






 本文介绍了贝叶斯神经网络(BNN),探讨了普通全连接神经网络的过度拟合问题,并阐述了BNN如何通过引入参数分布避免这个问题。BNN利用变分推断或马尔可夫链蒙特卡罗方法进行贝叶斯推断,通过最大化证据下界(ELBO)来优化网络。
本文介绍了贝叶斯神经网络(BNN),探讨了普通全连接神经网络的过度拟合问题,并阐述了BNN如何通过引入参数分布避免这个问题。BNN利用变分推断或马尔可夫链蒙特卡罗方法进行贝叶斯推断,通过最大化证据下界(ELBO)来优化网络。
Probabilistic in Robotics Ⅳ: Bayesian Neural Network
贝叶斯方法后来也搭上了Deep learning的顺风车,摇身一变成了Bayesian Neural Network(BNN)。
注意:这叫做贝叶斯神经网络,不是贝叶斯图网络
之前一直在介绍贝叶斯方法的思想,但是没有介绍怎么求解。在第二章Bayesian Inference已经写过主要的求解方式有两种:
- 基于采样的马尔可夫链蒙特卡罗(Markov Chain Monte Carlo,简称MCMC)方法
- 基于近似的变分推断(Variational Inference,简称VI)方法
这两个还是放在后面,链接之后会放出。先介绍变分推断的特例,贝叶斯神经网络。
结构
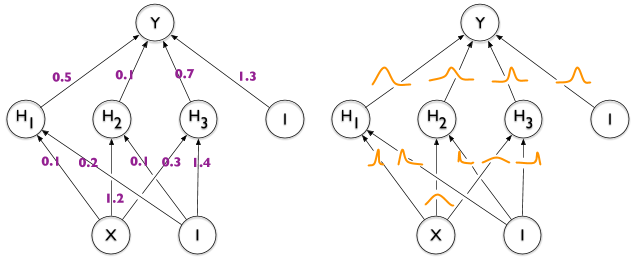
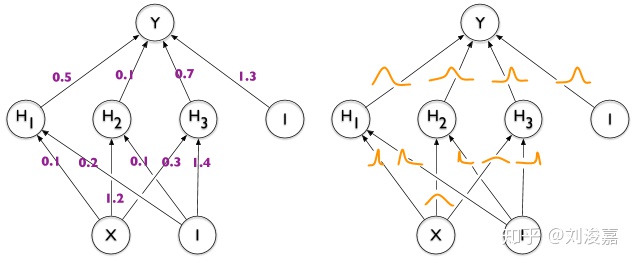
左图是普通的全连接(deterministic)神经网络,右图是贝叶斯(probabilistic)神经网络。
普通的全连接神经网络有什么缺点?
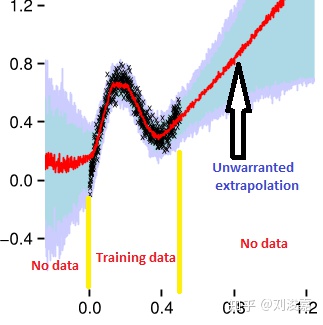
NN倾向于过度拟合它所看到的数据,但在训练集范围外的部分,就无能为力了。这个时候如果能对NN的预测有一个置信度的评价会很有帮助。
BNN怎么做?
贝叶斯推断和MAP的不同在于,贝叶斯推断求出参数
所以,直接把NN的网络权重改成分布
由于我们求得的是分布,基于
本来后验分布
这里使用信息论中的KL散度来度量目标分布和预测分布之间的差异。
将式中的真实后验概率根据贝叶斯公式展开:
得到两个结论:
- 由于
,因此
。前面是数据的似然,被称为Evidence. 因此后面的项被称为 Evidence lower bound (ELBO)。
- 设 Evidence 不变,最小化KL等价于最大化 ELBO:
其中:
最终式子可解释为:最大化 ELBO = 最大化数据的极大似然 + 最小化 q 和先验 p 的距离。
上述式子需要通过采样MC来估计,损失函数写作:
未完待续。。。
Reference
- A Short Introduction to Bayesian Neural Networks
- The very Basics of Bayesian Neural Networks
- Bayesian neural network introduction
- Bayesian Neural Networks(贝叶斯神经网络)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









