







 本文介绍了MultiMedBench,一个多模式生物医学基准,包含14个任务,旨在评估通用AI在医学领域的性能。Med-PaLMM作为概念验证,展示了在多模态任务上的卓越表现,包括图像分析、基因组学和医疗报告生成。研究还展示了模型的零概率泛化和临床实用性潜力。
本文介绍了MultiMedBench,一个多模式生物医学基准,包含14个任务,旨在评估通用AI在医学领域的性能。Med-PaLMM作为概念验证,展示了在多模态任务上的卓越表现,包括图像分析、基因组学和医疗报告生成。研究还展示了模型的零概率泛化和临床实用性潜力。
摘要:
医学本质上是多模式的,具有丰富的数据模式,包括文本、成像、基因组学等。灵活编码、集成和大规模解释这些数据的通才生物医学人工智能(AI)系统可以潜在地实现从科学发现到医疗服务等有影响力的应用。为了使这些模型的发展,我们首先策划了MultiMedBench,这是一个新的多模式生物医学基准。MultiMedBench包含14个不同的任务,如医学问题回答,乳房x线摄影和皮肤病学图像解释,放射学报告生成和总结,以及基因组变体调用。然后我们介绍Med-PaLM Multimodal (Med-PaLM M),这是我们对通用生物医学人工智能系统的概念验证。Med-PaLM M是一个大型多模态生成模型,可以灵活地编码和解释生物医学数据,包括临床语言、成像和基因组学,具有相同的模型权重集。Med-PaLM M在所有MultiMedBench任务上达到了与最先进的性能竞争或超过最先进的性能,通常远远超过专业模型。我们还报告了零概率泛化到新的医学概念和任务、跨任务的正迁移学习和紧急零概率医学推理的例子。为了进一步探索Med-PaLM的能力和局限性,我们对模型生成(和人类)胸部x射线报告进行了放射科医生评估,并观察到在模型尺度上令人鼓舞的表现。在246张回顾性胸部x光片的并列排名中,临床医生在高达40.50%的病例中对Med-PaLM M报告的偏好超过放射科医生的报告,这表明了潜在的临床实用性。虽然在实际用例中验证这些模型还需要大量的工作,但我们的研究结果代表了多面手生物医学人工智能系统发展的一个里程碑。
贡献点:
1.我们推出MultiMedBench,这是一个新的多模式生物医学基准,跨越多种模式,包括医学成像、临床文本和基因组学,具有14种不同的任务,用于培训和评估通才生物医学人工智能系统。
2.Med-PaLM M是一个多任务、多模式的生物医学人工智能系统,可以使用相同的模型权重集进行医学图像分类、医学问题回答、视觉问题回答、放射学报告生成和汇总、基因组变体调用等。Med-PaLM M在MultiMedBench的多个任务上达到与最先进的(SOTA)专业模型竞争或超过最先进的性能,而无需任何特定于任务的定制。
3.除了任务绩效的定量评估之外,我们还观察到zero-shot医学推理,对新医学概念和任务的概括以及任务间的正迁移的证据。这些实验表明,这种系统在下游数据稀缺的生物医学应用中具有很大的潜力。
4.除了自动化指标外,我们还对Med-PaLM M在不同模型尺度上生成的胸部x射线报告进行放射科医生评估。在246张回顾性胸部x光片的盲法并列排名中,临床医生表示,在高达40.50%的病例中,对Med-PaLM M报告的偏好超过放射科医生的报告。此外,最好的Med-PaLM M模型平均每份报告有0.25个临床显著错误。这些结果与先前研究的人类基线相当,提示潜在的临床应用。
MultiMedBench:通用生物医学AI的基准
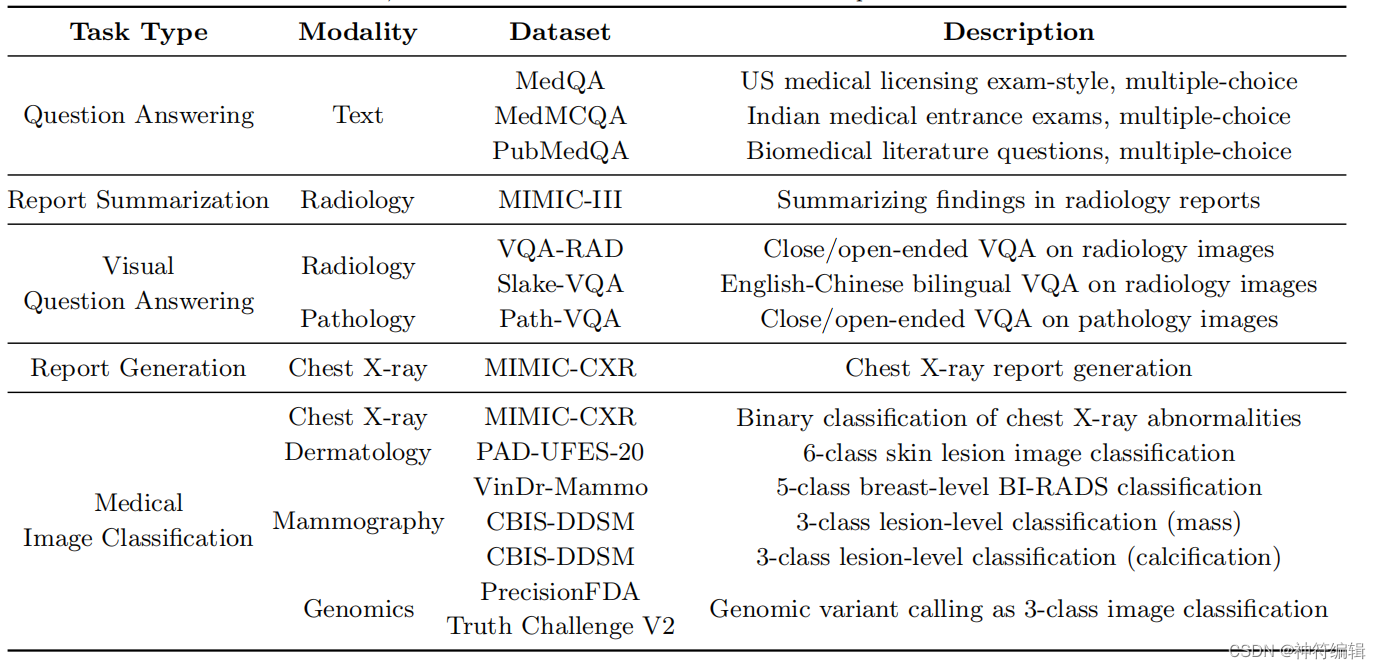
MultiMedBench是一个多任务、多模式的基准测试,包括12个去识别的开源数据集和14个单独的任务。它衡量了通用生物医学人工智能执行各种临床相关任务的能力。该基准涵盖了广泛的数据源,包括医学问题、放射学报告、病理学、皮肤病学、胸部x射线、乳房x光检查和基因组学。
任务类型:问题回答、报告生成和总结、视觉问题回答、医学图像分类和基因组变体调用。
模式:文本,放射学(CT, MRI和x射线),病理学,皮肤科,乳房x光检查和基因组学。
输出格式:所有任务的开放式生成,包括分类。
MultiMedBench包括5种任务类型的14个独立任务和跨越7种生物医学数据模式的12个数据集。该基准总共包含超过100万个样本。纯语言任务包括医学问题回答,包括Singhal等人中使用的三个MultiMedQA任务,以及放射学报告总结。他们被挑选出来评估模型理解、回忆和操纵医学知识的能力。多模态任务包括医学视觉问题回答(VQA)、医学图像分类、胸部x光报告生成和基因组变体调用,这些任务非常适合评估这些模型的视觉理解和多模态推理能力。表1概述了MultiMedBench中的数据集和任务——基准测试总共包含超过100万个样本。有关各个数据集和任务的详细描述,请参见章节A.1。如下图。
Med-PaLM M:通用生物医学人工智能的概念验证
Med-PaLM M有以下结构构成:注意,Med-PaLM M不仅继承了这些预训练模型的体系结构,还继承了编码在模型参数中的一般领域知识。
指令任务提示和一次性实例:我们的目标是训练一个通用的生物医学人工智能模型,使用统一的模型架构和一组模型参数来执行具有多模态输入的多个任务。为此,我们通过指令调优同时使用不同任务的混合训练模型。具体来说,我们为模型提供了特定于任务的指令,以提示模型在统一的生成框架中执行不同类型的任务。任务提示符由一条指令、相关上下文信息和一个问题组成。例为了使模型能够更好地遵循指令,对于大多数任务,我们在任务提示符中添加了一个纯文本的“一次性范例”,以调节语言模型的预测。一次性示例帮助用部分输入-输出对提示模型。重要的是,对于多模态任务,我们用一个虚拟文本占位符(文本字符串“<img>”)替换了范例中的实际图像:这(i)保留了单图像训练的训练计算效率,并且(ii)绕过了来自多个图像的给定文本令牌和图像令牌之间交叉注意的潜在干扰。我们的结果表明,该方案在提示模型生成所需的响应格式方面是有效的。
模型训练:我们对MultiMedBench任务上PaLM-E预训练的12B、84B和562B参数变体进行了微调。这些混合比率是根据经验确定的,因此它们与每个数据集中的训练样本数量近似成正比,并确保每个任务中至少有一个样本存在于一个批次中。在训练期间更新整个模型参数集,对PaLM-E模型进行微调。对于多模态任务,图像标记与文本标记相互交织,形成PaLM-E模型的多模态上下文输入。对于所有调优任务,多模态上下文输入最多包含一个图像。然而,我们注意到Med-PaLM M能够在推理过程中处理具有多个图像的输入。我们使用动量为β1 = 0.9,dropout为0.1的Adafactor优化器[58],并采用恒定的学习率调度。在我们的微调实验中,针对不同的模型大小,我们使用了不同的超参数集。由此产生的模型Med-PaLM M (12B、84B和562B)适用于生物医学领域,具有编码和解释多模态输入的能力,并执行包括医学(视觉)问题回答、放射学报告生成和总结、医学图像分类和基因组变体调用在内的任务
实验结果:总之,最好。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









