






有n个楼梯,每次可以走一阶或两阶,请问有多少种走法?
面试官说出这个的时候,我笑了笑,斐波那契?
反手就是一个
复制代码
递归求解
function MapSort(num){
if(num==1||num==2){
return 1
}
return MapSort(num-1) + MapSort(num-2)
}
复制代码
这种性能不够好,可以优化吗,面试官继续问道。我:不能。。
如果再回到那一天,我想我会好好跟他解释解释什么叫做递归的优化
复制代码
什么是递归
百科上的解释是:程序调用自身的编程技巧称为递归
复制代码
嗯,看了等于没看
一般来说递归至少有2个要点
* 不能无限制地调用本身,须有个出口,化简为非递归状况处理(递归结束条件)
* 子问题须与原始问题为同样的事,且更为简单(找到函数的规律)
我们拿一个阶乘来分析
6! 计算6的阶乘
function fact(n) {
if (n <= 0) { //递归结束条件
return 1;
}
return n * fact(n - 1); //找到函数的规律
}
fact(6) //得出6的阶乘
复制代码
当我们计算 fact(6) 的时候,会产生如下展开
6 * fact(5)
6 * (5 * fact(4))
6 * (5 * (4 * fact(3))))
//疯狂调用自身
6 * (5 * (4 * (3 * (2 * (1 * 1)))))) // <= 一步步的递进,完全展开
复制代码
展开不是为了好看,是为了计算
6 * (5 * (4 * (3 * (2 * 1)))))
6 * (5 * (4 * (3 * 2))))
6 * (5 * (4 * 6)))
....
720 // <= 一步步的归并,得出结果
复制代码
通过递进和最后的归并,我们完成了我们的递归。但是结果并不完美。
单纯的阶乘,当数量到达5w级别的时候 直接报错,没错,是堆栈溢出

复杂度更高的算法,比如上例的斐波那契使用递归,数字50的计算时间都需要100s+
堆栈溢出
在解决问题之前,我们应该先找到问题,为什么会堆栈溢出,我们不是有垃圾回收机制吗?
这个在这里简单解释一下,详细的连接放在下面有兴趣的可以自己去查看
首先垃圾回收机制有两种机制
* 引用计数(如果一个对象指向它的引用数为0,那么他就会被回收)
这种情况机制下,如果两个对象相互引用,即使已经不在使用,但还是无法被垃圾回收机制清除
* 标记清除(从根部root去能到达的一切都不会被清除)
总的来的说,做好以下几点就可以垃圾回收机制所清除
* 减少不必要的全局变量,或者生命周期较长的对象,及时对无用的数据进行垃圾回收;
* 注意程序逻辑,避免“死循环”之类的 ;
* 避免创建过多的对象 原则:不用了的东西要及时归还
复制代码
而在我们上述的递归方法中,我们由于每一次递归运算都会新建并保存之前的堆栈,会导致我们的垃圾回收机制无法正常运行
所以我们首先考虑,有很多值已经运算过了,那可不可以利用起来呢
说干就干!
利用私有变量存储运算结果
让我们在看一眼之前的写法
function MapSort(num){
if(num==1||num==2){
return 1
}
return MapSort(num-1) + MapSort(num-2)//会产生大量重复的运算
}
fib(45) //看一下运算时间
复制代码
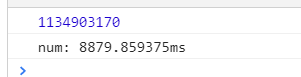
比如 MapSort(3) 会计算 MapSort(2) + MapSort(1),
而 MapSort(2) 又会计算 MapSort(1) + MapSort(0)。
这个 MapSort(1) 就是完全重复的计算,不应该为它再递归调用一次,而是应该在第一次求解除它了以后,就把他“记忆”下来。
把已经求得的解放在 Map 里,下次直接取,而不去重复结算。
这里用立即执行函数函数形成一个闭包,保留了 memo 这个私有变量,这是一个小技巧
let fib = (function(){
let memo = new Map();
return function(n){
//如果memo有值就使用,不重复计算
let memorize = memo.get(n)
if(memorize){
return memorize
}
if(n==1||n==2){
return 1
}
memo.set(n-1,fib(n-1))
memo.set(n-2,fib(n-2))
return fib(n-1) + fib(n-2)
}
})()
//fib(45) //可以看到,使用变量缓存甚至能够提高上万倍的效率
复制代码
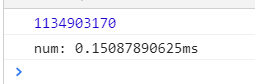
问题解决了吗?并没有。当我们传入万级的数据时,依然会栈溢出,
就像刚刚提到的,这种方法借用闭包保存变量的特性,虽然减少了重复运算,但是依然无法被垃圾回收机制清理
复制代码
尾调用优化
我们知道,函数调用会在内存形成一个"调用记录",又称"调用帧"(call frame)
保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用记录上方,
还会形成一个B的调用记录。等到B运行结束,将结果返回到A,B的调用记录才会消失
如果函数B内部还调用函数C,那就还有一个C的调用记录栈,以此类推。所有的调用记录,
就形成一个"调用栈"(call stack)
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
复制代码
递归非常耗费内存,因为需要同时保存成千上百个调用记录,很容易发生"栈溢出"错误(stack overflow)。但对于尾递归来说,由于只存在一个调用记录,所以永远不会发生"栈溢出"错误
上面计算6的阶乘是一个阶乘函数,计算n的阶乘,最多需要保存n个调用记录,复杂度 O(n) 。
复制代码
如果改写成尾递归,只保留一个调用记录,复杂度 O(1) 。
function fact(n, total) {
if (n === 1) return total;
return fact(n - 1, n * total);
}
fact(5, 1) // 120
复制代码
严格模式
ES6的尾调用优化只在严格模式下开启,正常模式是无效的。
这是因为在正常模式下,函数内部有两个变量,可以跟踪函数的调用栈。
arguments:返回调用时函数的参数。
func.caller:返回调用当前函数的那个函数。
复制代码
尾调用优化发生时,函数的调用栈会改写,因此上面两个变量就会失真。严格模式禁用这两个变量,所以尾调用模式仅在严格模式下生效
本文只是提供一个思想,有的地方没有特别详细,有错误的地方希望能被指正
复制代码
参考文章















 2862
2862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









