






#0
这篇文章的核心内容是「注解」,而为了介绍注解,则不得不涉及到关于Atomic、反射、接口以及类文件结构等概念,本文不打算对上述概念的细节进行深入,只会在必要的时候进行说明。
注解是在Java1.5中被引入的重要语言特性之一,简单来说,注解为存储有关程序「额外信息」提供了一种优雅易读的方式。本文将首先介绍注解的基本语法与使用,随后介绍自定义注解的实现方式,最后将通过阅读Class类中与注解有关的源码介绍「注解的原理机制」。
老规矩,先把本文涉及内容的思维导图奉上。
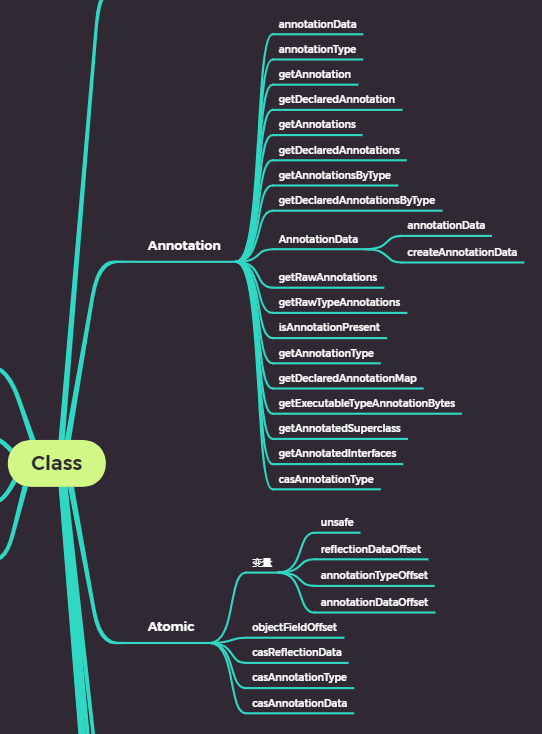
#1
Atomic是Class类中的内部类,用于提供一些「原子操作」。Atomic中存在几个重要字段,分别是
private static final Unsafe unsafe = Unsafe.getUnsafe();
// reflectionData字段的偏离量
private static final long reflectionDataOffset;
// annotationType字段的偏离量
private static final long annotationTypeOffset;
// annotationData字段的偏离量
private static final long annotationDataOffset;
在Class字节码文件结构中提到,Java会将编写好的.java编译成字节码文件(即以.class结尾的文件)。同样,Class类也不会例外。这些字节码文件是「一组以8位字节为基础单位的二进制流」,整个字节码文件的内容会按照.class文件格式规范依次排列。就如同C语言中数组的实现方式一样,C语言中的数组实际上是指向内存中的某个地址的指针,根据该「地址加上偏离量(offset)计算出的地址」获取数组元素。同理,通过Atomic中记录的偏离量计算在字节码文件中的位置获取对应字段的实际内容。
根据实例化对象时的加载顺序,静态代码块会在Atomic实例化时优先被加载,配合Atomic提供的objectFieldOffset方法,会在Atomic实例化完成前获取字段对应的偏离量。在这个方法中,反射部分中的老面孔(getDeclaredFields0和searchFields)又出现了
static {
Field[] fields = Class.class.getDeclaredFields0(false);
reflectionDataOffset = objectFieldOffset(fields, "reflectionData");
annotationTypeOffset = objectFieldOffset(fields, "annotationType");
annotationDataOffset = objectFieldOffset(fields, "annotationData");
}
private static long objectFieldOffset(Field[] fields, String fieldName) {
Field field = searchFields(fields, fieldName);
if (field == null) {
throw new Error("No " + fieldName + " field found in java.lang.Class");
}
return unsafe.objectFieldOffset(field);
}
获取字段对应的偏离量是通过Unsafe实现的,类如其名,使用这个类是「不安全的」。Unsafe类是Java提供用于「直接操作内存的工具」,而由于直接操作内存十分容易出问题(典型的就是C语言中越界访问数组出现的烫烫烫),因此Unsafe.getUnsafe()会对调用者进行检查。
public static Unsafe getUnsafe() {
Class> caller = Reflection.getCallerClass();
if (!VM.isSystemDomainLoader(caller.getClassLoader()))
throw new SecurityException("Unsafe");
return theUnsafe;
}
一旦调用者的ClassLoader不符合要求便会抛出异常。关于ClassLoader的话题还可以说很多,由于时间的篇幅的原因就不在这里细说了。有关ClassLoader的内容会在接下来的文章中进行说明。
借由Unsafe提供的能力,Atomic提供三个方法,能够「线程安全地对三个字段(reflectionData、annotationType和annotationData)进行替换」。
static boolean casReflectionData(Class> clazz,
SoftReference> oldData,
SoftReference> newData) {return unsafe.compareAndSwapObject(clazz, reflectionDataOffset, oldData, newData);
}static boolean casAnnotationType(Class> clazz,
AnnotationType oldType,
AnnotationType newType) {return unsafe.compareAndSwapObject(clazz, annotationTypeOffset, oldType, newType);
}static boolean casAnnotationData(Class> clazz,
AnnotationData oldData,
AnnotationData newData) {return unsafe.compareAndSwapObject(clazz, annotationDataOffset, oldData, newData);
}至于提供这三个方法的目的是什么呢?他们有什么作用呢?让我们先看casReflectionData的作用。
ReflectionData是Class中对于反射信息的缓存,当在运行时(Runtime)通过反射对字节码文件进行修改,那么反射信息的缓存就需要进行替换,这时casReflectionData就派上用场了,通过casReflectionData能够直接将内存中的数据进行修改。而casAnnotationType和casAnnotationData的作用会在后文对注解的原理机制部分进行说明。
#10
这部分将正式进入注解的部分。这部分包括「Class类中与注解有关的内容」,「java.lang.annotation中的大部分」(Annotation、Target、Inherited、Retention、Documented、ElementType、Native、Repeatable),以及「AnnotatedElement」等等。这部分将不会一开始就深入源码的细节,首先会介绍注解的作用、语法与使用,然后补充有关字节码文件结构的一些内容,最后会深入源码的细节说明注解的实现原理。
注解的作用、语法与使用
注解的作用
根据JSR-175标准,注解是一种用于类、方法、参数、变量、构造器以及包声明中的「特殊修饰符」,是描述元数据的一种工具。
简单来说,注解是一种「标记」,就如同标点符号一样,以句号。表示陈述句的完结,以问号?表示疑问句的完结。
标点符号有什么作用呢?
- 首先,它在文章中作为额外的信息。
- 其次,虽然没有标点符号阅读文章会比较吃力,但是它不会对文章原本的内容造成影响。
- 最后,它需要由阅读文章的人进行处理。
写代码就好比写文章,注解的作用
- 首先,注解是描述代码的代码,提供用来完整地描述程序所需的额外信息。
- 其次,注解没有行为只有数据,单纯的注解不会对代码的执行造成影响。
- 最后,注解需要配套的工具或代码进行处理。
说了这么多,让我们看一个例子,以JDK内建注解@Override为例,其作用是告诉编译器这个方法重写了父类中的方法
public class Father {
public void say(){
System.out.println("Father say");
}
}
public class Child extends Father{
@Override
public void say() {
System.out.println("Child say:");
}
}
父类Father和子类Child同样定义了方法,这时在子类的方法上加上注解和不加上注解,对于运行的结果都没有影响(「注解作用第二条」)。但是通过在编译器中进行了处理(「注解作用第三条」),作为代码编写规范的一种约束,并且告知阅读代码的人这个方法重写了父类方法(「注解作用第一条」)。
注解的语法
注解的使用很简单,只需要在类、字段、方法前面添加上即可,这在前面部分已经说明。
因此这部分让我们来看看一个最简单的例子,@Override的定义。
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
注解的定义看起来很像接口的定义。事实上,与其他任何Java接口一样,注解也将会编译成「字节码文件」。除了@interface关键字以外,还有一些元注解,比如@Target和@Retention。
@Target
其中@Target用来定义注解将应用在什么地方,@Target是元注解,这里的定义由「ElementType」决定。
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.ANNOTATION_TYPE)
public @interface Target {
ElementType[] value();
}
public enum ElementType {
// 用于类、接口(包括注解)、或者枚举
TYPE,
// 用于字段(包括枚举常量)
FIELD,
// 用于方法
METHOD,
// 用于方法参数
PARAMETER,
// 用于构造函数
CONSTRUCTOR,
// 用于局部变量
LOCAL_VARIABLE,
// 用于注解
ANNOTATION_TYPE,
// 用于包
PACKAGE,
// 用于类型参数
TYPE_PARAMETER,
// 用于类型
TYPE_USE
}
这里特别说明ElementType中的「ANNOTATION_TYPE」、「TYPE_PARAMETER」和「TYPE_USE」。
当注解定义上使用了@Target(ElementType.ANNOTATION_TYPE)意味着这个注解是可以用在其他注解上。
而类型参数与类型都是与占位符有关,比如下面代码中方法参数中的T和尖括号中的T分别对应着类型参数和类型。
public static void printArray (T[] inputArray)
{
for (T element : inputArray)
(
System.out.printlf("%s", element);
}
@Retention
Retention表示注解的生「效时期」,这由枚举类「RetentionPolicy」决定,其中枚举常量包括三种,对应注解的三种生效时期。
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.ANNOTATION_TYPE)
public @interface Retention {
RetentionPolicy value();
}
public enum RetentionPolicy {
// 注解在源码编译时生效
SOURCE,
// 注解在类加载时生效
CLASS,
// 注解在运行时生效
RUNTIME
}
其他元注解
| 注解 | 解释 |
|---|---|
| @Documented | 将此注解保存在 Javadoc 中 |
| @Inherited | 允许子类继承父类的注解 |
| @Repeatable | 允许一个注解可以被使用一次或者多次(Java 8) |
自定义注解
这部分将通过一个「自定义注解」的例子说明注解的其他语法,包括「注解元素」与「注解处理器」。注解@UseCase用于跟踪项目中用例。如果一个方法或一组方法实现了某个用例的需求,那么程序员可以为此方法加上该注解。于是,项目经理通过计算已经实现的用例,就可以很好地掌握项目的进展。
这段代码通过「反射」获取了Method数组(getDeclaredMethods()),然后遍历Method,判断方法上使用的注解其值是否为true(true表示该方法的代码已编写完成),然后计算方法完成率表示项目的进度。
// UseCase.java
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface UseCase {
public int id();
public String description() default "no description";
public boolean value();
}
// UseCaseDemo.java
public class UseCaseDemo {
@UseCase(id=1,value = true)
public void method1() {
System.out.println("Method1 finished");
}
@UseCase(id=2,value = true,description = "case finished")
public void method2() {
System.out.println("Method2 finished");
}
@UseCase(id=3,value = false,description = "not finished")
public void method3() {
System.out.println("Method3 finished");
}
}
// UseCaseTracker.java
public class UseCaseTracker {
public static void trackUseCases(Class> clazz) {
int finished = 0;
Method[] methods = clazz.getDeclaredMethods();
for(Method m : methods) {
UseCase uc = m.getAnnotation(UseCase.class);
if(uc.value()) finished++;
}
System.out.print("项目用例的完成率为:"+
((float)finished / (float) methods.length));
}
public static void main(String[] args) {
trackUseCases(UseCaseDemo.class);
}
}
注解@UseCase中定义了三种注解元素,包括int元素id,String元素description,以及boolean元素value。「注解元素」可用的类型如下所示:
- 所有基本类型(int,float,boolean等)
- String
- Class
- enum
- Annotation
- 以上类型的数组
在定义注解元素的时候,要么具有「默认值」,要么在「使用注解时提供元素的值」。
另外注解不支持使用关键字extends来「继承」某个@interface。而@Inherited存在的意义在于,@Inherited作为元注解声明某个@interface上,当该@interface加在父类上并且子类继承了父类,那么子类也会被加上该@interface。
@Repeatable是jdk8中新增的注解,它作为元注解声明某个@interface上,表明该注解可以「重复使用」。
字节码文件结构的补充
接下来的部分将进行源码解析。在此之前,有必要对字节码文件结构进行补充。
在字节码文件结构中,有一部分是常量池,常量池中主要存放两大类常量:「字面量和符号引用」。其中字面量指的是文本字面量(比如String str = "str";)、声明为final的常量值等。符号引用包括下面三大类常量
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
由于注解本质上是接口,因此在类中使用的注解,都会在该类字节码文件的常量池中存在其「全限定名」作为符号引用。
源码部分
annotationData
这部分我们以「getAnnotations」这个方法作为入口,getAnnotations能够获取调用者对应类中使用的所有注解,它的源码十分简单。
public Annotation[] getAnnotations() {
return AnnotationParser.toArray(annotationData().annotations);
}
区区一行即可实现。
进一步的,我们深入看一看annotationData()。
这部分的逻辑流程图如下:

private AnnotationData annotationData() {
// 死循环
while (true) {
// 先获取缓存
AnnotationData annotationData = this.annotationData;
int classRedefinedCount = this.classRedefinedCount;
// 如果缓存有效,那么返回缓存
if (annotationData != null &&
annotationData.redefinedCount == classRedefinedCount) {
return annotationData;
}
// 如果缓存无效,那么重新获取AnnotationData
AnnotationData newAnnotationData = createAnnotationData(classRedefinedCount);
// 尝试更新缓存
if (Atomic.casAnnotationData(this, annotationData, newAnnotationData)) {
// 更新成功即返回AnnotationData
return newAnnotationData;
}
}
}
在Class类中定义了类型为AnnotationData的私有字段annotationData作为「注解信息的缓存」。其中缓存机制的设计理念与反射中ReflectionData如出一辙,因而定义「AnnotationData」的思路也很相似。在获取最新的AnnotationData后,会通过内部类Atomic进行「线程安全的内存值替换」。
关键的步骤在于createAnnotationData这个方法。在再进一步深入之,先看看在AnnotationData中究竟缓存了哪些信息。
private static class AnnotationData {
final Map, Annotation> annotations;final Map, Annotation> declaredAnnotations;// 用于检查缓存是否失效final int redefinedCount;
AnnotationData(Map, Annotation> annotations,
Map, Annotation> declaredAnnotations,int redefinedCount) {this.annotations = annotations;this.declaredAnnotations = declaredAnnotations;this.redefinedCount = redefinedCount;
}
}根据定义,这里缓存的是「Class与Annotation的映射」。其中Class是类实例对象,尖括号中的? extends Annotation表示用于充当key的类实例对象都是实现Annotation接口的类实例对象。作为value的是Annotation,表示注解自身。
根据语法规则,所有使用@interface关键字定义的注解实际上都实现了Annotation接口。
AnnotationData里面缓存了两个映射集,其中annotations表示当前类及其父类中声明的注解映射集,而declaredAnnotations仅仅表示当前类中声明的注解映射集。
接下来是获取AnnotationData的方法createAnnotationData。
这个方法的执行逻辑如下。

private AnnotationData createAnnotationData(int classRedefinedCount) {
// 解析当前类的注解映射集
Map, Annotation> declaredAnnotations =
AnnotationParser.parseAnnotations(getRawAnnotations(), getConstantPool(), this);
Class> superClass = getSuperclass();
Map, Annotation> annotations = null;// 解析父类的注解映射集// 如果存在父类,递归地解析父类的注解映射集if (superClass != null) {
Map, Annotation> superAnnotations =
superClass.annotationData().annotations;for (Map.Entry, Annotation> e : superAnnotations.entrySet()) {
Class extends Annotation> annotationClass = e.getKey();// 如果父类的注解中有被@Inherited元注解声明的if (AnnotationType.getInstance(annotationClass).isInherited()) {if (annotations == null) { // 映射集的懒加载
annotations = new LinkedHashMap<>((Math.max(
declaredAnnotations.size(),
Math.min(12, declaredAnnotations.size() + superAnnotations.size())
) * 4 + 2) / 3
);
}// 将该注解放入映射集
annotations.put(annotationClass, e.getValue());
}
}
}// 如果没有从父类解析出注解映射集if (annotations == null) {// 那么返回当前类的注解映射集
annotations = declaredAnnotations;
} else {// 否则将父类的注解映射集加入
annotations.putAll(declaredAnnotations);
}// 实例化AnnotationDatareturn new AnnotationData(annotations, declaredAnnotations, classRedefinedCount);
}这部分的关键在于使用parseAnnotations解析注解信息,进入该方法进一步查看。
这个方法的逻辑流程如下所示。这个流程图将parseAnnotations和parseAnnotations2合并在一起。

public static Map, Annotation> parseAnnotations(byte[] rawAnnotations,
ConstantPool constPool,
Class> container) {if (rawAnnotations == null)return Collections.emptyMap();try {return parseAnnotations2(rawAnnotations, constPool, container, null);
} catch(BufferUnderflowException e) {throw new AnnotationFormatError("Unexpected end of annotations.");
} catch(IllegalArgumentException e) {throw new AnnotationFormatError(e);
}
}传入的参数中rawAnnotations是「按一定格式组织的字节数组」,这里的格式是根据「字节码文件结构要求」定义的。除了常量池,Java虚拟机规范定义字节码文件中应当具有属性表,其中「与注解有关的属性」有
- RuntimeVisibleAnnotations
- 运行时可见注解
- RuntimeInvisibleAnnotations
- 运行时不可见注解
- RuntimeVisibleParameterAnnotations
- 运行时可见方法参数注解
- RuntimeInvisibleParameterAnnotations
- 运行时不可见方法参数注解
- RuntimeVisibleTypeAnnotations
- 运行时可见类型注解
- RuntimeInvisibleTypeAnnotations
- 运行时不可见类型注解
具体规范要求不在这里详细展开,只提一点:上述所有属性定义结构中,都存在「两个字节长度的attribute_name_index」,表示该属性「在常量池中的索引」。这也是解析注解信息需要使用常量池的原因。
下一步,我们深入parseAnnotations2方法
private static Map, Annotation> parseAnnotations2(byte[] rawAnnotations,
ConstantPool constPool,
Class> container,
Class extends Annotation>[] selectAnnotationClasses) {
Map, Annotation> result =new LinkedHashMap, Annotation>();// 将字节数组拷贝至ByteBuffer
ByteBuffer buf = ByteBuffer.wrap(rawAnnotations);int numAnnotations = buf.getShort() & 0xFFFF;for (int i = 0; i // 不断地从ByteBuffer中解析出Annotation
Annotation a = parseAnnotation2(buf, constPool, container, false, selectAnnotationClasses);if (a != null) {// 获取Annotation的AnnotationType
Class extends Annotation> klass = a.annotationType();// 如果解析出的注解在运行时生效,并且重复定义,则抛出异常// 这里通过result.put(klass,a)将映射存入映射集if (AnnotationType.getInstance(klass).retention() == RetentionPolicy.RUNTIME &&
result.put(klass, a) != null) {throw new AnnotationFormatError("Duplicate annotation for class: "+klass+": " + a);
}
}
}// 将映射集返回return result;
}简单来说,这部分说的是根据规范规定的字节码文件格式,从字节码文件中获取表示注解的「二进制字节数组」,据此从常量池中「解析」出注解信息并返回。
当然往下还有更进一步的代码逻辑,但是在此之前我需要解释两个概念:「Annotation」和「AnnotationType」。AnnotationType用于表示「注解运行时信息」,比如注解的一些元注解信息(@Target和@Retention)和注解定义元素的信息。
public interface Annotation {
boolean equals(Object obj);
int hashCode();
String toString();
Class extends Annotation> annotationType();
}
public class AnnotationType {
// 注解元素的集合,key是元素的名字,value是元素的类型
private final Map> memberTypes;// 注解元素的集合,key是元素的名字,value是元素的默认值private final Map memberDefaults;// 注解元素的集合,key是元素的名字,value是元素的Methodprivate final Map members;// 表示注解生效时期的信息private final RetentionPolicy retention;// 表示注解是否被@Interited元注解修饰private final boolean inherited;// 一些暂时没有关系的方法
}注解本质上是一个接口,除了equals、hashCode和toString之外,还有一个获取运行时Class对象实例的方法annotationTye()。
上面代码的关键之处在于Annotation a = parseAnnotation2(buf, constPool, container, false, selectAnnotationClasses)中的parseAnnotation2,虽然名字和上一段代码片段中的方法名字是一样的,但是方法的作用完全不同。
private static Annotation parseAnnotation2(ByteBuffer buf,
ConstantPool constPool,
Class> container,boolean exceptionOnMissingAnnotationClass,
Class extends Annotation>[] selectAnnotationClasses) {
// 获取索引
int typeIndex = buf.getShort() & 0xFFFF;
Class extends Annotation> annotationClass = null;
String sig = "[unknown]";
try {
try {
// 根据索引从常量池里获取全限定名sig
sig = constPool.getUTF8At(typeIndex);
// 根据全限定名生成Class实例
annotationClass = (Class extends Annotation>)parseSig(sig, container);
} catch (IllegalArgumentException ex) {
// 向前兼容的处理,之前版本的字节码文件格式不同
annotationClass = (Class extends Annotation>)constPool.getClassAt(typeIndex);
}
} catch (NoClassDefFoundError e) {
// 这里表示是否在发生异常时将异常抛出
if (exceptionOnMissingAnnotationClass)
throw new TypeNotPresentException(sig, e);
// 跳过两字节
skipAnnotation(buf, false);
return null;
}
catch (TypeNotPresentException e) {
if (exceptionOnMissingAnnotationClass)
throw e;
skipAnnotation(buf, false);
return null;
}
// 在本文涉及的内容中不会执行
if (selectAnnotationClasses != null && !contains(selectAnnotationClasses, annotationClass)) {
skipAnnotation(buf, false);
return null;
}
// 根据Class获取AnnotationType
// 即根据类型的运行时信息获取注解的额外信息
AnnotationType type = null;
try {
type = AnnotationType.getInstance(annotationClass);
} catch (IllegalArgumentException e) {
skipAnnotation(buf, false);
return null;
}
// 两个映射集的键是注解定义的元素名称
// 注解定义的元素类型
Map> memberTypes = type.memberTypes();// 注解定义的元素值,初始化使用默认值
Map memberValues =new LinkedHashMap(type.memberDefaults());int numMembers = buf.getShort() & 0xFFFF;for (int i = 0; i int memberNameIndex = buf.getShort() & 0xFFFF;// 从常量池里获取元素名称的信息
String memberName = constPool.getUTF8At(memberNameIndex);
Class> memberType = memberTypes.get(memberName);if (memberType == null) {// Member is no longer present in annotation type; ignore it // 如果元素类型不存在,则跳过
skipMemberValue(buf);
} else {// 从常量池中解析
Object value = parseMemberValue(memberType, buf, constPool, container);// 会出现类型不匹配的情况,不过暂时忽略这个异常路径if (value instanceof AnnotationTypeMismatchExceptionProxy)
((AnnotationTypeMismatchExceptionProxy) value).
setMember(type.members().get(memberName));// 更新映射集
memberValues.put(memberName, value);
}
}// 返回结果return annotationForMap(annotationClass, memberValues);
}这段代码的逻辑是先从bytebuf中读取「索引」,根据索引从常量池中获取注解的「全限定名」,然后根据全限定名生成「Class实例」。
根据Class实例得到「AnnotationType实例」,随后构建「两个映射集」,其中memberTypes的key是注解定义元素的名称,value是注解元素的返回类型;memberValues的key是注解定义元素的名称,value是注解元素的实际值。
完整的逻辑流程图如下所示。

最后来看看是如何构建返回值的
public static Annotation annotationForMap(final Class extends Annotation> type,final Map memberValues){
return AccessController.doPrivileged(new PrivilegedAction() {public Annotation run() {return (Annotation) Proxy.newProxyInstance(
type.getClassLoader(), new Class>[] { type },new AnnotationInvocationHandler(type, memberValues));
}});
}根据语法规定,接口是无法实例化对象的。这里的做法是使用「动态代理」,返回的实际上是Annotation接口的代理类。使用「Proxy.newProxyInstance」构造代理类需要传入三个参数,分别是
- 代理类的类加载器
- 一组代理类需要实现的接口
- 调用处理器
上述代码片段传入的是type的类加载器,即注解的类加载。接口是Annotation。
「调用处理器」是这部分的关键,再进一步深入查看调用处理器是如何生成代理类的。
// 构造函数
AnnotationInvocationHandler(Class extends Annotation> type, Map memberValues) {
Class>[] superInterfaces = type.getInterfaces();if (!type.isAnnotation() ||
superInterfaces.length != 1 ||
superInterfaces[0] != java.lang.annotation.Annotation.class)throw new AnnotationFormatError("Attempt to create proxy for a non-annotation type.");this.type = type;this.memberValues = memberValues;
}public Object invoke(Object proxy, Method method, Object[] args) {
String member = method.getName();
Class>[] paramTypes = method.getParameterTypes();// 处理Object和Annotation中定义的方法if (member.equals("equals") && paramTypes.length == 1 &&
paramTypes[0] == Object.class)return equalsImpl(args[0]);if (paramTypes.length != 0)throw new AssertionError("Too many parameters for an annotation method");switch(member) {case "toString":return toStringImpl();case "hashCode":return hashCodeImpl();case "annotationType":return type;
}// 处理注解自定义元素的访问// 实际上是通过之前获取的映射集完成的
Object result = memberValues.get(member);if (result == null)throw new IncompleteAnnotationException(type, member);if (result instanceof ExceptionProxy)throw ((ExceptionProxy) result).generateException();if (result.getClass().isArray() && Array.getLength(result) != 0)
result = cloneArray(result);return result;
}invoke用于处理使用代理类时的方法调用。根据Annotation的定义,invoke包括两个部分。一部分是Annotation定义的方法,比如equals、hashCoe和annotationType等,另外一部分是用于获取注解元素的,这部分通过解析注解parseAnnotation2时构建的映射集完成。
至此getAnnotations涉及的流程已经全部讲解完毕。
get系列方法
Class类文件中定义了七个用于获取注解的方法,分别是
- getAnnotation
- getAnnotations
- getAnnotationsByType
- getDeclaredAnnotation
- getDeclaredAnnotations
- getDeclaredAnnotationsByType
- getDeclaredAnnotationMap
这七个方法最终都会调用annotationData(),借助AnnotationData获取字节码文件中的注解信息。
在说明这七个方法之间的区别之前,先描述以下四个概念,这个概念出自接口AnnotatedElement的描述文件中,如果把原版文字放上来很难理解,因此这里给出的是我自己的理解。
注解分为四种,分别是
- directly present
- 直接声明的注解
- indirectly present
- 间接声明的注解,即容器注解数组中的注解
- present
- 直接声明(directly present)注解和父类继承下来的直接声明注解的合集
- associated
- 直接声明注解、间接声明注解以及父类继承下来的注解的合集
打个比方,分别定义Foo、Bar和BarList三个注解
// Foo.java
@Retention(RUNTIME)
@Inherited
public @interface Foo {}
// Bar.java
@Retention(RUNTIME)
@Inherited
@Repeatable(BarList.class)public @interface Bar {}
// BarList.java
@Retention(RUNTIME)
@Inherited
public @interface BarList {
Bar[] value();
}
然后注解的使用如下所示
// Parent.java
@Foo
@BarList({@Bar, @Bar})
public class Parent {}
// Child.java
public class Child extends Parent {}
其中Foo是「直接声明注解」,而Bar是「间接声明注解」。因为Bar的注解定义被@Repeatable声明了。
理解了这几个概念后,以上七个方法返回的注解对象可用下表来表示
| 方法 | directly | indirectly | present | associated |
| getAnnotation | * | |||
| getAnnotations | * | |||
| getAnnotationByType | * | |||
| get DeclaredAnnotation | * | |||
| get DeclaredAnnotations | * | |||
| get Declared AnnotationsByType | * | |||
| get Declared AnnotationMap | * | * |
AnnotationType
AnnotationType表示注解运行时信息。Class类能够表示类运行时信息,那么为什么多余设计AnnotationType呢?
AnnotationType中定义的字段和方法是在使用注解运行时信息时频繁使用的。虽然开发者使用Class类中定义的方法也能够完成使用要求,但是由于注解语法的特性,设计出AnnotationType进行处理(比如判断注解的生效时期,获取注解元素的值与默认值等)会更加便捷高效。
下面从源码角度看一看。
public class AnnotationType {
// 定义了一些字段
// 包括元素类型映射集、元素默认值映射集、元素映射集、Retention策略和是否能够继承
// ...
// 根据注解运行时信息构建AnnotationType
public static AnnotationType getInstance(
Class extends Annotation> annotationClass){
JavaLangAccess jla = sun.misc.SharedSecrets.getJavaLangAccess();
AnnotationType result = jla.getAnnotationType(annotationClass); // volatile read
if (result == null) {
result = new AnnotationType(annotationClass);
// try to CAS the AnnotationType: null -> result
if (!jla.casAnnotationType(annotationClass, null, result)) {
// somebody was quicker -> read it's result
result = jla.getAnnotationType(annotationClass);
assert result != null;
}
}
return result;
}
private AnnotationType(final Class extends Annotation> annotationClass) {
if (!annotationClass.isAnnotation())
throw new IllegalArgumentException("Not an annotation type");
// 先获取注解元素
Method[] methods =
AccessController.doPrivileged(new PrivilegedAction() {public Method[] run() {// Initialize memberTypes and defaultValuesreturn annotationClass.getDeclaredMethods();
}
});// 注解元素名->注解元素返回类型的映射集
memberTypes = new HashMap>(methods.length+1, 1.0f);// 注解元素名->注解元素返回默认值的映射集
memberDefaults = new HashMap(0);// 注解元素名->注解元素方法的映射集
members = new HashMap(methods.length+1, 1.0f);// 遍历注解元素for (Method method : methods) {// 根据语法定义,注解元素对应的方法不存在方法参数if (method.getParameterTypes().length != 0)throw new IllegalArgumentException(method + " has params");// 获取注解元素名
String name = method.getName();// 获取注解元素返回类型
Class> type = method.getReturnType();// 置入映射集
memberTypes.put(name, invocationHandlerReturnType(type));// 置入映射集
members.put(name, method);// 获取注解元素默认返回值
Object defaultValue = method.getDefaultValue();if (defaultValue != null)// 置入映射集
memberDefaults.put(name, defaultValue);
}// Initialize retention, & inherited fields. Special treatment// of the corresponding annotation types breaks infinite recursion.// 处理注解生效期和是否可继承属性if (annotationClass != Retention.class &&annotationClass != Inherited.class) {
JavaLangAccess jla = sun.misc.SharedSecrets.getJavaLangAccess();
Map, Annotation> metaAnnotations =
AnnotationParser.parseSelectAnnotations(
jla.getRawClassAnnotations(annotationClass),
jla.getConstantPool(annotationClass),
annotationClass,
Retention.class, Inherited.class
);
Retention ret = (Retention) metaAnnotations.get(Retention.class);
retention = (ret == null ? RetentionPolicy.CLASS : ret.value());
inherited = metaAnnotations.containsKey(Inherited.class);
}else {
retention = RetentionPolicy.RUNTIME;
inherited = false;
}
}// 这个方法的目的是将基础类型转换成包装类型public static Class> invocationHandlerReturnType(Class> type) {// ...
}// 一些用于字段的get方法// ... public String toString() {return "Annotation Type:\n" +" Member types: " + memberTypes + "\n" +" Member defaults: " + memberDefaults + "\n" +" Retention policy: " + retention + "\n" +" Inherited: " + inherited;
}
}AnnotationType中最重要的方法是getInstance。
很明显,这个方法需要涉及到「sun.misc.SharedSecrets」和「sun.misc.JavaLangAccess」完成从Annotation实例转换成AnnotationType实例的过程,由于篇幅关系SharedSecrets和JavaLangAccess的具体细节不在此表述。简单来说,JavaLangAccess的getAnnotationType()最终会调用Class的getAnnotationType()。
AnnotationType getAnnotationType() {
return annotationType;
}
Class中的方法会直接返回私有实例annotationType。但是根据Class的定义,私有实例annotationType一开始是null。因此在第一次调用AnnotationType的getInstance时是通过「AnnotationType的构造函数」将annotationType实例创建,随后通过Class的私有实例进行「缓存」。
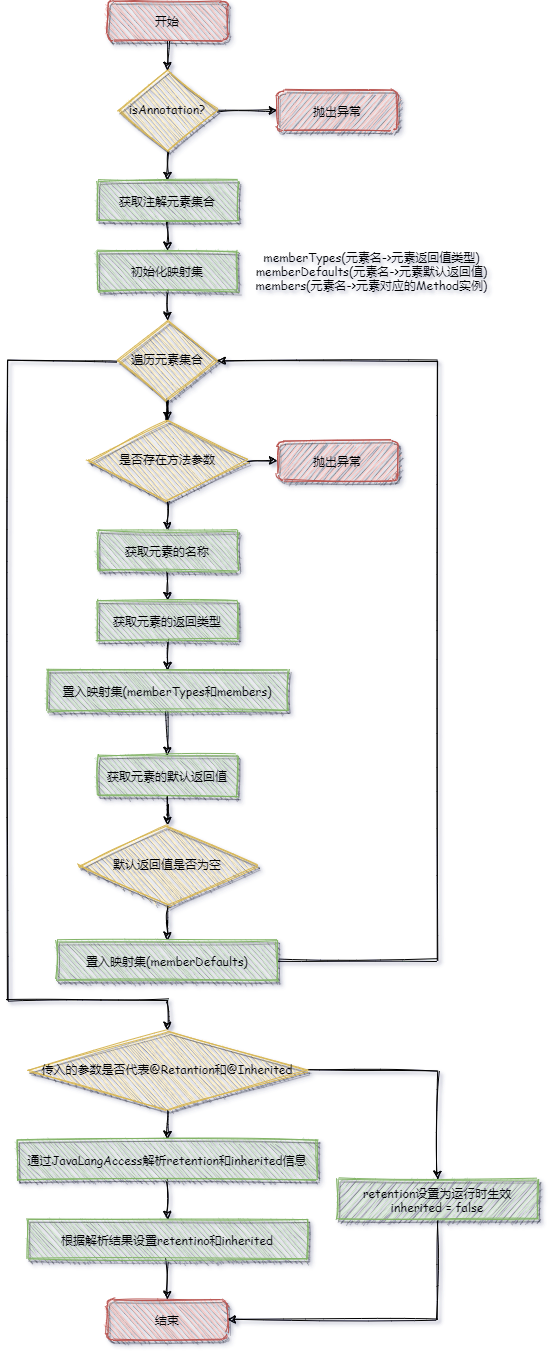
AnnotationType的构造函数中能够看到根据Class实例构建AnnotationType实例的过程。具体的逻辑请参考流程图。
Type Annotation
TypeAnnotation和AnnotationType的变量定义非常类似,但是两者表示的意思却大相径庭。
AnnotationType表示的是注解的运行时信息,而TypeAnnotation用在任何使用 「Type」 的地方。
//初始化对象时
String myString = new @NotNull String();
//对象类型转化时
myString = (@NonNull String) str;
//使用 implements 表达式时
class MyList<T> implements @ReadOnly ListReadOnly T>{
...
}
//使用 throws 表达式时
public void validateValues() throws @Critical ValidationFailedException{
...
}
TypeAnnotation还可以作用于泛型的占位符T上。
TypeAnnotation被设计出来的作用是「提升软件质量和开发效率」。由此展开又是一个大话题了,在此不赘述。
在Class中与此相关的方法有
native byte[] getRawTypeAnnotations();
// Constructor和Method继承Executable
// 这是在获取其他情况下使用的TypeAnnotation
static byte[] getExecutableTypeAnnotationBytes(Executable ex) {
return getReflectionFactory().getExecutableTypeAnnotationBytes(ex);
}
// 在使用 extends 表达式时使用的TypeAnnotation
public AnnotatedType getAnnotatedSuperclass() {
if (this == Object.class ||isInterface() ||isArray() ||isPrimitive() ||this == Void.TYPE) {
return null;
}
return TypeAnnotationParser.buildAnnotatedSuperclass(getRawTypeAnnotations(), getConstantPool(), this);
}
// 在使用 implements 表达式时使用的TypeAnnotation
public AnnotatedType[] getAnnotatedInterfaces() {
return TypeAnnotationParser.buildAnnotatedInterfaces(getRawTypeAnnotations(), getConstantPool(), this);
}
与getRawAnnotations()类似,根据字节码文件定义的格式,获取与TypeAnnotation有关的「字节数组」。
其余三个方法都是获取不同情况下使用的TypeAnnotation,以AnnotatedType表示。
public interface AnnotatedType extends AnnotatedElement {
// 返回的是被TypeAnnotation声明的Type(类型)
public Type getType();
}
AnnotatedType继承自AnnotatedElement,在Java8之前,AnnotatedElement表示那些能够被「常规注解」(即除了TypeAnnotation以外的注解)声明的类、方法、参数等等。
根据源码,AnnotatedType包括四种
- AnnotatedArrayType
- AnnotatedParameterizedType
- AnnotatedTypeVariable
- AnnotatedWildcardType
分别表示「数组类型」、「参数类型」、「变量类型」和「泛型类型」。
#11
这篇文章从注解作用开始,介绍了注解的「基本语法」以及「自定义注解的使用」。
随后以getAnnotations为例,从源码角度分析了「获取注解的流程」。该流程包括几大部分
- AnnotationData「缓存」设计
- 「解析原始字节数组」,并构建AnnotationData
- 解析原始字节数组,并「构建Annotation的代理类」
然后介绍了注解的「四大类型」,并通过一张表格说明Class中诸多获取注解方法的差异。
最后就AnnotationType和TypeAnnotation进行了详细的介绍。
本文涉及的范围十分广泛,不仅仅涉及了Class中定义的源码,还涉及到如下内容
- 「与注解语法有直接关系的」
- java.lang.annotation包下的Target、Retention等等
- 「与获取注解信息有关的」
- 比如用于解析原始字节数组的AnnotationParser
- 表示注解信息的Annotation和AnnotationType
- 动态代理Proxy
- 「用于Type的注解」
- AnnotatedType
感谢大家的观看,这篇文章我很满意,写得很开心:)
接下来是与泛型有关的内容。















 566
566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









