






原文:PostgreSQL Replication and Automatic Failover Tutorial[1]
作者:Abbas Butt
翻译整理:alitrack
1.什么是 PostgreSQL 复制?
将数据从一台 PostgreSQL 数据库服务器复制到另一台服务器的过程称为 PostgreSQL 复制。源数据库服务器通常称为主服务器,而接收复制的数据的数据库服务器称为副本服务器。
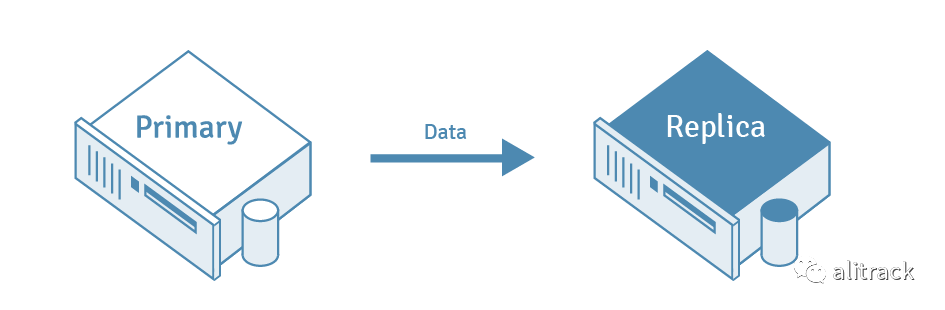
2.什么是 PostgreSQL 中的自动故障转移?
在 PostgreSQL 中设置并配置了物理流复制后,如果数据库的主服务器发生故障,则可以进行故障转移。故障转移是描述恢复过程的术语,在 PostgreSQL 中可能需要一些时间[2],特别是因为 PostgreSQL 本身不提供用于检测服务器故障的内置工具。幸运的是,有可用的工具允许自动故障转移,它可以帮助检测故障并自动切换到备用数据库,从而最大程度地减少数据库停机时间。
EnterpriseDB 的EDB Postgres Failover Manager[3]使您能够自动检测数据库故障,并将最新的备用服务器升级为新的主服务器,从而避免了代价高昂的数据库停机时间。EDB Failover Manager 甚至提供快速,自动的故障检测[4]。
3.高可用性和故障转移复制
高可用性是指已建立的数据库系统,以便在主服务器或主服务器发生故障时备用服务器可以快速接管。为了实现高可用性,数据库系统应满足一些关键要求[5]:数据库系统应具有冗余以防止单点故障,可靠的切换机制以及主动监视功能以检测可能发生的任何故障。设置故障转移复制可通过在主服务器或主服务器出现故障时确保备用服务器可用来提供所需的冗余,以实现高可用性。
4.为什么要使用 PostgreSQL 复制?
数据复制可以有多种用途:
- OLTP 性能
- 容错能力
- 数据迁移
- 并行测试系统
OLTP性能:从联机事务处理(OLTP)系统中消除报告查询负载可以改善报告查询时间和事务处理性能。
容错能力:如果主数据库服务器发生故障,则副本服务器可以接管,因为它已经包含了主服务器的数据。在此配置中,副本服务器也称为备用服务器。此配置还可以用于主服务器的定期维护。
数据迁移:升级数据库服务器硬件,或为另一个客户部署相同的系统。
并行测试系统:将应用程序从一个 DBMS 移植到另一个 DBMS 时,必须比较新旧系统在相同数据上的结果,以确保新系统能够按预期工作。
EnterpriseDB 的EDB Postgres Replication Server[6]使管理 Postgres 复制变得容易,并提供了复制提供的所有好处。
5. PostgreSQL 数据库复制的模型是什么(单主机和多主机)?
- 单原版复制(SMR)
- 多主复制(MMR)
在单主复制(SMR)中,将对指定的主数据库服务器中表行的更改复制到一个或多个副本服务器。副本数据库中的复制表不允许接受任何更改(主服务器除外)。但是,即使这样做,更改也不会被复制回主服务器。
在多主复制(MMR)中,对多个指定主数据库中表行的更改将复制到每个其他主数据库中的对应表中。在该模型中,通常采用冲突解决方案来避免诸如重复主键之类的问题。
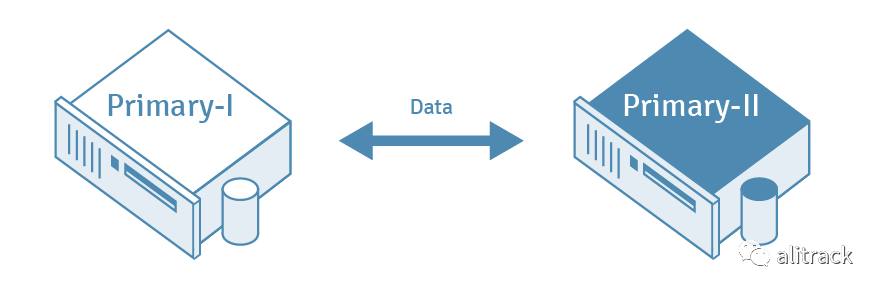
多主复制(MMR)增加了复制的用途:
- 写可用性和可伸缩性。
- 可以使用主数据库的广域网(WAN),该数据库在地理位置上可以接近客户端组,但仍可以保持整个网络的数据一致性。
6. PostgreSQL 复制的类是什么?
- 单向复制
- 双向复制
单主复制也称为单向复制,因为复制数据仅在一个方向上从主复制流向复制。
另一方面,多主复制数据在两个方向上流动,因此被称为双向复制。
7. PostgreSQL 数据库中有哪些复制模式?
- 异步复制模式
- 同步复制模式
在同步模式复制中,仅当这些更改已复制到所有副本时,才声明主数据库上的事务已完成。副本服务器必须始终都是可用的,事务才能在主服务器上完成。

在异步模式下,仅在主服务器上完成更改后,即可声明主服务器上的事务已完成。然后,这些更改将在以后及时复制到副本中。副本服务器可以在一定时间内保持不同步状态,这称为复制滞后。
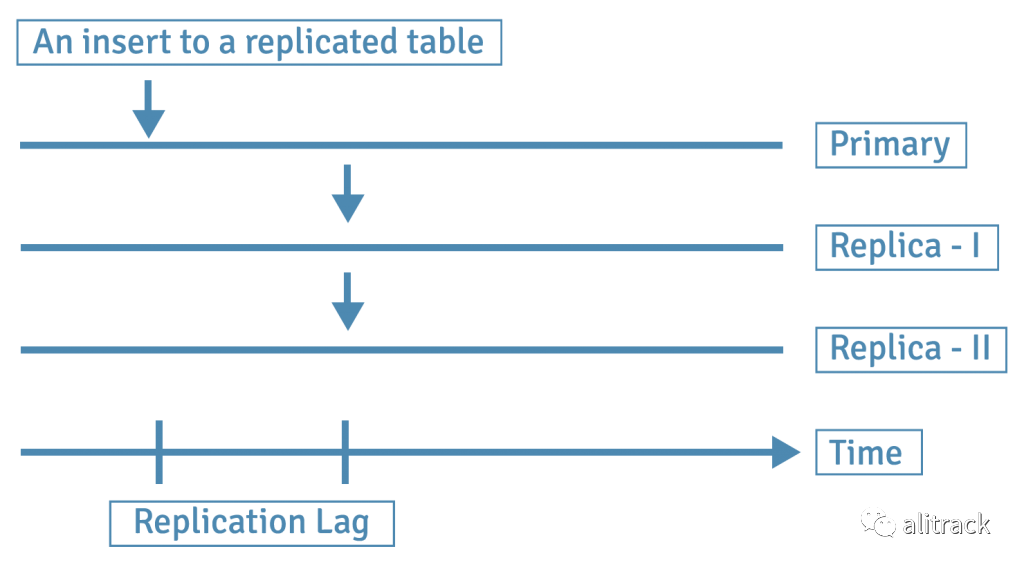
同步和异步模式都有其成本和收益,用户在配置其复制设置[7]时会希望考虑安全性和性能。
8. PostgreSQL 数据库复制的类型是什么?
- PostgreSQL 数据库的物理复制
- PostgreSQL 数据库的逻辑复制
在讨论物理和逻辑复制类型之前,让我们在这里回顾术语物理和逻辑的上下文。
| 逻辑操作 | 物理操作 | |
|---|---|---|
| 1 | 初始化数据库 | 为集群创建基本目录 |
| 2 | 创建数据库 | 在基本目录中创建一个子目录 |
| 3 | 创建表 | 在数据库的子目录中创建一个文件 |
| 4 | 插入 | 更改为此特定表创建的文件,并在当前 WAL 段中写入新的 WAL 记录 |
例如:
ramp=# create table sample_tbl(a int, b varchar(255));
CREATE TABLE
ramp=# SELECT pg_relation_filepath('sample_tbl');
pg_relation_filepath
base/34740/706736
(1 row)
ramp=# SELECT datname, oid FROM pg_database WHERE datname = 'ramp';
datname | oid
ramp | 34740
(1 row)
ramp=# SELECT relname, oid FROM pg_class WHERE relname = 'sample_tbl';
relname | oid
sample_tbl | 706736
(1 row)
物理复制处理文件和目录。它不知道这些文件和目录代表什么。物理复制是在文件系统级别或磁盘级别完成的。
另一方面,逻辑复制处理数据库,表和 DML 操作。因此,在逻辑复制中可能只复制某些表集。逻辑复制在数据库集群级别完成。
9. PostgreSQL 数据库中的预写日志(WAL)简介
9.1 在 PostgreSQL 中什么是预写日志(WAL)?为什么需要?
在 PostgreSQL 中,事务所做的所有更改都首先保存在日志文件中,然后将事务的结果发送到启动客户端。数据文件本身不会在每个事务中更改。这是防止操作系统崩溃,硬件故障或 PostgreSQL 崩溃等情况下数据丢失的标准机制。此机制称为预写日志记录(WAL),而此日志文件称为Write Ahead Log(预写日志)。
事务执行的每个更改(INSERT,UPDATE,DELETE,COMMIT)都作为WAL记录写入日志中。首先将 WAL 记录写入内存中的WAL缓冲区。提交事务后,记录将写入磁盘上的WAL段文件中。
WAL 记录的日志序号(LSN)表示记录保存在日志文件中的位置。LSN 用作 WAL 记录的唯一 ID。从逻辑上讲,事务日志是一个大小为 2^64 字节的文件。因此,LSN 是一个 64 位数字,表示为两个用/分隔的 32 位十六进制数字。例如:
ramp=# select pg_current_wal_lsn();
pg_current_wal_lsn
0/2BDBBD0
(1 row)
如果发生系统崩溃,数据库可以从 WAL 恢复已提交的事务。恢复从最后一个REDO点或检查点开始。一个检查点是在事务日志中的所有数据文件已被更新,以匹配日志中的信息点。将 WAL 记录从日志文件保存到实际数据文件的过程称为检查点。
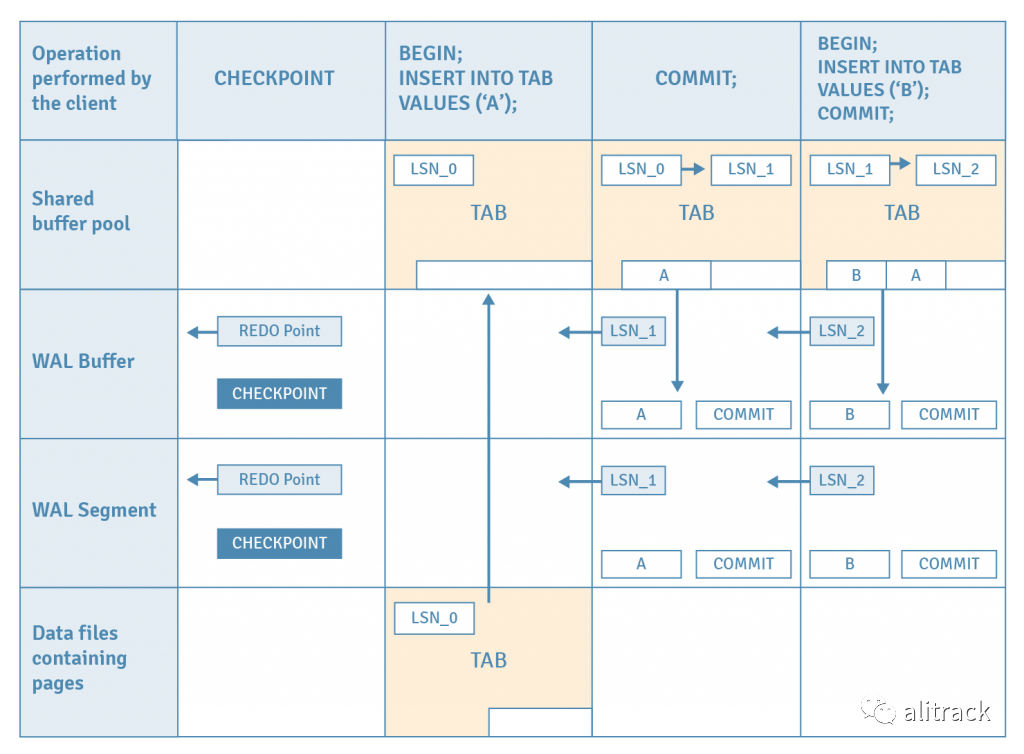
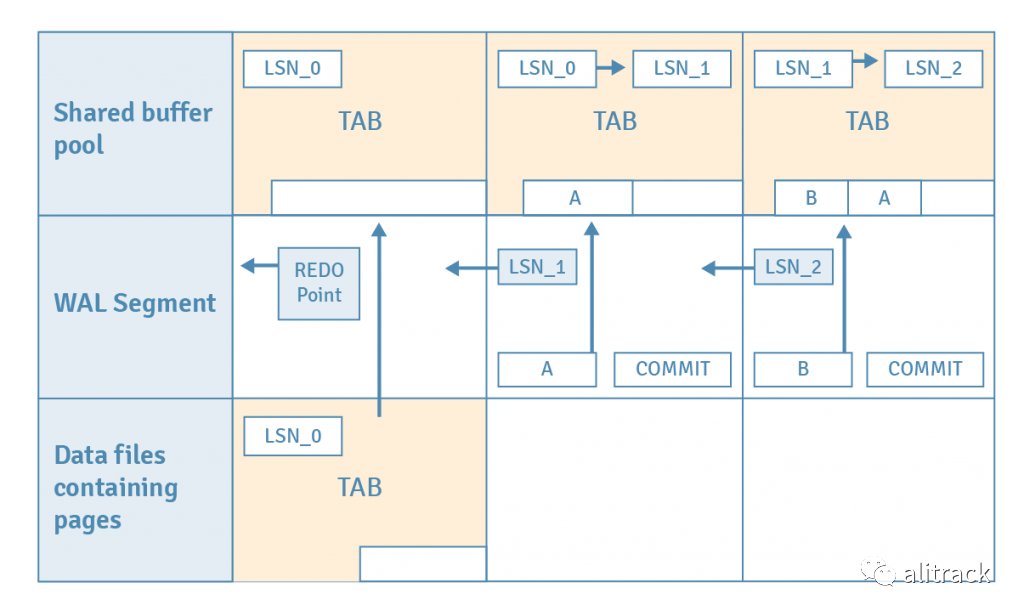
让我们考虑一种情况,在两次执行一次插入的事务后数据库崩溃,并且使用 WAL 进行恢复。
- 假设已发出检查点,该检查点存储了当前 WAL 段中最新 REDO 点的位置。这还将刷新共享缓冲池中的所有脏页到磁盘。此操作保证了 REDO 点之前的 WAL 记录不再需要恢复,因为所有数据均已刷新到磁盘页面。
- 发出第一个 INSERT 语句。该表的页面从磁盘加载到缓冲池。
- 元组被插入到加载的页面中。
- 该插入的 WAL 记录保存在位置 LSN_1 的 WAL 缓冲区中。
- 该页面的 LSN 从 LSN_0 更新为 LSN_1,该 LSN_1 标识了对该页面的最后更改的 WAL 记录。
- 发出第一个 COMMIT 语句。
- 该提交动作的 WAL 记录被写入 WAL 缓冲区,然后 WAL 缓冲区中直到该页面的 LSN 的所有 WAL 记录都被刷新到 WAL 段文件中。
- 对于第二次 INSERT 和 commit,重复步骤 2 至 7。
如果操作系统崩溃,则共享缓冲池上的所有数据都将丢失。但是,对页面的所有修改都已作为历史数据写入 WAL 段文件中。以下步骤显示了如何使用 WAL 记录将数据库集群恢复到崩溃前的状态。无需执行任何特殊操作-重启后 PostgreSQL 将自动进入恢复模式。
- PostgreSQL 从适当的 WAL 段文件中读取第一个 INSERT 语句的 WAL 记录。
- PostgreSQL 将表的页面从数据库集群加载到共享缓冲池中。
- PostgreSQL 将 WAL 记录的 LSN(LSN_1)与页面 LSN(LSN_0)进行比较。由于 LSN_1 大于 LSN_0,因此 WAL 记录中的元组将插入到页面中,并且页面的 LSN 被更新为 LSN_1。
其余的 WAL 记录以类似的方式重放。
10. PostgreSQL 中的事务日志和 WAL 段文件是什么?
PostgreSQL 事务日志是一个虚拟文件,容量为 8 个字节。从物理上讲,该日志分为 16MB 的文件,每个文件称为 WAL 段。
WAL 段文件名是一个 24 位数字,其命名规则如下:

假设当前时间线 ID 为 0x00000001,则第一个 WAL 段文件名将为:
00000001 00000000 0000000
00000001 00000000 0000001
00000001 00000000 0000002
……….
00000001 00000001 0000000
00000001 00000001 0000001
00000001 00000001 0000002
…………
00000001 FFFFFFFF FFFFFFFD
00000001 FFFFFFFF FFFFFFFE
00000001 FFFFFFFF FFFFFFFF
例如:
ramp=# select pg_walfile_name('0/2BDBBD0');
pg_walfile_name
000000010000000000000002
11. PostgreSQL 中的 WAL Writer 是什么?
WAL 编写器是一个后台进程,它定期检查 WAL 缓冲区并将所有未写的 WAL 记录写入 WAL 段。WAL 编写器避免了 IO 活动的爆发,而是随着时间的推移几乎没有 IO 活动地扩展了其过程。配置参数 wal_writer_delay 控制 WAL 编写器刷新 WAL 的频率,默认值为 200 毫秒。
12. WAL 段文件管理
12.1 WAL 段文件存储在哪里?
WAL 段文件存储在 pg_wal 子目录中。
12.2 PostgreSQL 切换到新的 WAL 段文件时的条件是什么?
PostgreSQL 在以下情况下切换到新的 WAL 段文件:
- WAL 段已被填满。
- 已发出函数 pg_switch_wal。
- 启用了 archive_mode,并且超过了设置为 archive_timeout 的时间。
将它们关掉后,可以删除或回收 WAL 文件,即为将来重命名和重用。服务器在任何时间点将保留的 WAL 文件的数量取决于服务器配置和服务器活动。
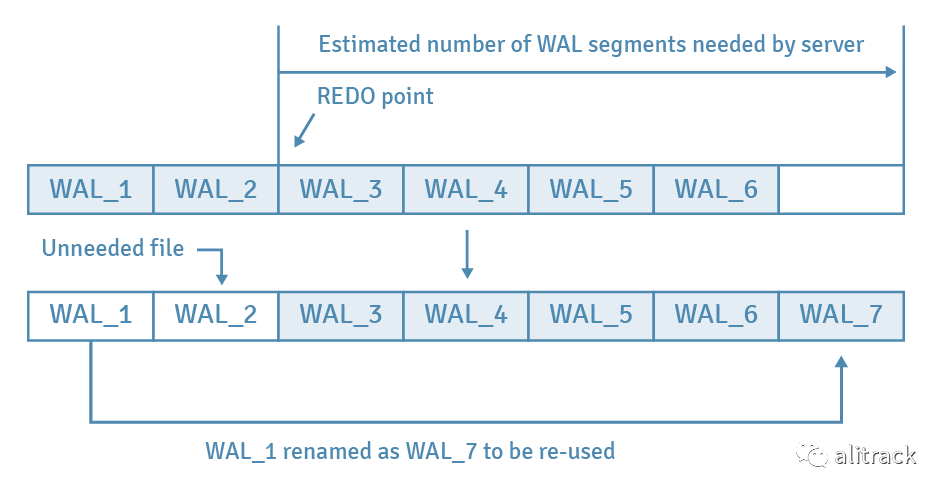
每当检查点启动时,PostgreSQL 都会估算并准备该检查点周期所需的 WAL 段文件的数量。基于先前检查点周期中消耗的文件数进行估算。它们是从包含先前 REDO 点的段开始计算的,其值应介于 min_wal_size(默认为 80MB 或 5 个文件)和 max_wal_size(1GB 或 64 个文件)之间。如果启动检查点,则将保留并回收必要的文件,同时将删除不必要的文件。
下图提供了一个示例。假设在检查点开始之前有六个文件,先前的 REDO 点包含在文件 WAL_3 中,并且 PostgreSQL 估计将保留五个文件。在这种情况下,WAL_1 将重命名为 WAL_7 以进行回收,而 WAL_2 将被删除。
13. PostgreSQL 的预写日志记录(WAL)示例
步骤 1:
ramp=# SELECT datname, oid FROM pg_database WHERE datname = 'postgres';
datname | oid
postgres | 15709
Note the database OID, i.e. 15709
步骤 2:
ramp=# SELECT oid,* from pg_tablespace;
oid | spcname | spcowner | spcacl | spcoptions
1663 | pg_default | 10 | |
1664 | pg_global | 10 | |
Note the table space OID, i.e. 1663
步骤 3:
ramp=# SELECT pg_current_wal_lsn();
pg_current_wal_lsn
0/1C420B8
Note the LSN, i.e. 0/1C420B8
步骤 4:
ramp=# CREATE TABLE abc(a VARCHAR(10));
步骤 5:
ramp=# SELECT pg_relation_filepath('abc');
pg_relation_filepath
base/15709/16384
Note the relation filename, base/15709/16384
步骤 6:
在./pg_waldump --path=/tmp/sd/pg_wal –start=0/1C420B8处查看文件的内容
使用步骤 3 中所述的起始 LSN。
注意,WAL 包含创建物理文件的指令
15709→ 数据库 postgres→ 在步骤 1 中记录
16384→ 表 abc→ 步骤 5 中已记录
| rmgr | Len(rec/tot) | tx | lsn | prev | desc |
|---|---|---|---|---|---|
| XLOG | 30/ 30 | 0 | 0/01C420B8 | 0/01C42080 | NEXTOID 24576 |
| Storage | 42/ 42 | 0 | 0/01C420D8 | 0/01C420B8 | CREATE base/15709/16384 |
| Heap | 203/203 | 1216 | 0/01C42108 | 0/01C420D8 | INSERT off 2, blkref #0: rel 1663/15709/1247 blk 0 |
| Btree | 64/ 64 | 1216 | 0/01C421D8 | 0/01C42108 | INSERT_LEAF off 298, blkref #0: rel 1663/15709/2703 blk 2 |
| Btree | 64/ 64 | 1216 | 0/01C42218 | 0/01C421D8 | INSERT_LEAF off 7, blkref #0: rel 1663/15709/2704 blk 5 |
| Heap | 80/ 80 | 1216 | 0/01C42258 | 0/01C42218 | INSERT off 30, blkref #0: rel 1663/15709/2608 blk 9 |
| Btree | 72/ 72 | 1216 | 0/01C422A8 | 0/01C42258 | INSERT_LEAF off 243, blkref #0: rel 1663/15709/2673 blk 51 |
| Btree | 72/ 72 | 1216 | 0/01C422F0 | 0/01C422A8 | INSERT_LEAF off 170, blkref #0: rel 1663/15709/2674 blk 61 |
| Heap | 203/203 | 1216 | 0/01C42338 | 0/01C422F0 | INSERT off 6, blkref #0: rel 1663/15709/1247 blk 1 |
| Btree | 64/64 | 1216 | 0/01C42408 | 0/01C42338 | INSERT_LEAF off 298, blkref #0: rel 1663/15709/2703 blk 2 |
| Btree | 72/ 72 | 1216 | 0/01C42448 | 0/01C42408 | INSERT_LEAF off 3, blkref #0: rel 1663/15709/2704 blk 1 |
| Heap | 80/ 80 | 1216 | 0/01C42490 | 0/01C42448 | INSERT off 36, blkref #0: rel 1663/15709/2608 blk 9 |
| Btree | 72/ 72 | 1216 | 0/01C424E0 | 0/01C42490 | INSERT_LEAF off 243, blkref #0: rel 1663/15709/2673 blk 51 |
| Btree | 72/ 72 | 1216 | 0/01C42528 | 0/01C424E0 | INSERT_LEAF off 97, blkref #0: rel 1663/15709/2674 blk 57 |
| Heap | 199/199 | 1216 | 0/01C42570 | 0/01C42528 | INSERT off 2, blkref #0: rel 1663/15709/1259 blk 0 |
| Btree | 64/ 64 | 1216 | 0/01C42638 | 0/01C42570 | INSERT_LEAF off 257, blkref #0: rel 1663/15709/2662 blk 2 |
| Btree | 64/ 64 | 1216 | 0/01C42678 | 0/01C42638 | INSERT_LEAF off 8, blkref #0: rel 1663/15709/2663 blk 1 |
| Btree | 64/ 64 | 1216 | 0/01C426B8 | 0/01C42678 | INSERT_LEAF off 217, blkref #0: rel 1663/15709/3455 blk 5 |
| Heap | 171/171 | 1216 | 0/01C426F8 | 0/01C426B8 | INSERT off 53, blkref #0: rel 1663/15709/1249 blk 16 |
| Btree | 64/ 64 | 1216 | 0/01C427A8 | 0/01C426F8 | INSERT_LEAF off 185, blkref #0: rel 1663/15709/2658 blk 25 |
| Btree | 64/ 64 | 1216 | 0/01C427E8 | 0/01C427A8 | INSERT_LEAF off 194, blkref #0: rel 1663/15709/2659 blk 16 |
| Heap | 171/171 | 1216 | 0/01C42828 | 0/01C427E8 | INSERT off 54, blkref #0: rel 1663/15709/1249 blk 16 |
| Btree | 72/ 72 | 1216 | 0/01C428D8 | 0/01C42828 | INSERT_LEAF off 186, blkref #0: rel 1663/15709/2658 blk 25 |
| Btree | 64/ 64 | 1216 | 0/01C42920 | 0/01C428D8 | INSERT_LEAF off 194, blkref #0: rel 1663/15709/2659 blk 16 |
| Heap | 171/171 | 1216 | 0/01C42960 | 0/01C42920 | INSERT off 55, blkref #0: rel 1663/15709/1249 blk 16 |
| Btree | 72/ 72 | 1216 | 0/01C42A10 | 0/01C42960 | INSERT_LEAF off 187, blkref #0: rel 1663/15709/2658 blk 25 |
| Btree | 64/ 64 | 1216 | 0/01C42A58 | 0/01C42A10 | INSERT_LEAF off 194, blkref #0: rel 1663/15709/2659 blk 16 |
| Heap | 171/171 | 1216 | 0/01C42A98 | 0/01C42A58 | INSERT off 1, blkref #0: rel 1663/15709/1249 blk 17 |
| Btree | 72/ 72 | 1216 | 0/01C42B48 | 0/01C42A98 | INSERT_LEAF off 186, blkref #0: rel 1663/15709/2658 blk 25 |
| Btree | 64/ 64 | 1216 | 0/01C42B90 | 0/01C42B48 | INSERT_LEAF off 194, blkref #0: rel 1663/15709/2659 blk 16 |
| Heap | 171/171 | 1216 | 0/01C42BD0 | 0/01C42B90 | INSERT off 3, blkref #0: rel 1663/15709/1249 blk 17 |
| Btree | 72/ 72 | 1216 | 0/01C42C80 | 0/01C42BD0 | INSERT_LEAF off 188, blkref #0: rel 1663/15709/2658 blk 25 |
| Btree | 64/ 64 | 1216 | 0/01C42CC8 | 0/01C42C80 | INSERT_LEAF off 194, blkref #0: rel 1663/15709/2659 blk 16 |
| Heap | 171/171 | 1216 | 0/01C42D08 | 0/01C42CC8 | INSERT off 5, blkref #0: rel 1663/15709/1249 blk 17 |
| Btree | 72/ 72 | 1216 | 0/01C42DB8 | 0/01C42D08 | INSERT_LEAF off 186, blkref #0: rel 1663/15709/2658 blk 25 |
| Btree | 64/ 64 | 1216 | 0/01C42E00 | 0/01C42DB8 | INSERT_LEAF off 194, blkref #0: rel 1663/15709/2659 blk 16 |
| Heap | 171/171 | 1216 | 0/01C42E40 | 0/01C42E00 | INSERT off 30, blkref #0: rel 1663/15709/1249 blk 32 |
| Btree | 72/ 72 | 1216 | 0/01C42EF0 | 0/01C42E40 | INSERT_LEAF off 189, blkref #0: rel 1663/15709/2658 blk 25 |
| Btree | 64/ 64 | 1216 | 0/01C42F38 | 0/01C42EF0 | INSERT_LEAF off 194, blkref #0: rel 1663/15709/2659 blk 16 |
| Heap | 80/ 80 | 1216 | 0/01C42F78 | 0/01C42F38 | INSERT off 25, blkref #0: rel 1663/15709/2608 blk 11 |
| Btree | 72/ 72 | 1216 | 0/01C42FC8 | 0/01C42F78 | INSERT_LEAF off 131, blkref #0: rel 1663/15709/2673 blk 44 |
| Btree | 72/ 72 | 1216 | 0/01C43010 | 0/01C42FC8 | INSERT_LEAF off 66, blkref #0: rel 1663/15709/2674 blk 46 |
| Standby | 42/ 42 | 1216 | 0/01C43058 | 0/01C43010 | LOCK xid 1216 db 15709 rel 16384 |
| Txn | 405/405 | 1216 | 0/01C43088 | 0/01C43058 | COMMIT 2019-03-04 07:42:23.165514 EST;... snapshot 2608 relcache 16384 |
| Standby | 50/ 50 | 0 | 0/01C43220 | 0/01C43088 | RUNNING_XACTS nextXid 1217 latestCompletedXid 1216 oldestRunningXid 1217 |
步骤 7:
ramp=# SELECT pg_current_wal_lsn();
pg_current_wal_lsn
0/1C43258
(1 row)
步骤 8:
ramp=# INSERT INTO abc VALUES('pkn');
步骤 9:
./pg_waldump --path=/tmp/sd/pg_wal --start=0/1C43258
使用步骤 7 中的起始 LSN。
1663→pg_default 表空间 → 在步骤 2 中记录
15709→ 数据库 postgres→ 在步骤 1 中记录
16384→ 表 abc→ 步骤 5 中已记录
| rmgr | Len (rec/tot) | tx | lsn | prev | desc |
|---|---|---|---|---|---|
| Heap | 59/59 | 1217 | 0/01C43258 | 0/01C43220 | INSERT+INIT off 1, blkref #0: rel 1663/15709/16384 blk 0 |
| Transaction | 34/34 | 1217 | 0/01C43298 | 0/01C43258 | COMMIT 2019-03-04 07:43:45.887511 EST |
| Standby | 54/54 | 0 | 0/01C432C0 | 0/01C43298 | RUNNING_XACTS nextXid 1218 latestCompletedXid 1216 oldestRunningXid 1217; 1 xacts: 1217 |
步骤 10:
ramp=# SELECT pg_current_wal_lsn();
pg_current_wal_lsn
0/1C432F8
(1 row)
步骤 11:
ramp=# INSERT INTO abc VALUES('ujy');
步骤 12:
./pg_waldump --path=/tmp/sd/pg_wal –start=0/1C432F8
使用从步骤 10 开始的 LSN。
| rmgr | Len (rec/tot) | tx | lsn | prev | desc |
|---|---|---|---|---|---|
| Heap | 59/59 | 1218 | 0/01C432F8 | 0/01C432C0 | INSERT off 2, blkref #0: rel 1663/15709/16384 blk 0 |
| Transaction | 34/34 | 1218 | 0/01C43338 | 0/01C432F8 | COMMIT 2019-03-04 07:44:25.449151 EST |
| Standby | 50/50 | 0 | 0/01C43360 | 0/01C43338 | RUNNING_XACTS nextXid 1219 latestCompletedXid 1218 oldestRunningXid 1219 |
步骤 13:检查 WAL 段文件中的实际元组。
Offset | Hex Bytes| ASCII chars |
00000060 | 3b 00 00 00 c3 04 00 00 28 00 40 02 00 00 00 00 |;.......(.@.....|
00000070 | 00 0a 00 00 ec 28 75 6e 00 20 0a 00 7f 06 00 00 |.....(un. ......|
00000080 | 5d 3d 00 00 00 40 00 00 00 00 00 00 ff 03 01 00 |]=...@..........|
00000090 | 02 08 18 00 09 70 6b 6e 03 00 00 00 00 00 00 00 |.....pkn........|
000000a0 | 22 00 00 00 c3 04 00 00 60 00 40 02 00 00 00 00 |".......`.@.....|
000000b0 | 00 01 00 00 dd 4c 87 04 ff 08 e4 73 44 e7 41 26 |.....L.....sD.A&|
000000c0 | 02 00 00 00 00 00 00 00 32 00 00 00 00 00 00 00 |........2.......|
000000d0 | a0 00 40 02 00 00 00 00 10 08 00 00 9e 01 36 88 |..@...........6.|
000000e0 | ff 18 00 00 00 00 00 00 00 00 00 03 00 00 c4 04 |................|
000000f0 | 00 00 c4 04 00 00 c3 04 00 00 00 00 00 00 00 00 |................|
00000100 | 3b 00 00 00 c4 04 00 00 c8 00 40 02 00 00 00 00 |;.........@.....|
00000110 | 00 0a 00 00 33 df b4 71 00 20 0a 00 7f 06 00 00 |....3..q. ......|
00000120 | 5d 3d 00 00 00 40 00 00 00 00 00 00 ff 03 01 00 |]=...@..........|
00000130 | 02 08 18 00 09 75 6a 79 04 00 00 00 00 00 00 00 |.....ujy........|
00000140 | 22 00 00 00 c4 04 00 00 00 01 40 02 00 00 00 00 |".........@.....|
00000150 | 00 01 00 00 96 2e 96 a6 ff 08 d8 f3 79 ed 41 26 |............y.A&|
00000160 | 02 00 00 00 00 00 00 00 32 00 00 00 00 00 00 00 |........2.......|
00000170 | 40 01 40 02 00 00 00 00 10 08 00 00 eb 6b 95 36 |@.@..........k.6|
00000180 | ff 18 00 00 00 00 00 00 00 00 00 03 00 00 c5 04 |................|
00000190 | 00 00 c5 04 00 00 c4 04 00 00 00 00 00 00 00 00 |................|
000001a0 | 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
14. PostgreSQL 中基于 WAL 的复制选项是什么?
- 连续的 WAL 归档
- 基于日志传送的复制-文件级别
- 基于日志传送的复制-块级别
14.1 连续 WAL 归档
将生成的 WAL 文件复制到 pg_wal 子目录以外的任何位置以进行存档的过程称为 WAL 归档。每次生成 WAL 文件时,PostgreSQL 都会调用用户提供的脚本进行归档。该脚本可以使用 scp 命令将文件复制到一个或多个位置。该位置可以是 NFS 挂载。存档后,WAL 段文件可用于在任何指定的时间点恢复数据库。
14.2 基于日志传送的复制-文件级别
为了通过重放 WAL 文件来创建另一个备用服务器,将日志文件复制到另一个 PostgreSQL 服务器称为日志传送。该备用服务器配置为处于恢复模式,其唯一目的是在任何新的 WAL 文件到达时应用它们。然后,第二台服务器(也称为备用服务器)成为主 PostgreSQL 服务器的热备份。备用数据库还可以配置为只读副本,在该副本数据库中还可以提供只读查询。这称为热备用。
14.3 基于日志传送的复制-块级别
流复制改善了日志传送过程。无需等待 WAL 切换,而是在记录生成时发送记录,从而减少了复制延迟。另一个改进是备用服务器将使用复制协议通过网络连接到主服务器。然后,主服务器可以直接通过此连接发送 WAL 记录,而不必依赖最终用户提供的脚本。
14.4 主服务器应保留 WAL 段文件多长时间?
如果没有任何流复制客户端,则在存档脚本报告成功后,如果崩溃恢复不需要它们,则服务器可以丢弃(回收)WAL 段文件。
但是,备用客户端的存在会带来一个问题:只要最慢的备用客户端需要 WAL 文件,服务器就需要保留它们。例如,如果备用数据库被关闭了一会儿,然后又恢复在线状态并向主要数据库请求主要数据库不再具有的 WAL 文件,则复制将失败,并显示类似以下错误:
ERROR: requested WAL segment 00000001000000010000002D has already been removed
错误:请求的 WAL 段 00000001000000010000002D 已被删除
因此,主服务器应跟踪备用数据库的距离,而不是删除(回收)任何备用数据库仍需要的 WAL 文件。此功能是通过复制插槽提供的。
每个复制插槽都有一个名称,用于标识该插槽。每个插槽都与:
- 插槽的使用者需要的最旧的 WAL 段文件。在检查点期间,不会删除(回收)比此更新的 WAL 段文件。
- 插槽的使用者需要保留的最早的交易 ID。真空不会删除任何比此最近的事务所需的行。
15.基于日志传送的复制
15.1 物理流复制
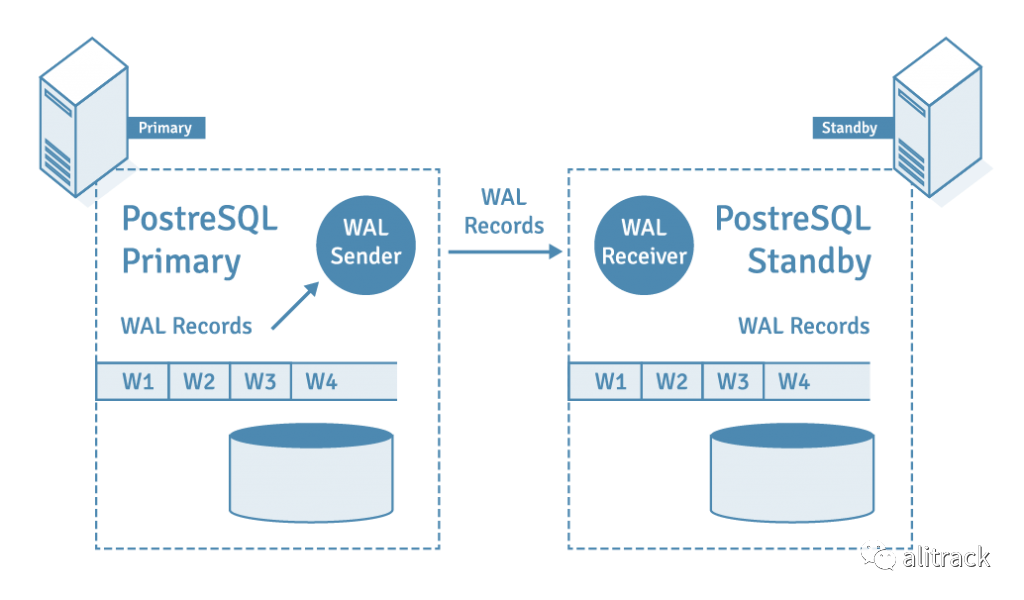
PostgreSQL 数据库中的物理流复制是基于 WAL 的数据复制。在流复制中,备用服务器连接到主服务器,并使用复制协议接收 WAL 记录。
物理流复制的优点是什么?
- 备用服务器无需等待 WAL 文件填满,从而改善了复制滞后。
- 删除了对用户提供的脚本和服务器之间的中间共享存储的依赖。
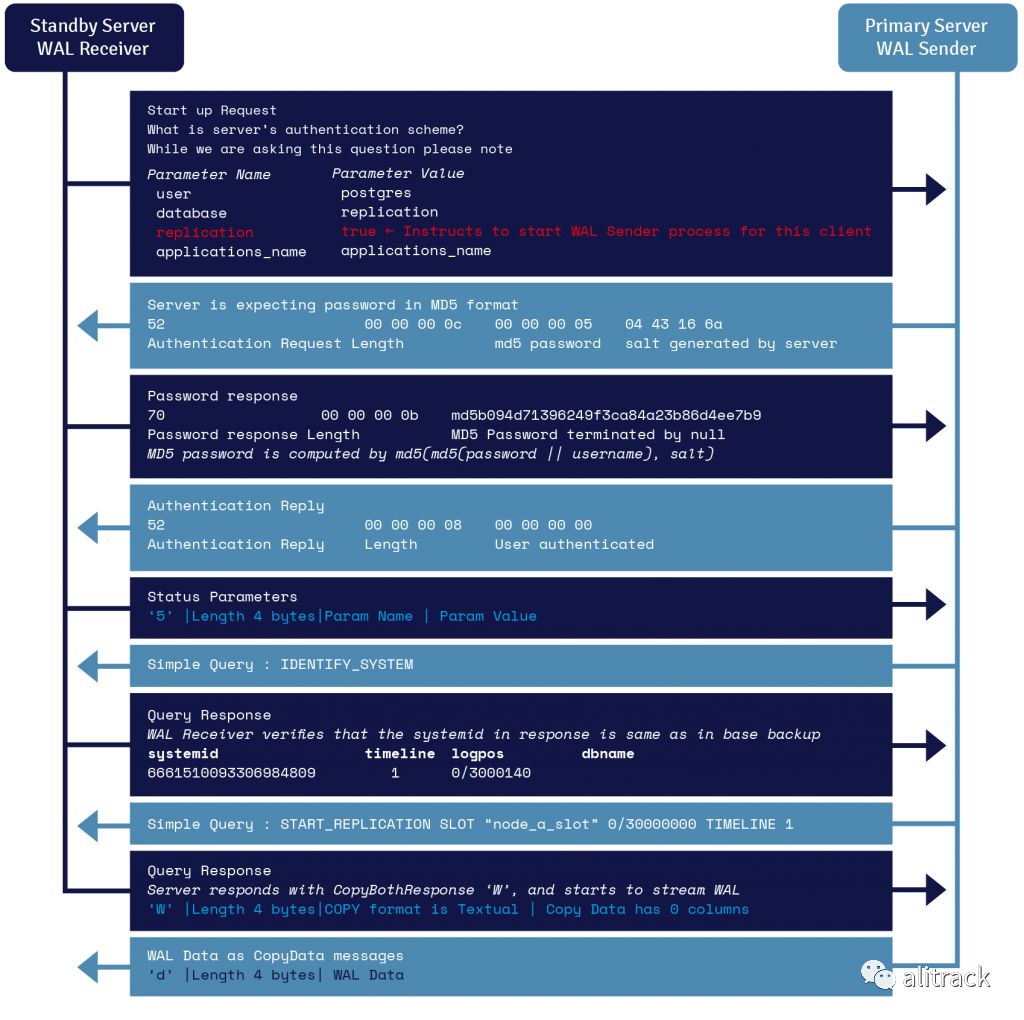
16. PostgreSQL 中的 WAL 发送者和 WAL 接收者是什么?
在备用服务器上运行的名为WAL Receiver的进程使用 recovery.conf 的primary_conninfo参数中提供的连接详细信息,并使用 TCP/IP 连接连接到主服务器。
WAL Sender是在主服务器上运行的另一个进程,负责将 WAL 记录在生成时发送到备用服务器。WAL 接收器将 WAL 记录保存在 WAL 中,就好像它们是由本地连接的客户端的客户端活动生成的一样。一旦 WAL 记录到达 WAL 段文件,备用服务器就会不断重放 WAL,以便备用数据库和主数据库是最新的。
16.1 WAL 流协议详细信息
17. PostgreSQL 复制和故障转移设置
该设置包括两台通过 LAN 连接的 CentOS 7 计算机,在该计算机上安装了 PostgreSQL 版本 10.7。
17.1 使用 WAL 流配置 PostgreSQL 复制
**步骤 1:**在两台计算机上禁用并停止防火墙:
sudo firewall-cmd
sudo systemctl stop firewalld
sudo systemctl disable firewalld
sudo systemctl mask
**步骤 2:**在主服务器上,允许复制连接和来自同一网络的连接。修改 pg_hba.conf:
Local all all md5
host all all 172.16.214.167/24 md5
host all all ::1/128 md5
local replication all md5
host replication all 172.16.214.167/24 md5
host replication all ::1/128 md5
**步骤 3:**在主服务器上,编辑 postgresql.conf 以修改以下参数:
max_wal_senders = 10
wal_level = replica
max_replication_slots = 10
synchronous_commit = on
synchronous_standby_names = '*'
listen_addresses = '*'
**步骤 4:**启动主服务器:
./postgres -D ../pr_data -p 5432
步骤 5:进行基本备份以引导备用服务器:
./pg_basebackup --pgdata=/tmp/sb_data/ \
--format=p --write-recovery-conf \
--checkpoint=fast --label=mffb \
--progress --verbose \
--host=172.16.214.167 --port=5432 \
--username=postgres
**步骤 6:**检查基本备份标签文件:
START WAL LOCATION: 0/2000028 (file 000000010000000000000002)
CHECKPOINT LOCATION: 0/2000060
BACKUP METHOD: streamed
BACKUP FROM: master
START TIME: 2019-02-24 05:25:30 EST
LABEL: mffb
**步骤 7:**在基本备份中,在 recovery.conf 中添加以下行:
primary_slot_name = 'node_a_slot'
**步骤 8:**检查/tmp/sb_data/recovery.conf 文件
standby_mode = 'on'
primary_conninfo = 'user=enterprisedb
password=abc123
host=172.16.214.167
port=5432
sslmode=prefer
sslcompression=1
krbsrvname=postgres
target_session_attrs=any'
primary_slot_name = 'node_a_slot'
**步骤 9:**连接到主服务器并发出以下命令:
edb=# SELECT * FROM pg_create_physical_replication_slot('node_a_slot');
slot_name | xlog_position
node_a_slot |
(1 row)
edb=# SELECT slot_name, slot_type, active FROM pg_replication_slots;
slot_name | slot_type | active
node_a_slot | physical | f
(1 row)
**步骤 10:**将基本备份转移到备用服务器:
scp /tmp/sb_data.tar.gz abbas@172.16.214.166:/tmp
sudo mv /tmp/sb_data /opt/PostgreSQL/10/
sudo chown postgres:postgres /opt/PostgreSQL/10/sb_data/
sudo chown -R postgres:postgres /opt/PostgreSQL/10/sb_data/
sudo chmod 700 /opt/PostgreSQL/10/sb_data/
**步骤 11:**启动备用服务器:
./postgres -D ../sb_data/ -p 5432
主服务器将在日志中显示此内容:
LOG: standby "walreceiver" is now a synchronous standby with priority 1
日志:备用“ walreceiver”现在是优先级为 1 的同步备用
待机状态将显示:
LOG: database system was interrupted; last known up at 2018-10-24 15:49:55
LOG: entering standby mode
LOG: redo starts at 0/3000028
LOG: consistent recovery state reached at 0/30000F8
LOG: started streaming WAL from primary at 0/4000000 on timeline 1
LOG:数据库系统被中断;最后知道于2018-10-24 15:49:55
日志:进入待机模式
日志:重做从0/3000028开始
日志:一致的恢复状态达到0 / 30000F8
日志:在时间轴1上从0/4000000开始从主要流式传输WAL
步骤 12:连接到主服务器并发出一些简单命令:
create table abc(a int, b varchar(250));
insert into abc values(1,'One');
insert into abc values(2,'Two');
insert into abc values(3,'Three');
步骤 13:检查副本上的数据:
postgres=# select * from abc;
a | b
1 | One
2 | Two
3 | Three
(3 rows)
18. PostgreSQL 手动故障转移步骤是什么?
步骤 1:使主服务器崩溃。
步骤 2:通过在备用服务器上运行以下命令来升级备用服务器:
$ ./pg_ctl promote -D ../sb_data/
server promoting
步骤 3:连接到升级后的备用服务器并插入一行:
edb=# insert into abc values(4,'Four');
该插入工作良好的事实意味着备用服务器(否则是只读服务器)已被提升为新的主服务器。
19.如何在 PostgreSQL 中自动执行故障转移和复制
使用 EDB Postgres 故障转移管理器(EFM)可以轻松设置自动故障转移。在每个主节点和备用节点上下载并安装 EFM[8]之后,您可以创建一个EFM 群集[9],该群集[10]由一个主节点,一个或多个备用节点以及一个可选的 Witness 节点组成,该节点在发生故障时确认断言。
EFM 持续监视系统运行状况,并根据系统事件发送电子邮件警报。发生故障时,它将自动切换到最新的备用服务器,并重新配置所有其他备用服务器以识别新的主服务器。它还重新配置负载均衡器(例如 pgPool),并防止“分裂大脑”(当两个节点各自认为它们是主要节点时)发生。
20. PostgreSQL 的 repmgr
另一个开源工具是 repmgr(复制管理器),它也管理 PostgreSQL 集群的复制和故障转移。EDB 提供了有关安装和运行 PostgreSQL repmgr的深入教程[11]。如果配置正确,则 repmgr 可以检测主服务器何时发生故障并执行自动故障转移。
参考资料
[1]PostgreSQL Replication and Automatic Failover Tutorial: https://www.enterprisedb.com/postgres-tutorials/postgresql-replication-and-automatic-failover-tutorial
[2]可能需要一些时间: http://www.postgres.cn/docs/12/warm-standby-failover.html
[3]EDB Postgres Failover Manager: https://www.enterprisedb.com/products/postgresql-automatic-failover-manager-cluster-high-availability
[4]快速,自动的故障检测: https://www.enterprisedb.com/blog/edb-postgres-automatic-failover-detection-high-availabile-clusters
[5]关键要求: https://www.enterprisedb.com/blog/what-does-database-high-availability-really-mean
[6]EDB Postgres Replication Server: https://www.enterprisedb.com/products/postgresql-replication-server-single-or-multi-master-mode
[7]配置其复制设置: https://www.enterprisedb.com/blog/why-use-synchronous-replication-in-postgresql-configure-streaming-replication-wal
[8]下载并安装 EFM: https://www.enterprisedb.com/edb-docs/p/edb-postgres-failover-manager
[9]EFM 群集: https://www.enterprisedb.com/edb-docs/d/edb-postgres-failover-manager/installation-getting-started/quick-start/3.10/index.html
[10]群集: https://www.enterprisedb.com/edb-docs/d/edb-postgres-failover-manager/installation-getting-started/quick-start/3.10/index.html
[11]的深入教程: https://www.enterprisedb.com/postgres-tutorials/how-implement-repmgr-postgresql-automatic-failover















 3113
3113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









