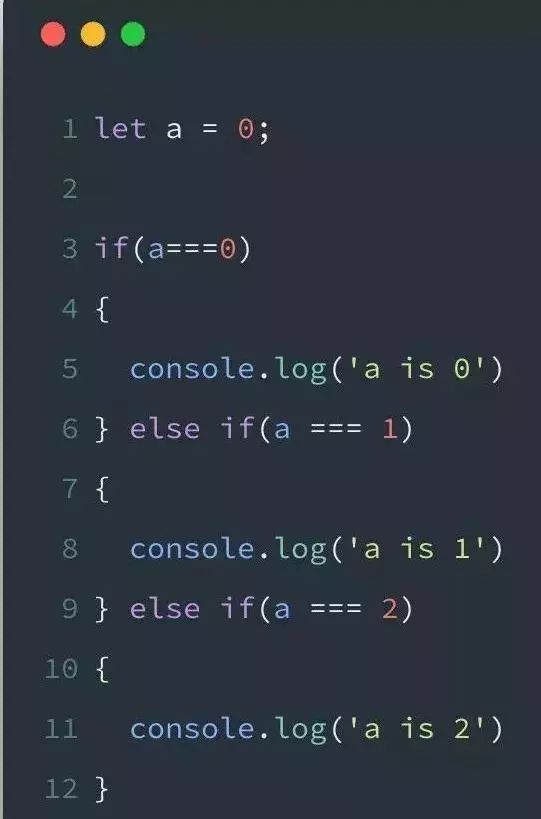
上面的代码为了保证正确我添加了else做一个逻辑上的保证,其实如果不写else,这段代码也不会发生逻辑错误,而且一旦我忘记写花括号的时候,语法编译器是会提示我添加的,甚至可以使用eslint这种的工具强制我使用花括号,这样就不会犯语法错误了,一旦出现bug,那么肯定是我逻辑上的问题了。
缺点二 .死板的语法
switch尽管对于break很宽容,但是对判断条件很严苛,case后面只能跟常量,如果你用C编写的话,甚至只能用int类型作为判断条件。对于我们这么潇洒自如的程序猿来说,这种限制实在是太麻烦了,用if的话,别说是常量了,我用函数都可以,真正做到方便快捷。
缺点三 .需要子函数来处理分支
这个缺点跟缺点一有关,为了防止漏写break,因此建议把分支处理方法独立成一个子函数来处理,这样在阅读代码的时候就会减少忘记写break带来的bug,那么用if来写的话,我想怎么写就怎么写,非常随意自由,但是这也导致了代码的可读性大大降低。 switch的优点
既然switch有这么严重的缺点,那怎么在所有语言中依然会存在呢?那就说下switch的优点吧,它的优点也刚好是它的缺点。
在很久很久以前,那时候的电脑性能还不如一台小霸学习机的时候,聪明的计算机科学家为了提高计算机的处理速度,将一些逻辑分支处理方法简化了一下,把一些需要做逻辑判断的操作给固定死,然后只要查表一样一个一个对一下就能做出相应的反应了。
比如说a=0的判断,switch和if在cpu上面的处理方式是不一样的,switch是在编译阶段将子函数的地址和判断条件绑定了,只要直接将a的直接映射到子函数地址去执行就可以了,但是if处理起来就不一样了。
它首先要把a的值放到CPU的寄存器中,然后要把比较的值放到CPU的另一个寄存器中,然后做减法,然后根据计算结果跳转到子函数去执行,这样一来就要多出3步的操作了,如果逻辑判断多的话,那么将会比switch多处许多倍的操作,尽管寄存器操作的速度很快,但是对于当时的学习机来说,这点速度根本不够用啊。 那还有一个问题,为什么要使用break来做一个判断结束呢?这不是很容易造成语法错误了?那就要说到子函数的问题上了。
在早起的电脑代码中是没有子函数的概念的,那时候都是用goto随意跳转的,你想去第10行代码,很简单goto 10就可以了。这种编程思维在C的早期阶段还是一直受到影响的,因此早期的C也没有子函数,都是一堆逻辑处理混乱在一起,goto满天飞,所以那时候你没有一个最强大脑是写不了程序的。那为了告诉程序我这里条件判断处理结束,就添加了break作为终止符号。后来慢慢的有了子程序,有了更好的编程规范,才一步一步的将写代码沦落到体力劳动。
后来发展的新语言为了标榜自己的血统,多少都要参考下C,然后就把switch这种诡异的语法也继承下来了。但是也不是所有的语言都照搬,比如Google发明的新语言golang和kotlin就又把switch包装了一下,去掉了令人误会的语法,又让switch变得灵活起来了,对了,在代码重构的时候,还是用switch把,这样看起来的确代码更简洁哦!
项目中的if else太多了,该怎么重构?
作者:crossoverJie
if else过多的话,一般都是用策略模式来进行重构,策略模式也非常的简单。先定义一个接口,各种处理分支实现这个接口,定义好 条件->处理类的映射关系,然后根据条件找到响应的处理类执行即可,当有新的分支的话,只需要增加一个接口实现类,增加一个条件->映射类的映射关系即可。还是很好容易理解的介绍
不出意外,这应该是年前最后一次分享,本次来一点实际开发中会用到的小技巧。
比如平时大家是否都会写类似这样的代码:

条件少还好,一旦 else if 过多这里的逻辑将会比较混乱,并很容易出错。
比如这样:
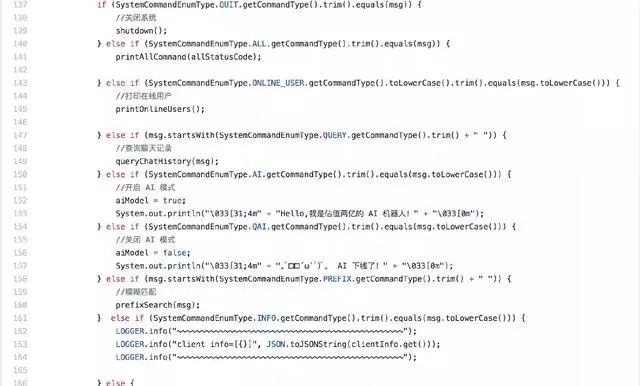
摘自 cim 中的一个客户端命令的判断条件。
刚开始条件较少,也就没管那么多直接写的;现在功能多了导致每次新增一个 else 条件我都得仔细核对,生怕影响之前的逻辑。
这次终于忍无可忍就把他重构了,重构之后这里的结构如下:
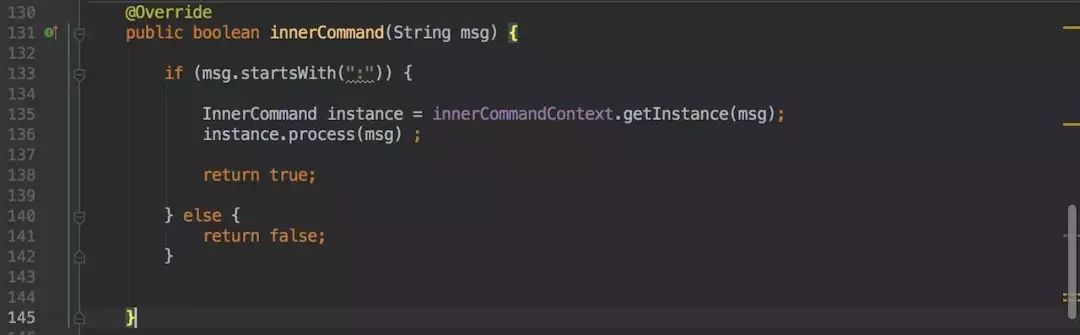
最后直接变为两行代码,简洁了许多。
而之前所有的实现逻辑都单独抽取到其他实现类中。
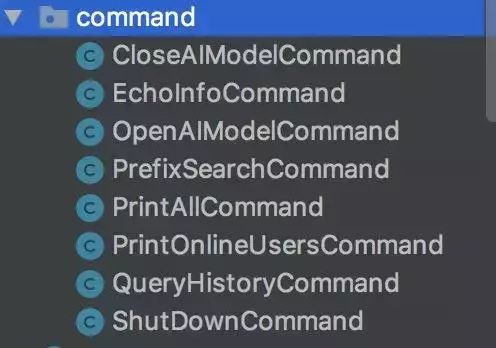
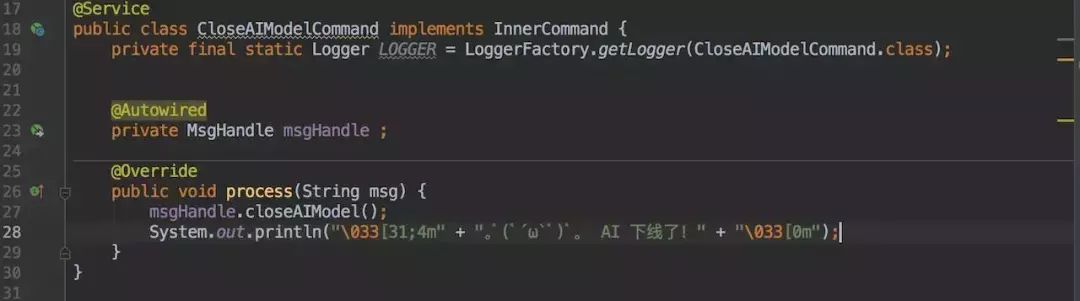
这样每当我需要新增一个 else 逻辑,只需要新增一个类实现同一个接口便可完成。每个处理逻辑都互相独立互不干扰。
实现
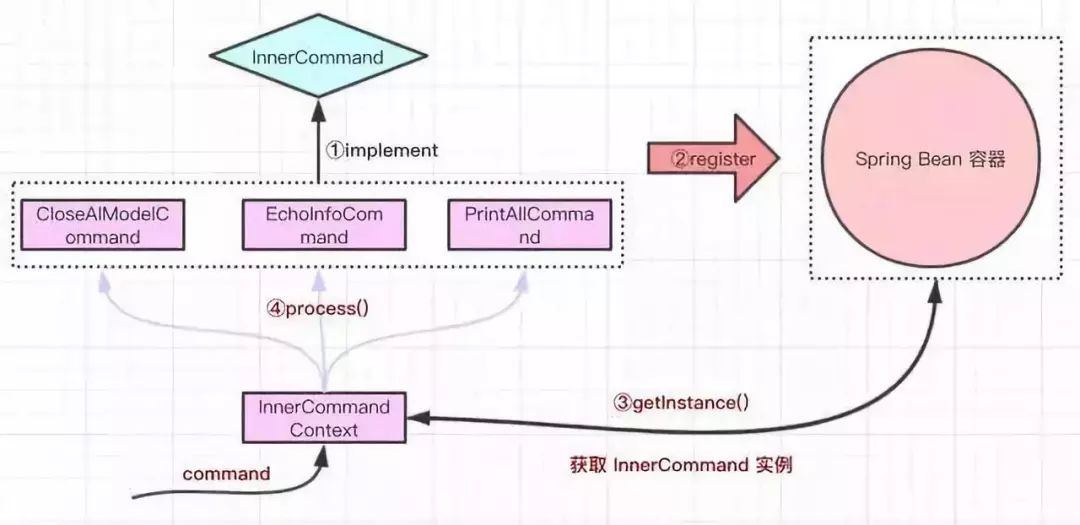
按照目前的实现画了一个草图。
整体思路如下:
- 定义一个 InnerCommand 接口,其中有一个 process 函数交给具体的业务实现。
- 根据自己的业务,会有多个类实现 InnerCommand 接口;这些实现类都会注册到 Spring Bean 容器中供之后使用。
- 通过客户端输入命令,从 Spring Bean 容器中获取一个 InnerCommand 实例。
- 执行最终的 process 函数。
主要想实现的目的就是不在有多个判断条件,只需要根据当前客户端的状态动态的获取 InnerCommand 实例。
从源码上来看最主要的就是 InnerCommandContext 类,他会根据当前客户端命令动态获取 InnerCommand 实例。
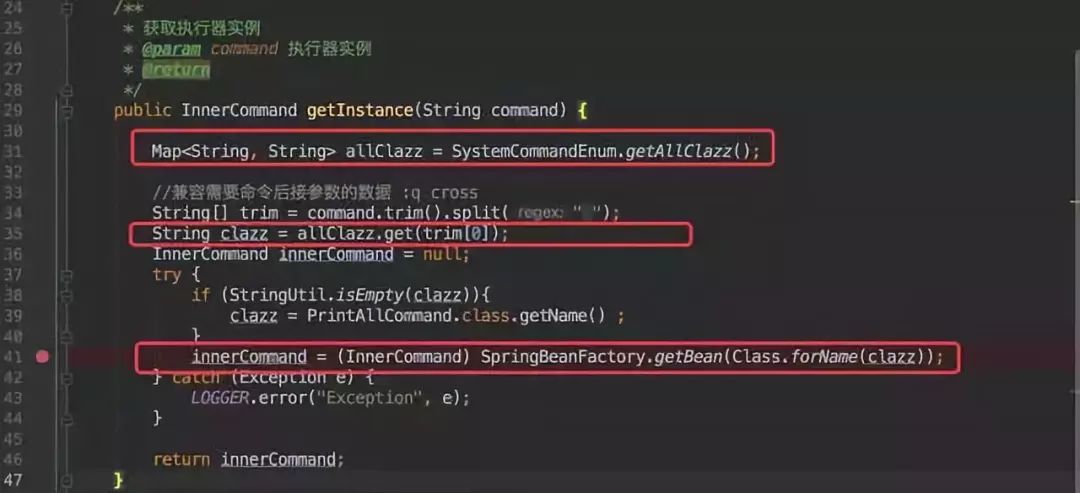
- 第一步是获取所有的 InnerCommand 实例列表。
- 根据客户端输入的命令从第一步的实例列表中获取类类型。
- 根据类类型从 Spring 容器中获取具体实例对象。
因此首先第一步需要维护各个命令所对应的类类型。

所以在之前的枚举中就维护了命令和类类型的关系,只需要知道命令就能知道他的类类型。
这样才能满足只需要两行代码就能替换以前复杂的 if else,同时也能灵活扩展。

总结
当然还可以做的更灵活一些,比如都不需要显式的维护命令和类类型的对应关系。
只需要在应用启动时扫描所有实现了 InnerCommand 接口的类即可,在 cicada 中有类似实现,感兴趣的可以自行查看。
这样一些小技巧希望对你有所帮助。 github地址:https://github.com/crossoverJie/cim 更多方法“干掉”if else
1. 最简单的计算器实现(示例1)
public class Main { public static void main(String[] args) { // 计算类型:1:加法 2:减法 3:乘法 4:除法 // 计算类型和计算的值都是正常客户端传过来的 int calcType = 1; int num1 = 1; int num2 = 3; // 计算器真正的实现 int result = 0; if (calcType == 1) { result = num1 + num2; } else if (calcType == 2) { result = num1 - num2; } else if (calcType == 3) { result = num1 * num2; } else if (calcType == 4) { result = num1 / num2; } System.out.println(result); }}- 计算类型使用了魔法值(就是写死的值),程序中应该避免直接使用魔法值,可以使用枚举类来优化;
- 计算器功能的每种操作非常简单,只需要对两个数字运算一下就完了,每个操作也就是一行代码的事,但实际开发过程中每种业务处理可能要几十行甚至更多行代码来完成,现在是4种类型,如果每种类型的业务需要100行代码,这四种就会有400行代码,这只是if else的代码量再加上该方法的其它代码可以想象该方法的代码量很大,我们需要控制方法的行数,一般通常控制到100行以内,我们可以通过将每个运算的具体实现都提取成一个单独的方法,这样一来就缩小每个if else的代码的行数,只需要一行代码,只需要调用一个方法就可以了。
2. 枚举类+提取方法实现(示例2)
- 增加一个枚举类CalcTypeEnum用于表示所有的运算类型, 使用枚举类来优化魔法值
- 将每种具体的运算实现提取为独立的方法
public enum CalcTypeEnum { ADD(1, "加法操作"), SUB(2, "减法操作"), MUL(3, "乘法操作"), DIV(4, "除法操作"), ; private Integer code; private String description; CalcTypeEnum(Integer code, String description) { this.code = code; this.description = description; } public Integer getCode() { return code; } public String getDescription() { return description; }}public class Main { public static void main(String[] args) { // 计算类型:1:加法 2:减法 3:乘法 4:除法 int calcType = 1; int num1 = 1; int num2 = 3; int result = 0; // 使用枚举来代替魔法值 if (CalcTypeEnum.ADD.getCode().equals(calcType)) { // 假如加法运算中还包含其它业务逻辑,那么这些逻辑也被封装到方法中了,此处只有一行的代码量 result = add(num1, num2); } else if (CalcTypeEnum.SUB.getCode().equals(calcType)) { result = sub(num1, num2); } else if (CalcTypeEnum.MUL.getCode().equals(calcType)) { result = mul(num1, num2); } else if (CalcTypeEnum.DIV.getCode().equals(calcType)) { result = div(num1, num2); } System.out.println(result); } /** 将具体的运算实现代码封装成独立的方法 */ public static int add(int num1, int num2) { System.out.println("加法运算其它业务逻辑start"); System.out.println("此处省略几十行代码..."); System.out.println("加法运算其它业务逻辑end"); return num1 + num2; } public static int sub(int num1, int num2) { return num1 - num2; } public static int mul(int num1, int num2) { return num1 * num2; } public static int div(int num1, int num2) { return num1 / num2; }}main方法属于客户端,加减乘除功能是具体的功能实现,用来提供服务,我们不能将服务和客户端代码写到一起,每个类的职责应该更明确,即服务提供方用于专门提供服务,客户端调用方用于调用服务。
3. 计算器功能单独封装成类(示例3)
我们将具体的功能单独封装到一个类中用于提供服务
public class Calculator { public int calc(CalcTypeEnum calcType, int num1, int num2) { int result = 0; if (CalcTypeEnum.ADD.equals(calcType)) { result = add(num1, num2); } else if (CalcTypeEnum.SUB.equals(calcType)) { result = sub(num1, num2); } else if (CalcTypeEnum.MUL.equals(calcType)) { result = mul(num1, num2); } else if (CalcTypeEnum.DIV.equals(calcType)) { result = div(num1, num2); } return result; } public int add(int num1, int num2) { System.out.println("加法运算其它业务逻辑start"); System.out.println("此处省略几十行代码..."); System.out.println("加法运算其它业务逻辑end"); return num1 + num2; } public int sub(int num1, int num2) { return num1 - num2; } public int mul(int num1, int num2) { return num1 * num2; } public int div(int num1, int num2) { return num1 / num2; }}public class Main { public static void main(String[] args) { int num1 = 1; int num2 = 3; Calculator calculator = new Calculator(); int result = calculator.calc(CalcTypeEnum.ADD, num1, num2); System.out.println(result); }}- 枚举类CalcTypeEnum增加乘方的枚举值
- 修改Calculator类,增加一个乘方的方法,然后在calc方法中再增加一个else if 块
该实现的最大的问题是当我们新增一种运算时除了要新增代码,还需要修改原来的calc代码,这不太好,我们希望新增运算功能时只需要新增代码,不要修改原来已有的代码。
4.将具体运算分别封装成单独的类中(示例4)
为了达到新增运算方式不修改代码只增加代码的方式,我们需要将每个预算继续抽象,我们新增一个计算的接口,并将加减乘除求余数分别封装到每个具体的实现类里面。
/** * 计算策略. * */public interface CalcStrategy { int calc(int num1, int num2);}/** * 加法操作 */public class AddStrategy implements CalcStrategy { @Override public int calc(int num1, int num2) { System.out.println("加法运算其它业务逻辑start"); System.out.println("此处省略几十行代码..."); System.out.println("加法运算其它业务逻辑end"); return num1 + num2; }}/** * 减法操作. */public class SubStrategy implements CalcStrategy { @Override public int calc(int num1, int num2) { return num1 - num2; }}/** * 乘法操作 */public class MulStrategy implements CalcStrategy { @Override public int calc(int num1, int num2) { return num1 * num2; }}/** * 除法操作 */public class DivStrategy implements CalcStrategy { @Override public int calc(int num1, int num2) { return num1 / num2; }}public enum CalcTypeEnum { ADD(1, "加法操作"), SUB(2, "减法操作"), MUL(3, "乘法操作"), DIV(4, "除法操作"), // 求余数运算 REM(5, "求余操作"), ;}/** * 求余操作 */public class RemStrategy implements CalcStrategy { @Override public int calc(int num1, int num2) { return num1 % num2; }}public class Main { // 用户要计算的类型 private static final int CALC_TYPE = 5; public static void main(String[] args) { // 根据用户要运算的类型调用相应实现类的方法 CalcStrategy calcStrategy = null; if (CalcTypeEnum.ADD.getCode().equals(CALC_TYPE)) { calcStrategy = new AddStrategy(); } else if (CalcTypeEnum.SUB.getCode().equals(CALC_TYPE)) { calcStrategy = new SubStrategy(); } else if (CalcTypeEnum.MUL.getCode().equals(CALC_TYPE)) { calcStrategy = new MulStrategy(); } else if (CalcTypeEnum.DIV.getCode().equals(CALC_TYPE)) { calcStrategy = new DivStrategy(); } else if (CalcTypeEnum.REM.getCode().equals(CALC_TYPE)) { calcStrategy = new RemStrategy(); } int result = calcStrategy.calc(10, 20); System.out.println(result); }}5. 为示例4引入上下文(示例5)
上下文只持有一个运算接口的引用并提供一个执行策略的方法,这里的方法实现也很简单,就是简单调用具体运算实现类的方法
public class CalcStrategyContext { // 运算接口 private CalcStrategy strategy; // 通过构造函数或者set方法赋值 public CalcStrategyContext(CalcStrategy strategy) { this.strategy = strategy; } public int executeStrategy(int a, int b) { // 简单调用具体实现对应的方法 return strategy.calc(a, b); } public CalcStrategy getStrategy() { return strategy; } public void setStrategy(CalcStrategy strategy) { this.strategy = strategy; }}public class Main { private static final Integer CALC_TYPE = 1; public static void main(String[] args) { CalcStrategy calcStrategy = null; if (CalcTypeEnum.ADD.getCode().equals(CALC_TYPE)) { calcStrategy = new AddStrategy(); } else if (CalcTypeEnum.SUB.getCode().equals(CALC_TYPE)) { calcStrategy = new SubStrategy(); } else if (CalcTypeEnum.MUL.getCode().equals(CALC_TYPE)) { calcStrategy = new MulStrategy(); } else if (CalcTypeEnum.DIV.getCode().equals(CALC_TYPE)) { calcStrategy = new DivStrategy(); } // 这里不再直接调用接口方法了,而是调用上下文类中的方法 // 上下文就是对接口的一种简单的装饰和封装 CalcStrategyContext context = new CalcStrategyContext(calcStrategy); int result = context.executeStrategy(20, 30); System.out.println(result); }}CalcStrategy#calc接口的方法,一个是调用
CalcStrategyContext#executeStrategy上下文中的方法,上下文中的方法也是简单的调用具体的实现类,在这里感觉上下文没太大的意义。
上下文存在的意义?
现在加入我们要实现一个促销的功能,假如目前支持 满x元减y元、第x件y折、满x件y折等多种促销方式,假如业务规定当满足多种促销时取所有促销的最低价。要想实现这种功能,我们首先找出当前订单能够享受的促销类型,然后分别计算每种促销类型促销后的促销价,然后比较所有促销类型对应的促销价,取最低的促销价格。
上下文中大部分情况下是直接调用调用接口的方法,但是也有一些情况是需要在上下文中处理一些逻辑,处理不同实现的依赖关系。
/** * 促销上下文 * @author Mengday Zhang * @version 1.0 * @since 2019-08-16 */public class PromotionContext { public BigDecimal executeStrategy() { BigDecimal promotionPrice = null; List promotionList = ...; for (PromotionStrategy strategy : promotionList) { // 执行下次运算需要将上次运算的结果作为下次运算的参数, // 每次计算的结果需要和传进来的上次运算结果做比较,取最小值作为新的结果返回 promotionPrice = strategy.executeStrategy(promotionPrice); } return promotionPrice; }}- 提供一个策略接口
- 提供多个策略接口的实现类
- 提供一个策略上下文
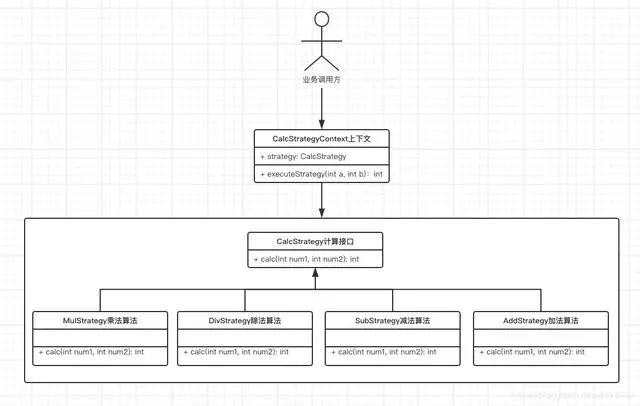
策略设计模式优点
- 可以自由切换算法(具体实现)
- 避免了多条件的判断(干掉了if else)
- 扩展性好可以定义新的算法提供给使用者(增加新功能时只需要增加代码而不需要修改代码)
策略设计模式缺点
- 算法类数量增多,每个算法都是一个类,这对于初级程序员比较难以接受
6. 通过枚举类撤掉干掉if else(示例6)
上个示例我们看到仍然有很多if else代码,我们需要减少甚至消灭这种代码,消灭if else这里列举两种方式,一种是通过配置枚举类。在枚举中增加对应的运算实现类,并提供一个根据code来获取对应的枚举类的方法, 获取到枚举类了就获取到对应的实现类了。
public enum CalcTypeEnum { // code 一般设置为具体实现类的前缀 ADD("Add", "加法操作", new AddStrategy()), SUB("Sub", "减法操作", new SubStrategy()), MUL("Mul", "乘法操作", new MulStrategy()), DIV("Div", "除法操作", new DivStrategy()), ; private String code; private String description; private CalcStrategy calcStrategy; CalcTypeEnum(String code, String description, CalcStrategy calcStrategy) { this.code = code; this.description = description; this.calcStrategy = calcStrategy; } // 根据code获取对应的枚举类型 public static CalcTypeEnum getCalcTypeEnum(String code) { for (CalcTypeEnum calcTypeEnum : CalcTypeEnum.values()) { if (calcTypeEnum.getCode().equals(code)) { return calcTypeEnum; } } return null; } public String getCode() { return code; } public String getDescription() { return description; } public CalcStrategy getCalcStrategy() { return calcStrategy; }}public class Main { private static final String CALC_TYPE = "Sub"; public static void main(String[] args) { // 消除if else,根据code获取到对应的枚举类,进而获取到对应的计算实现类 CalcStrategy addStrategy = CalcTypeEnum.getCalcTypeEnum(CALC_TYPE).getCalcStrategy(); CalcStrategyContext context = new CalcStrategyContext(addStrategy); int result = context.executeStrategy(20, 30); System.out.println(result); }}7. 通过反射彻底干掉if else(方式二)
我们将每个具体的实现类变成单例模式,这里通过懒汉模式来实现单例类。
/** * 加法操作 */public class AddStrategy implements CalcStrategy { private static AddStrategy addStrategy; private AddStrategy() { } // 懒汉模式实现单例类 public static AddStrategy getInstance() { if (addStrategy == null) { addStrategy = new AddStrategy(); } return addStrategy; } @Override public int calc(int num1, int num2) { System.out.println("加法运算其它业务逻辑start"); System.out.println("此处省略几十行代码..."); System.out.println("加法运算其它业务逻辑end"); return num1 + num2; }}public class CalcStrategyUtils { public static CalcStrategy getCalcStrategy(String calcType) { try { // 这里包名是写死的,开发时需要将实现类统一放到该包下面,类的命名也是有规则的,以Strategy作为后缀 String path = "com.example.design.strategy.demo7." + calcType.concat("Strategy"); Class> clazz = Class.forName(path); CalcStrategy instance = (CalcStrategy) clazz.getDeclaredMethod("getInstance").invoke(null, null); return instance; } catch (Exception e) { e.printStackTrace(); throw new RuntimeException("Load [" + calcType.concat("Strategy") + "] Error :", e); } }}public class Main { private static final String CALC_TYPE = "Add"; public static void main(String[] args) { // 通过反射获取到具体实现类型,从而消除if else CalcStrategy addStrategy = CalcStrategyUtils.getCalcStrategy(CALC_TYPE); CalcStrategyContext context = new CalcStrategyContext(addStrategy); int result = context.executeStrategy(20, 30); System.out.println(result); }}
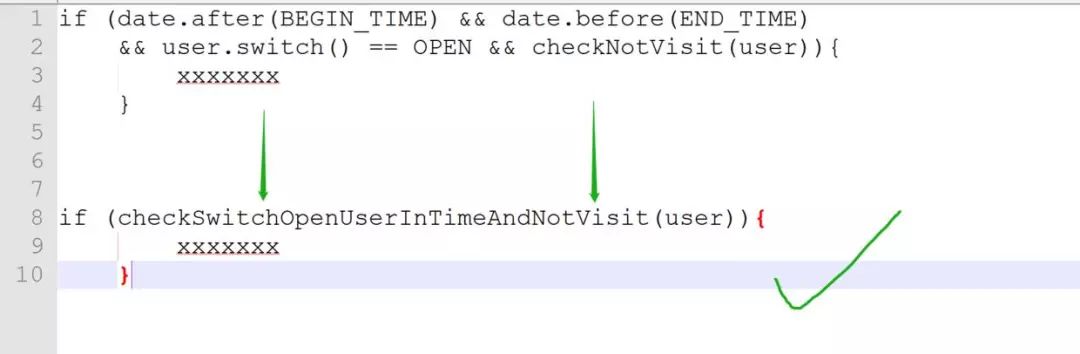 第一种写法,阅读代码的人很难第一眼就看到这个逻辑要做什么,而第二段代码,开发人员可以从函数名称就能阅读到。让你来看代码,你喜欢看哪一个呢?
第一种写法,阅读代码的人很难第一眼就看到这个逻辑要做什么,而第二段代码,开发人员可以从函数名称就能阅读到。让你来看代码,你喜欢看哪一个呢?
合并重复片段 在if语句种,代码会变成不同的分支,但是,有一些是走完这个分支之后,又会走相同的逻辑。有些程序员为了写代码方便,复制粘贴就是干,没有把重复的代码进行分离,我们看下面这样一个例子。
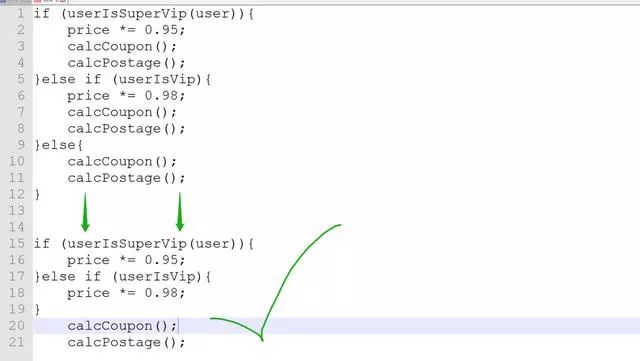 计算完会员价跟超级会员价之后,都要计算优惠券跟运费这样的逻辑,有些人写代码就喜欢CopyPaste,把计算优惠券的跟运费的代码也复制了一遍,示例中只是调用2个方法,直接抄300行一模一样的代码都随处可见。阅读上面的代码,会给你一种错觉,会员跟超级会员,使用优惠券跟计算运费都是另一套特殊的逻辑。
合并表达式条件
计算完会员价跟超级会员价之后,都要计算优惠券跟运费这样的逻辑,有些人写代码就喜欢CopyPaste,把计算优惠券的跟运费的代码也复制了一遍,示例中只是调用2个方法,直接抄300行一模一样的代码都随处可见。阅读上面的代码,会给你一种错觉,会员跟超级会员,使用优惠券跟计算运费都是另一套特殊的逻辑。
合并表达式条件
如果多个判断条件表达的是同一个意思,那么就不要拆成多个if的形式。举一个简单的例子,判断一张优惠券是否在使用时间内。第二种写法明显就优于第一种写法,第一种显得太过拖沓,虽然也能看懂。
 使用多台代替条件表达式
我见过的最恶心的代码,是一个商城优惠活动的,写了4000多行,包含十多种不同的活动。参与一口价一个if进去,几百行后才出来,参与买一送一的,一个if进去,几百行后才出来。这种祖传代码,谁维护谁知道,这种情况下,我们更应该使用多态来维护。
使用多台代替条件表达式
我见过的最恶心的代码,是一个商城优惠活动的,写了4000多行,包含十多种不同的活动。参与一口价一个if进去,几百行后才出来,参与买一送一的,一个if进去,几百行后才出来。这种祖传代码,谁维护谁知道,这种情况下,我们更应该使用多态来维护。
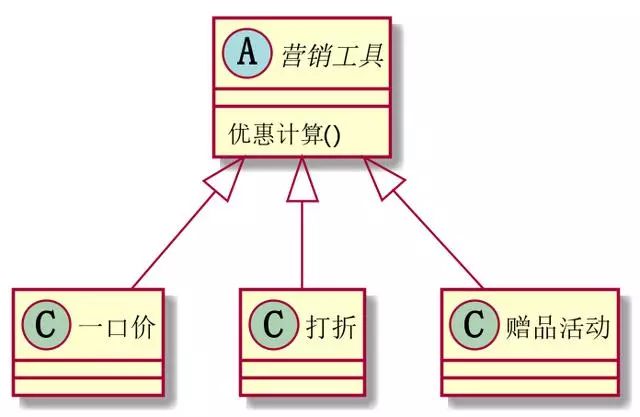 当使用多台之后,我们可以使用工厂设计模式或者迭代器设计模式,就能非常简单清晰地写代码。并且改代码的风险优惠小很多。
当使用多台之后,我们可以使用工厂设计模式或者迭代器设计模式,就能非常简单清晰地写代码。并且改代码的风险优惠小很多。
总结 大家不要老是觉得写代码就是复制粘贴,一个程序员的大部分时间,除了花在改需求上面,不是查问题就是调试,垃圾代码真的让你如履薄冰。在华为,因为项目都非常大跟复杂,所以代码规范会更加重要。今天,多注意一些规划可能会多花你10分钟的时间,后面可以节省的时间可能是数十倍的。
-END-
推荐阅读
【01】为什么在C语言中,goto这么不受待见? 【02】“C/C++中char* 和 char「」区别 【03】C语言结构体(struct)最全的讲解(万字干货) 【04】还没搞懂C语言指针?这里有最详细的纯干货讲解(附代码) 【05】码了一年才懂:C++深入理解浅拷贝和深拷贝 免责声明:整理文章为传播相关技术,版权归原作者所有,如有侵权,请联系删除















 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









