





解读代码:https://github.com/bojone/bert4keras/blob/master/pretraining/roberta/data_utils.py
首先是读取文本数据:

读取每个文件,文件中每一行是一个json字符串,json解析成dict,取出其中的"text"字符串,表示当前文章的文本。然后对每篇文章进行正则分句,一篇文章的很多句存储到texts列表中。因此,texts存储的是单句的数据。这样,一篇文章就处理完毕了,文章数count加1,当处理了10篇文章后,yield texts。因此,每次给到后续的数据是:10篇文章的单句list。
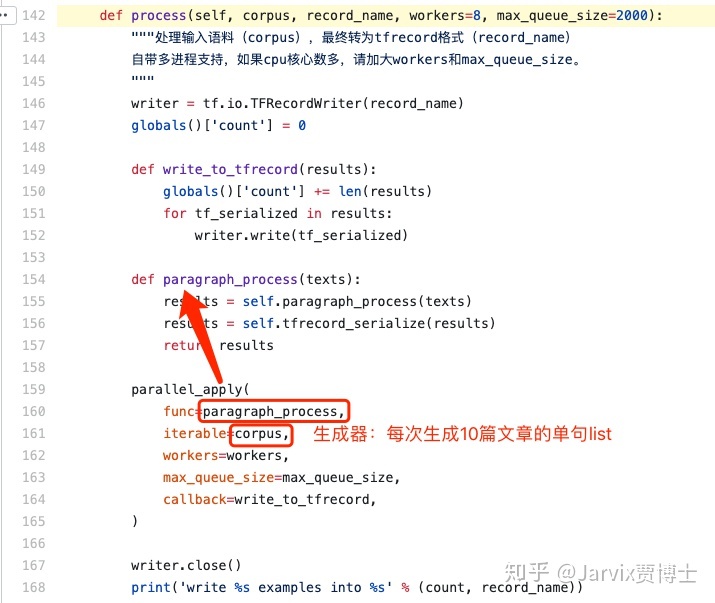
有了数据后,这些数据的处理函数是self.paragraph_process定义的,是最关键的部分(后面的self.tfrecord_serialize只是例行写入成tfrecord文件而已)。
这里我们看到,write_to_tfrecord()将每天数据依次write,就类似于File文件的write一样。如果生成器不停的生成数据(每次都是10篇文章的所有单句),直到生成器停止,也就是所有文档全部读取过一次后,整个写过程结束,就生成一个完整的tfrecord文件了。后面会看到,为了生成bert训练数据,一共把全数据重复读取了10次,也就生成了10个这样的tfrecord文件。

这里看一下单句的处理。首先进入self.sentence_process函数

word_segment这里作者采用的是jieba分词,得到分词结果words列表。
为每个词对应的生成一个随机数,0~1之间的。
然后是遍历所有的words,每个word会被bert分词器按vocab中存在的字符分成更小的字符level也就是word_tokens,并得到对应在vocab中的id,也就是word_token_ids
把word_token_ids追加到该单句的token_ids中(字符级别的,而不是单词级别的)。
然后看这个word的rand值,此时mask_rate=0.15就是说,整个句子中有15%的词可能被mask掉。如果正巧,当前word不被mask掉,则每个字符对应的word_mask_ids都是0;如果当前word要被mask掉(当前word可能含有多个字符),则依次处理每个字符(要么字符不变,要么变成[MASK],要么随机字符)
注意,这里之所以self.token_process(i)后要+1,是因为0已经用了,用于mask的标志位,真正存在于词表的字符应该从1开始往后,因此要+1。
这样一来,我们就知道了token_ids是当前单句的字符level的ids,mask_ids的长度和token_ids一样,它中间大部分都是0,非0的部分是词表id+1

sentence_process之后,看到_token_ids和_mask_ids都只取了512-2=前510的字符。
- 如果单句长度<=510,这样截取无影响
- 如果单句长度=511,截掉了句子的最后一个字符(为了之后要在开头和结尾增加[CLS]和[SEP])
- 如果单句长度=512,截掉了句子的最后两个字符
- 如果单句长度>=513,截掉了句子最后的n个字符。。。
反正截取后最大长度=seq_len-2
这里要搞清楚,mask_ids存储的是之前多个句子的一个个字符,而_mask_ids存储的是当前句子的一个个字符。如果把当前的句子字符append到之前的总list后,发现超出了最大长度,那肯定就不选择append当前句子,而是把之前token_ids做一个”了断“,放入到results中。因此,我们可以知道,results中的每个成员,其最大文本长度都限制在512里了。如果处理完10篇文章的所有单句后,发现还有token_ids不为空,则再往results中添加一次。
results就是10篇文章所有单句按照512、512、512...一直这样填补多句直到512长度的结果。
然后,把这每份512的token_ids和mask_ids写入tfrecord

还要特别注意下加载tfrecord函数。我们刚才往tfrecord文件中写入了每个样本的token_ids和mask_ids,加载时要把它们拿出来。
segment_ids肯定是全0的,因为不存在second sentence
is_masked是bool tensor,只要mask_ids!=0的位置都会被置为True。
如果是True,masked_token_ids就会变成mask_ids-1(因为刚才+1了所以要-1),要么是[MASK],要么是随机字符,要么是原始字符;如果是False,说明没有被mask,则还是原始的token_id
因此,模型的输入就是masked_token_ids,模型的目标是token_ids,这样就完成了Masked LM任务的数据预处理。















 3086
3086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









