





基于Requests和Ajax分析法的新浪微博内容及用户信息爬取
1 项目介绍
新浪微博:新浪微博是一个由新浪网推出,提供微型博客服务类的社交网站。
用户可以通过网页、WAP页面、手机客户端、手机短信、彩信发布消息或上传图片。新浪可以把微博理解为“微型博客”或者“一句话博客”。
用户可以将看到的、听到的、想到的事情写成一句话,或发一张图片,通过电脑或者手机随时随地分享给朋友,一起分享、讨论;还可以关注朋友,即时看到朋友们发布的信息。
本项目进行了新浪微博-个人主页的所有微博信息采集。以“新浪微博-个人主页的所有微博信息采集”为例。在实操过程中,可根据自身需求,更换新浪微博的其他内容进行数据采集。
2 页面分析
2.1 需求分析
爬取的网址: https://weibo.com/u/5305630013
获取的博主信息:
微博博主名称,博主关注数量,博主粉丝数量,博主地址,博主个人简介,博主个人标签。
获取该博主的博客信息:
微博名称,微博发布时间,微博发布内容
2.2 找出微博用户的微博内容api
2.2.1 页面元素审查
一般做爬虫爬取网站时,首选的都是m站,其次是wap站,最后考虑PC站,因为PC站的各种验证最多。当然,这不是绝对的,有的时候PC站的信息最全,而你又恰好需要全部的信息,那么PC站是你的首选。一般m站都以m开头后接域名, 我们这次通过http://m.weibo.cn去分析微博的HTTP请求。
首先在PC打开微博主页:Python开发者微博主页
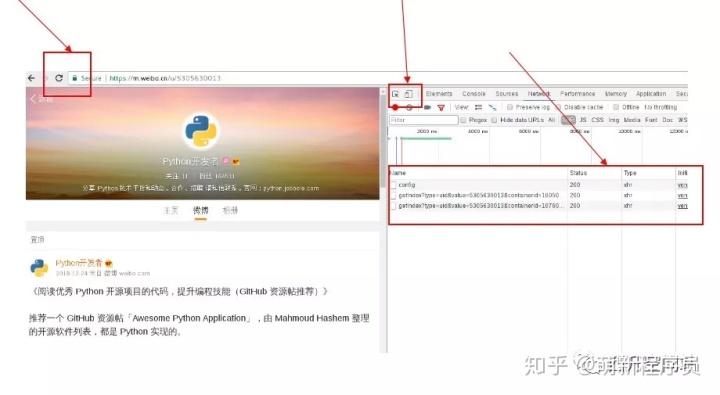
接着打开调试页面(F12,或右击检查),先选中右侧手机模式,然后刷新页面,这个时候就出来了m站微博主页:
https://m.weibo.com/p/id, 也有些是m站微博主页为:https://m.weibo.com/u/id;
注意:
1)当你打开一个页面,再点开network标签时是不会有信息的,我们需要在打开的情况下,刷新一下页面;
2)为了防止页面突然的跳转而丢失信息,一定要勾上preserved单选框。
2.2.2 XHR过滤获取API
选择XHR进行过滤,发现有两个已经发送的api请求。(api请求一般都在XHR中,其他网页请求在Doc)
我们查看这两个api返回的数据发现,第一个api返回的是用户数据,第二个api返回的是微博内容数据。
根据测试发现真实的url可以删减一部分
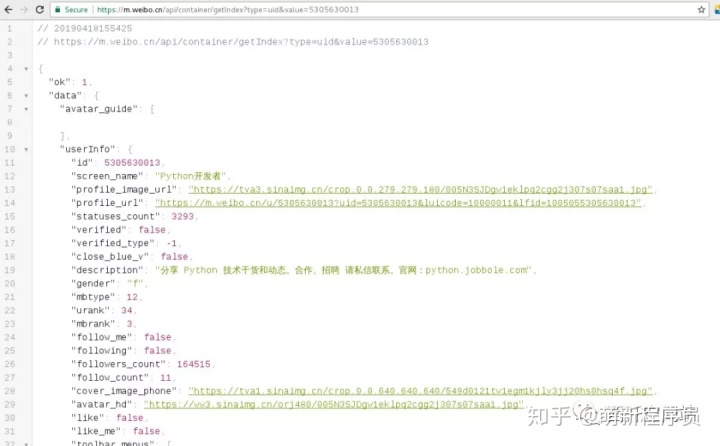
用户数据:
https://m.weibo.cn/api/container/getIndex?type=uid&value=5305630013&containerid=1005055305630013
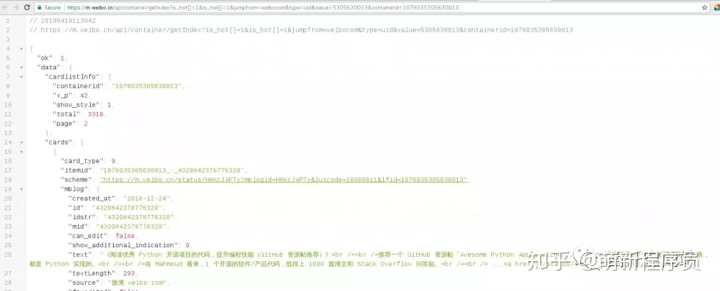
微博内容数据:
https://m.weibo.cn/api/container/getIndex?type=uid&value=5305630013&containerid=1076035305630013
参数value的值,我们通过采集多个情况进行分析得出,提门是用户的id号;
参数containerid的值,我们通过采集多个情况进行分析得出,它们获取用户内容的containerid为100505+oid,获取微博内容的containerid为107603+oid。
2.2.3 API返回的JSON数据分析
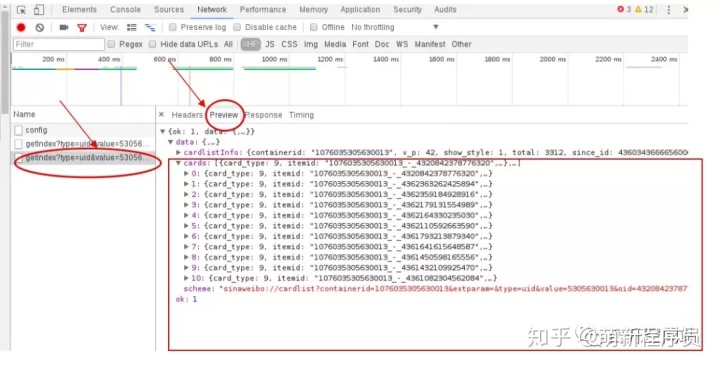
我们在右边选择Preview预览一下json,点击cards中任选一个card,其中的mblog标签下就有我们要的微博内容数据。我们继续观察发现这个json中只有10条数据;
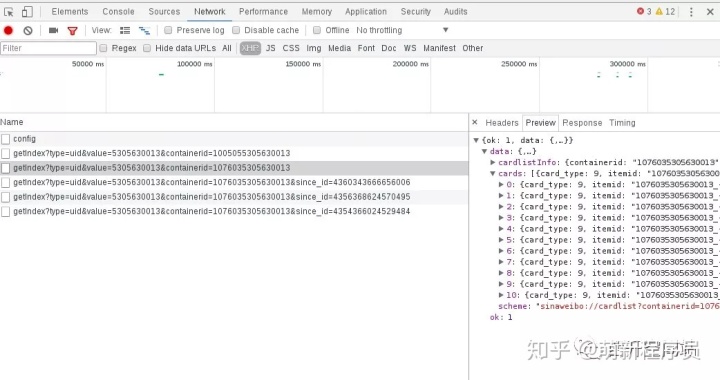
那么我们往下滑动到下一页,继续查看请求的api。我们发现在获取下一页数据时的api加了一个值为2的参数page。继续往下翻页,page变成3、4、5…,由此我们推断这个api获取哪一页的数据由page决定。
2.3 分析返回的json格式的微博内容
通过api我们获取到返回的微博内容数据,我们以其中一个card来分析获取到的数据,微博内容数据在mblog中。
当然可以在Chrome谷歌浏览器中安装一个json-viewer插件, 友好的显示json数据, 如下图所示:
3 获取微博内容的代码实现
我们分析完接口之后就可以开始编写爬虫代码。
3.1 获取微博用户信息
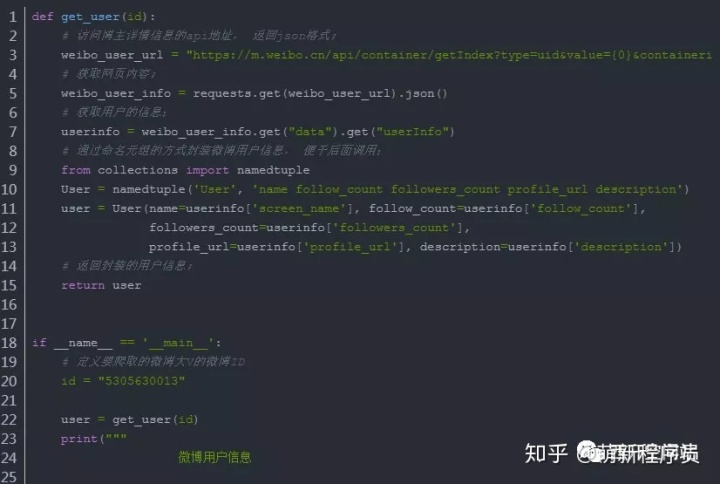

执行效果

3.2 获取微博内容
此处有个问题还没有解决?
Ajax下拉刷新数据, 获取第2页的信息, 默认的网址是通过since_id来处理的, 但是这个参数对应的值没有找到规律;
后来发现, 最早的page参数也可以生效, 因此就先用老方法解决了;
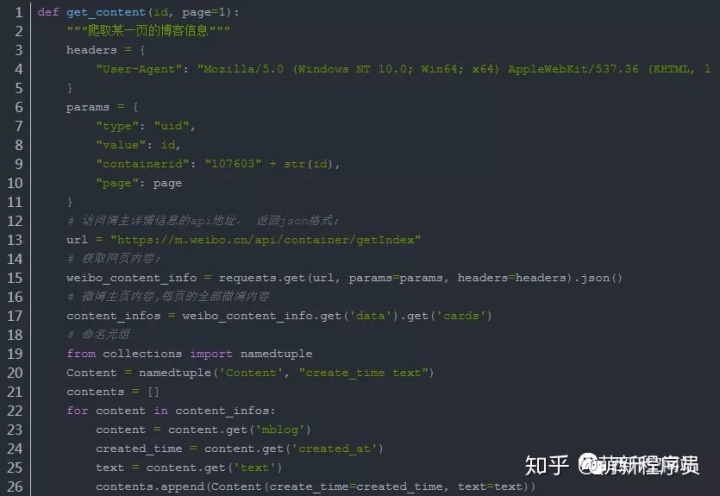
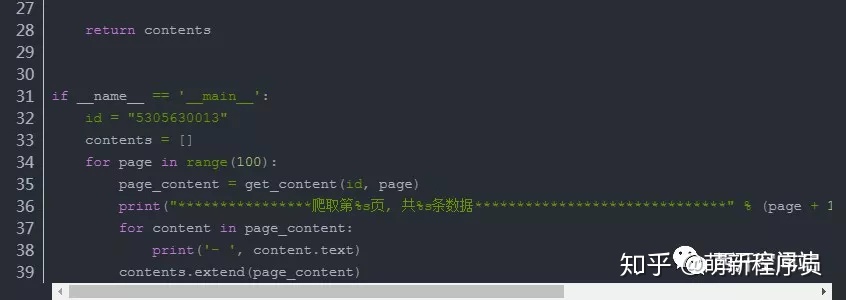
执行效果

◆◆4 代码封装与重构◆◆
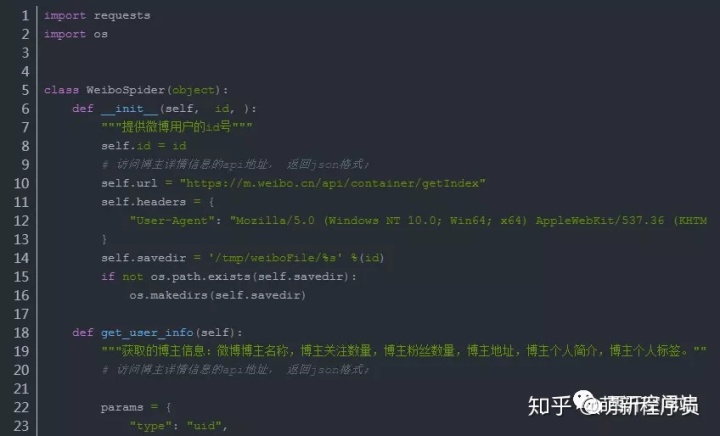
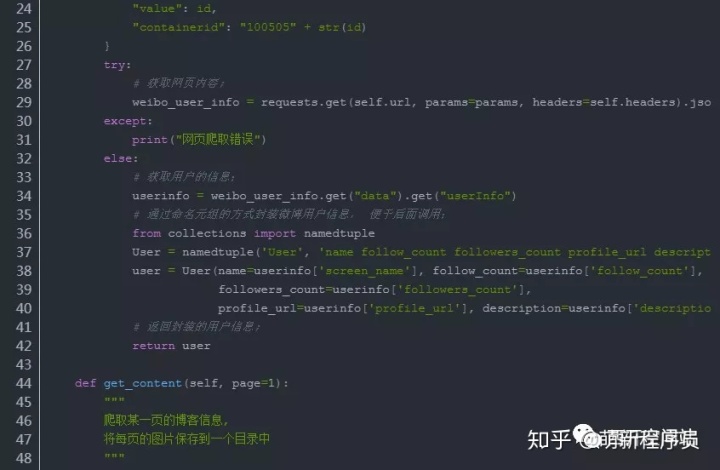
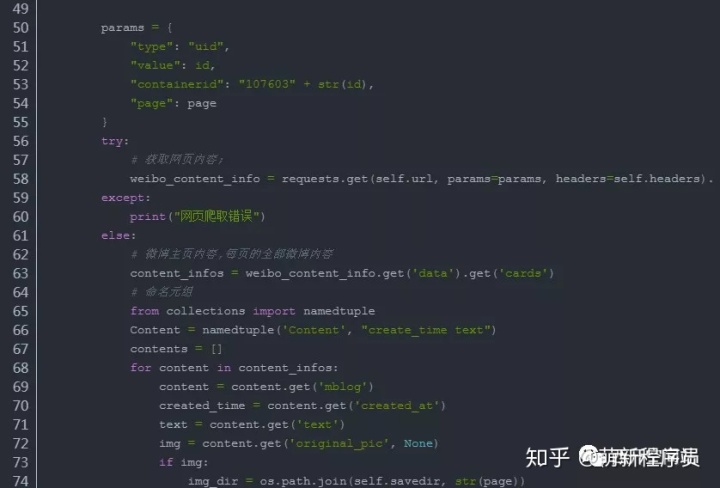
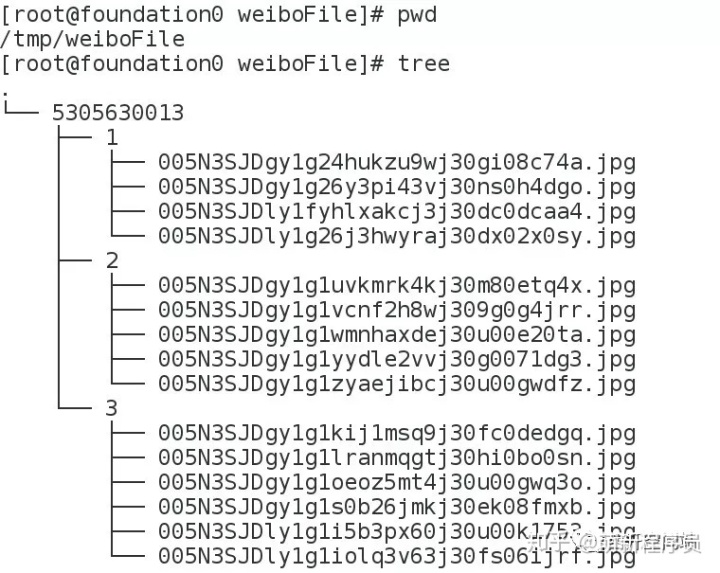
效果展示

拓展
- 这个项目也可以使用urllib模块实现, 只是requests是基于urllib封装的模块, 使用更加友好.当然也可以使用Scrapy爬虫框架.
参考资料:
- 通过获取api爬取新浪微博内容数据实战














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









