






提要:
- 为什么要进行多层线性回归
- 多层线性回归的一般形式
- 固定效应
- 随机效应
- 多层线性回归在R语言中的实现
请想象如下场景:为了研究学生家庭收入对其成绩的影响,你从10个学校里分别抽取了100名学生,共1000名进行了调查。最后,你通过简单回归分析,得出学生家庭收入对成绩的影响是正向的。你的统计方法正确吗?
答案是:不正确。

- 为什么要进行多层线性回归
1.1 一般线性模型(general linear model)中的误差独立假设
一般线性模型(general linear model)中的误差独立假设,指的是在样本中的每一个观测的误差之间,不能存在相关。这一假设,可以理解为研究中的观测必须是相互独立的,否则就说明观测存在浪费,你的样本量是被高估的。我们知道,样本量越大,测量越容易显著。所以,一旦误差独立假设被违反,会增加假阳性的几率。
在之前的情境中,同一学校里的同学们成绩之间的相关,很可能是大于不同学校学生之间成绩的相关的。比如,可能在某个学校教学质量高,所以它的学生成绩都在平均水平之上,而另一些学校的学生可能都在平均水准之下。这就违反了误差独立假设,因为对同一学校学生的测量误差是相关的。在统计中,内部一致性高于外部一致性的集合,如上面情景中的“学校”,可以被成为一个聚类(cluster)。而包含聚类的数据集,就是嵌套数据集(nested data)。
1.2 几种分析嵌套数据集的方法
- 使用一般线性模型
如前所述,嵌套数据集的特点就是在同一聚类中的观测是相关的。这也就导致了如果使用一般线性模型,假阳性的几率会升高。而使用一般线性模型,也无法分析不同层级(如群体水平和个体水平)变量之间的关系。
- 先取同一聚类的平均数,再进行一般线性回归
这种方式的好处是消除了观测之间的相关,确保了误差独立假设,降低了假阳性概率。但是,将同一聚类的观测平均意味着大量样本量的丧失。同时,将个体平均化也意味着个体差异的抹杀,我们也只能研究聚类水平(如学校水平)变量,而不能研究个体水平变量了。
- 使用多层线性回归
使用多层线性回归的好处,就是在不浪费样本,可以研究个体差异的同时,也确保了误差独立假设不被违背。而多层线性回归的坏处,就是需要对更多的参数进行估计,所以需要更多的样本量来确保统计检验力(power)。
2. 多层线性回归的一般形式
我们都知道,一般线性模型的普遍形式为:
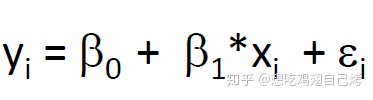
其中,y(i)学生 i 的成绩,x(1i)表示学生 i 的家庭状况,beta(0)即为截距,指的是当学生家境为平均水平时学生的成绩(在这里,我们假设已经对家境进行了中心化处理以便更好的解释结果),beta(1)为斜率,指家境对成绩的影响,epsilon(i)表示的是随机误差。
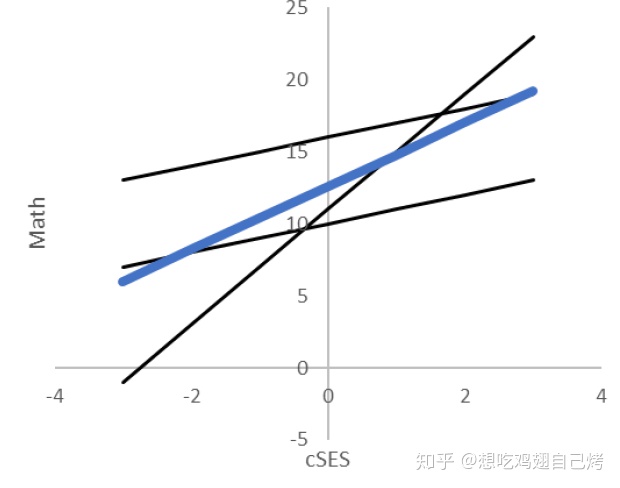
如前所述,可能有的学校教学质量高,学生更加优秀,这些学校的斜率,就比样本的平均水平高(即截距高于平均截距),而可能有的学校可能非常势力,只看重家境好的学生的学习,所以在这些学校里家境对成绩的影响就特别大(即斜率高于样本平均斜率)。如下图所示,蓝线为样本平均模型,拥有平均斜率(~1.75)和平均截距(~12)。而有的线截距高于平均(~15),有的线斜率高于平均(~4)这种情况,在一般线性模型中是很难捕捉到的,这时候我们就需要多层模型。
多层线性回归,在一般线性模型的基础上添加了分层:
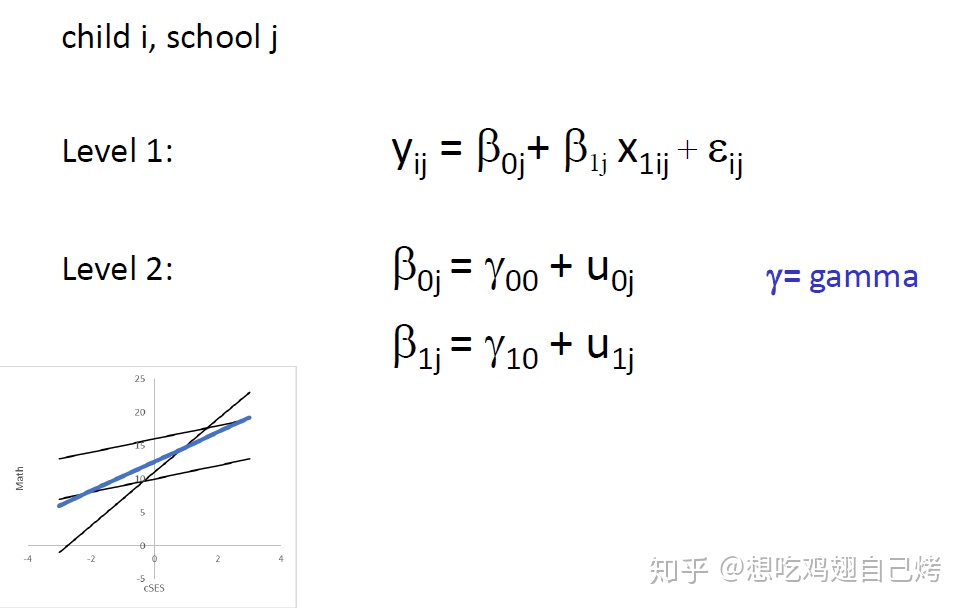
其中,y(ij)表示在学校 j 的学生 i 的成绩,x(1ij)表示在学校 j 的学生 i 的家庭状况,beta(0j)即为截距,beta(1j)为斜率,epsilon(ij)表示的是模型对在学校 j 的学生 i 的成绩的预测误差。
我们可以注意到,在第一水平的公式与一般线性模型的公式完全一致。我们只是添加了level 2的部分。gamma(00)表示的是固定截距,指在所有学校中截距共有的部分,即样本平均截距。而u(0j)表示的就是学校 j 的截距与平均截距(gamma(00))的误差。比如,学校1的截距就是gamma(00)+u(01);gamma(10)表示的是固定斜率,指在所有学校中斜率共有的部分,即样本平均斜率。而u(1j)表示的就是学校 j 的斜率与平均斜率(gamma(10))的误差。比如,学校1的的斜率就是gamma(10)+u(11)。
这样,每个学校独特的斜率和截距,就都可以考虑进去了。
在上述模型中,gamma(00),gamma(10)这样在第二水平上不变的效应,被称为固定效应(fixed effects),而u(0j)和u(1j)这样在第二水平上变化的效应,被称为随机效应(random effects)。
3. 多层线性回归在R中的实现
我们将使用nlme包中的MathArchive数据库进行分析
library(nlme)
mydata <- MathArchive
目前最常用的两个进行多层线性回归的R包是nlme和lme4。nlme使用的函数是lme(),而lme4使用的函数是lmer()
lme(fixed, random, data, correlation, weights, subset, method, na.action, control, contrasts = NULL, keep.data = TRUE)
应用到本情景(实际上将SES中心化更好一些,但是这和本文内容关系不大):
fit_lme <- lme(fixed = y ~ 1+ SES, random = ~ 1 + SES | school, data = mydata)
summary(fit_lme)
fixed = math~1+ SES中的 1代表的是截距gamma(00),而SES代表的是斜率,即家境对成绩的影响,gamma(10)。而random = ~ 1+SES中的1代表添加u(0j),SES代表添加u(1j)。| school代表的是学校编码
lmer(formula, data, family = NULL, REML = TRUE, control = list(), start = NULL, verbose = FALSE, doFit = TRUE, subset, weights, na.action, offset, contrasts = NULL, model = TRUE, x = TRUE,...)
应用到本情景:
library(lme4)
fit_lmer <- lmer(y ~ 1+ SES + (1 + SES | school), data = mydata)
summary(fit_lmer)
在接下来的系列中,我会继续讲解有关多层线性回归更多的内容,同时探索lme()和lmer()中的剩余命令。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









