






声明:本文以学习为目的,请不要影响他人正常判题
HDU刷题神器,早已被前辈们做出来了,不过没有见过用python写的。大一的时候见识了学长写这个,当时还是一脸懵逼,只知道这玩意儿好屌…。时隔一年,决定自己实现这个功能。
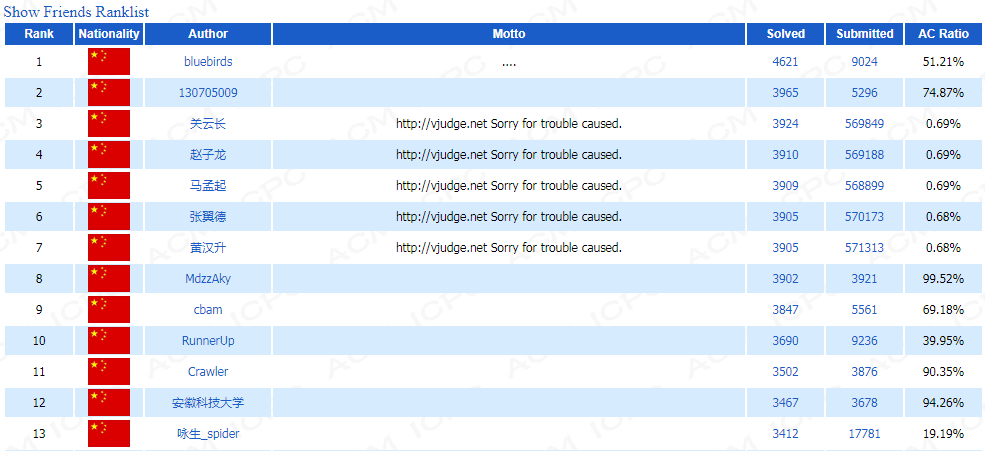
刷到第13名,AC率不高,因为,搜索引擎搜到的结果,往后就很难找到正确的代码了
首先对辛苦刷题的acmer和hdu的管理员道歉,各位,抱歉。
介绍整体思路:
整体用多线程:线程执行从爬代码到提交的全部过程
分层次:对搜索引擎搜索的结果,进行划分,分层爬取
局部思路:
爬取搜索引擎得到的与题目相关的url,得到url_list
爬取url_list中的url,扒到代码就提交
检查提交结果,WA之后继续爬取url_list中的代码
循环,直到列表为空或者AC
相关模块:
threadpool线程池,分配线程任务,多线程并发提交代码
用requests模块发送请求
正则爬取url和代码
Sqlite存放AC代码(打表啊,再申请个账号从数据库中提交代码100%AC)
1)采用线程池实现多线程,注意控制最大并发数量
搜索引擎使用CSDN的搜索,因为我们爬取的代码全都来自CSDN的博客,可以看一下其他论坛,博客的代码:

(右键,在新标签页中打开查看高清图片)


(右键,在新标签页中打开查看高清图片)

哦,这实在太不友好了,而CSDN博客的代码就好很多了(尽管很友好了,class和name有些先后顺序不一样,也会添乱)

所以,我们决定扒CSDN博客的代码。
搜索引擎的选择,CSDN(部分搜索结果是百度提供的)

其实,第一想到的是百度的,然而。。。

加密了,增大了我们的工作量,所以,就直接用CSDN的(也有百度的结果)
在CSDN搜索结果的最下方,我们可以看到上图中有14W结果(好唬人啊),其实事情是这样的:
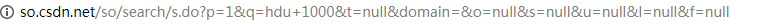

这是一个搜索hdu 1000的url,我们注意到用的get()方法传数据,发现只有p=?,试一下就知道,这个是页码。如果页码改为200呢?
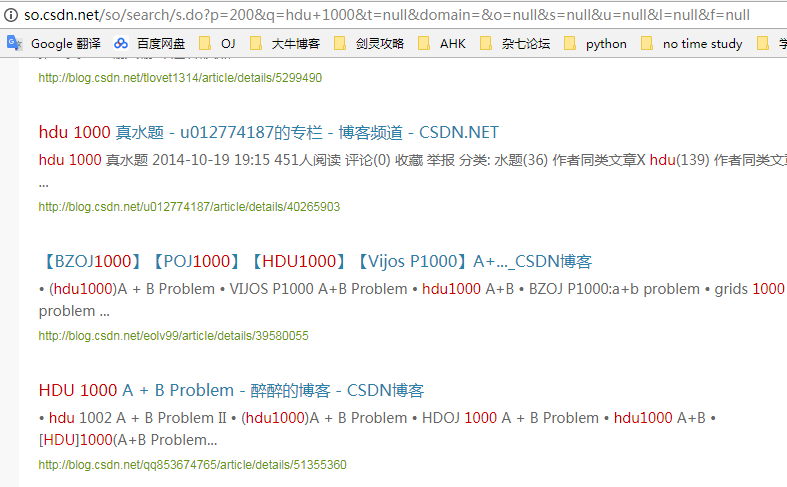
100?
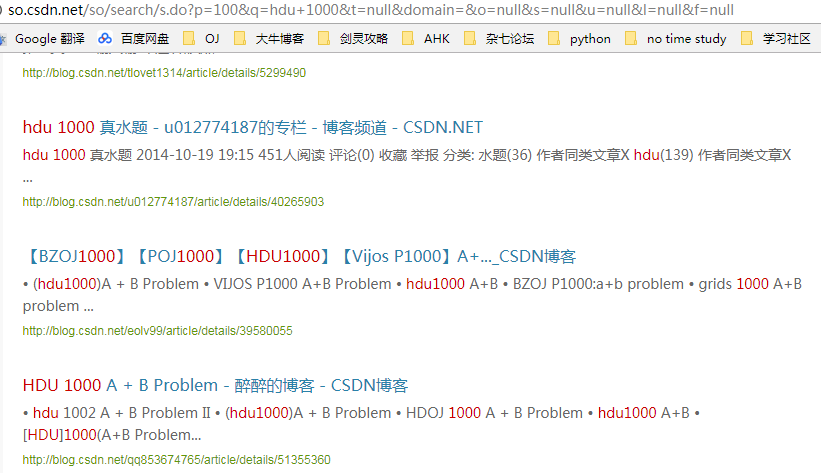
开玩笑啊,14W结果呢?最后我们得出结论:搜索结果只有76页,而且越往后,得到我们想要代码的可能性就越小,所以我只爬到20页就结束程序
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









