







什么是MVCC?原理是什么样的?
MVCC是InooDB中的多版本控制,是一种并发控制。当事务执行的时候会生成一个readview,在不同的隔离级别下生成readview的时机也不一样,MVCC支持RC和RR两种隔离级别,它们生成readview的时机分别是:
RR:在第一条select语句执行的时候,后面的事务内语句共用这个readview
RC:在每一条select语句执行的时候都要新建readview
readview包含两个东西,一个是创建readview的时候所有活跃的事务id数组,它的最小值就是低水位,以及所有创建事务的id中最大值+1,为高水位。
在UNDOlog中包含数据的各个版本信息,其中这个版本就是对这个数据进行更改的事务ID号,当事务去取自己应该看见的值的版本的时候,有三种情况:
1、 版本在低水位之下:在视图创建前已经提交的事务,可见。
2、 版本在高水位之上:在视图生成的时候还没创建的事务,不可见
3、 版本在低水位高水位之间:1.在数组中表示在视图创建的时候还没提交不可见。2.不再数组中,表示已经提交了,可见。
当系统里没有比这个回滚日志更早的 read-view 的时候,会删除旧的undolog
索引的选择/如果一个sql很慢是什么原因:
首先创建索引的时候可以使用覆盖索引减少回表,或者使用联合索引搭配最左前缀原则来减小索引的数目,减小维护的一个成本。还有当联合索引匹配的时候如果打破了最左前缀,比如like,可以使用5.6的索引下推功能进一步的做条件匹配,减小回表的次数,如果是机械硬盘的,随机读写开销很大,可以开启mrr,Multi range read,使用一个buffer来对主键一个排序,将随机读取转为顺序读取。另外如果业务能保证唯一性的时候,且对于写多读少的业务来说。可以使用普通索引代替唯一索引,因为普通索引实际上有一个change buffer,能够先把更改缓存下来,当需要使用的时候再把数据页从磁盘读到内存然后执行change buffer中和这个页有关的操作,merge到数据页上,可以减小磁盘的随机访问。
sql很慢的原因可能是索引取错了,可以使用慢查询日志,set long_querytime=0,分别对应该选中的索引(force index)和实际选中的索引进行分析,通过rows_examined字段可以看到执行器调用的次数。可能是优化器在算基数的时候可能出现了错误,优化器中扫描行数是影响代价的因素之一。但不是唯一标准,还会结合是否使用临时表、是否排序等因素综合判断。那么为了更准确,可以先查看一下基数,这就是索引的统计信息,使用show index查看,还可以使用explain来看rows字段是不是和预估的差不多,如果差的多,可以使用analyze table命令,重新计算表的统计信息。或者临时的使用force index。或者修改sql语句引导优化器知行希望的索引。在有些场景下,我们可以新建一个更合适的索引,来提供给优化器做选择,或删掉误用的索引。
在刷脏页,比如redolog写满了,就需要flush到硬盘上。或者内存不足,需要淘汰一些脏页,在淘汰前就需要flush到硬盘。写操作会瞬间跌到0,innodb_io_capacity可以控制刷脏页的速度,innodb_max_dirty_pages_pct 是脏页比例上限。在硬盘性能还不错的时候尽量的提高这个值,可以尽快的将脏页刷新到硬盘。一旦一个查询请求需要在执行过程中先 flush 掉一个脏页时,这个查询就可能要比平时慢了。而且mysql中还会连带把邻居一起刷新,如果使用机械硬盘的话还可以,因为你会减小很多随机io,但比较好的硬盘的话,尽量关闭这个功能。
是否有隐形的函数转换,比如字段类型不一样,可能会对性能有一定的影响
表项太多,空洞太多,可以使用alter table来重建表。
show processlist可以看看是不是在等待锁。
或者是不是更新操作频繁,导致undolog很长。
binlog和redolog
首先是两阶段提交
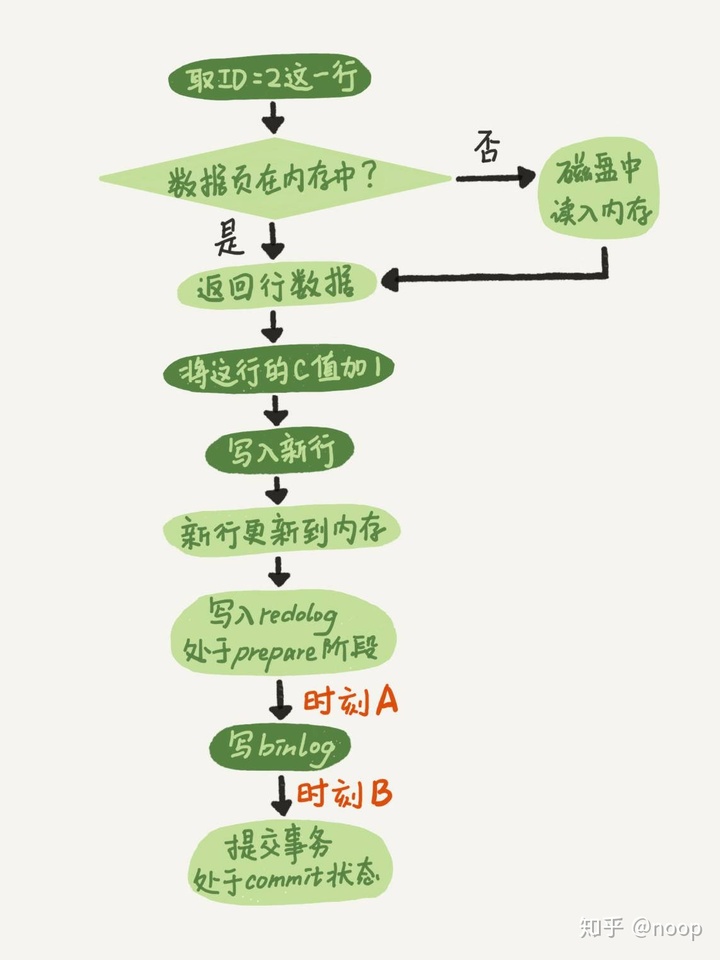
如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;
如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整:a. 如果是,则提交事务;b. 否则,回滚事务。
那么mysql是怎么知道binlog是完整的?statement的binlog最后会有一个commit,row 格式的 binlog,最后会有一个 XID event。在5.6.2以后还引入了binlog-checksum用来验证 binlog 内容的正确性。redolog和bilog有个共同的字段XID,崩溃恢复的时候,会顺序扫描redolog,如果碰到既有 prepare、又有 commit 的 redo log,就直接提交;如果碰到只有 parepare、而没有 commit 的 redo log,就拿着 XID 去 binlog 找对应的事务。
不使用两阶段提交就会出现问题,反正一下,要么先写完redolog再写binlog,要么先写完binlog再写redolog。前者的话,如果binlog不完整redolog完整,就会导致主从不一致。如果是后者的话,在redolog前崩溃就会判断失误是无效的,但是binlog里记录了这个日志,所以回复的时候就会多一个事务出来。
为什么不用一个日志就好了?首先binlog恢复时机控制不好,因为MySQL写数据是写在内存里的,不保证落盘,所以commit1的数据也可能丢失;但是恢复只恢复binlog失败的也就是commit2的数据,所以数据会丢失。再者binlog也没那个能力,因为没有页面信息。
使用redolog恢复的过程也是先写脏页再持久化到硬盘,不会直接从redolog到硬盘。
binlog和redolog写入时机
binlog 的写入逻辑比较简单:事务执行过程中,先把日志写到 binlog cache,事务提交的时候,再把 binlog cache 写到 binlog 文件中。
write 和 fsync 的时机,是由参数 sync_binlog 控制的
sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
InnoDB 提供了 innodb_flush_log_at_trx_commit 参数
设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 ;设置为 1 的时候,表示每次事务提交时都将 redo log 直接持久化到磁盘;设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 page cache。
explain的字段

主备一致
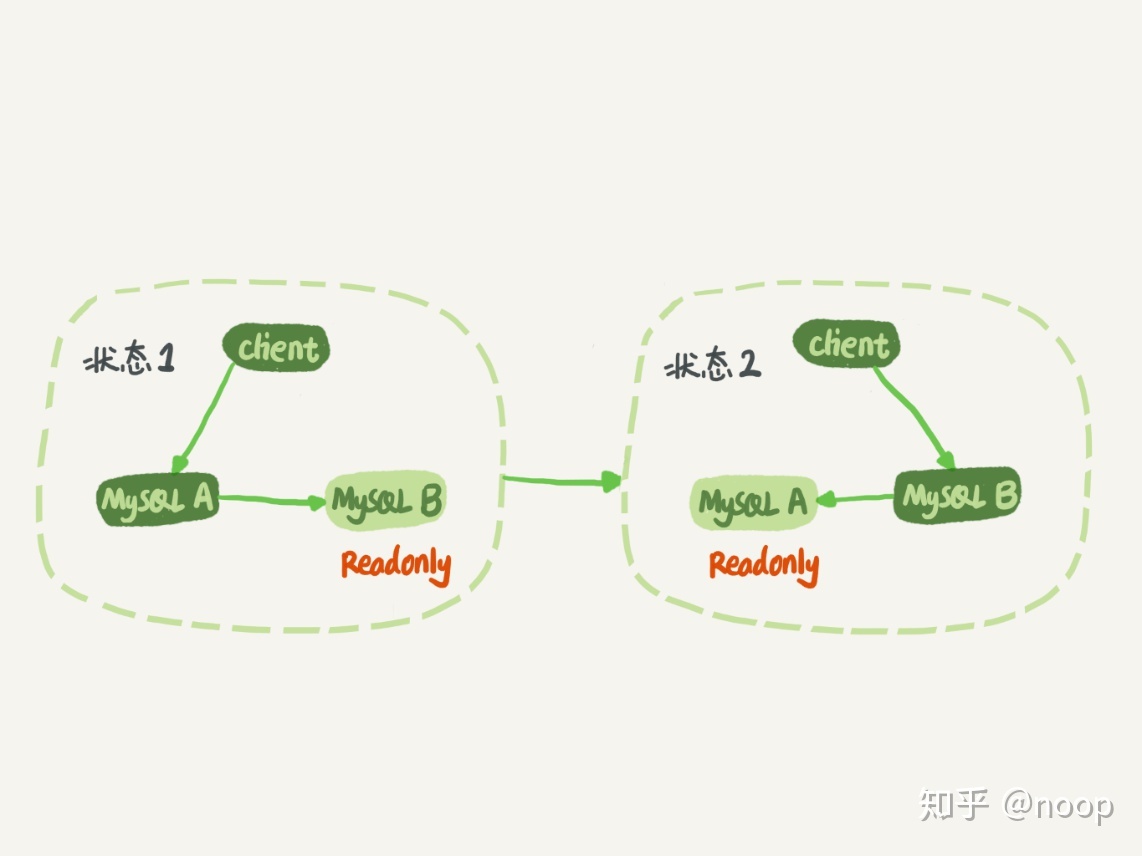
每次对主库的更新都会被同步到备库。
一般都将备库设置为read-only的,因为防止误操作,防止切换的时候有bug,出现双写,在一个也比较容易判断身份。但是只读对超级权限无效,可以用超级权限来更新。
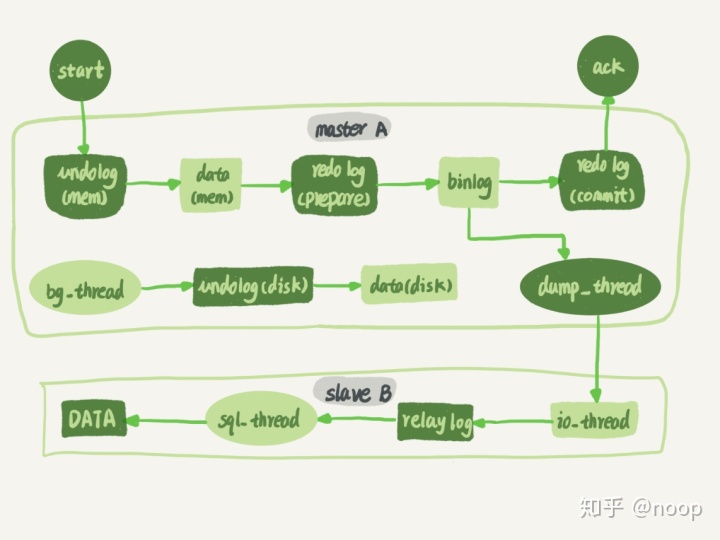
流程如上图,首先使用change master设置主库的ip端口用户名密码,以及从哪一个位置开始请求binlog。执行start slave,就是iothread和sqlthread,主库从本地读取binlog,发送给从库,拿到binlog以后写到本地文件,为relaylog 然后执行。















 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









