






Manticore Search简介:
参考文档:https://manual.manticoresearch.com/Introduction
Manticore Search 是一个使用 C++ 开发的高性能搜索引擎,创建于 2017 年,其前身是 Sphinx Search 。Manticore Search 充分利用了 Sphinx,显着改进了它的功能,修复了数百个错误,几乎完全重写了代码并保持开源。这一切使 Manticore Search 成为一个现代,快速,轻量级和功能齐全的数据库,具有出色的全文搜索功能。Manticore Search目前在GitHub上开源,支持不同的操作系统,如
windows,linux等。同时开源者在GitHub介绍中明确说明了该项目是是Elasticsearch的良好替代品,在不久的将来就会取代ELK中的E,官方文档里有对比数据,显示查询效率比ES快很多,下面是官方文档提供的说明。
1、对于小型数据,比MySQL快182倍(可重现)
2、对于日志分析,比 快29倍(可重现)
3、对于小型数据集,比Elasticsearch快15倍(可重现)
4、对于中等大小的数据,比Elasticsearch快5倍(可重现)
5、对于大型数据,比Elasticsearch快4倍(可重现)
6、在单个服务器上进行数据导入时,最大吞吐量比Elasticsearch快最多2倍(可重现)
Manticore的数据类型可以分为两类:全文字段(full-text fields)和属性(attributes);
全文字段:
1、可以使用自然语言处理算法进行索引,因此可以搜索关键字
2、不能用于排序或分组
3、可以检索原始文档的内容
4、原始文档的内容可用于突出显示
5、全文字段由数据类型文本表示。所有其他数据类型都称为“属性”。
属性:
属性是与每个文档相关联的非全文值,可用于在搜索过程中执行非全文过滤、排序和分组。通常,不仅需要根据匹配的文档ID及其排名,还需要根据每个文档的许多其他值来处理全文搜索结果。例如,可能需要按日期和相关性对新闻搜索结果进行排序,或者搜索指定价格范围内的产品,或者将博客搜索限制为选定用户的帖子,或者按月份对结果进行分组。为了有效地做到这一点,Manticore不仅允许全文字段,还允许向每个文档添加其他属性。这些属性可用于筛选、排序或分组全文匹配,或仅按属性进行搜索。与全文字段不同,这些属性没有进行全文索引。它们存储在表中,但无法将它们作为全文进行搜索。
最多可以指定256个全文字段和任意数量的属性。所有既不是文档ID(第一个)也不是属性的列都将作为全文字段进行索引。全文匹配子句可以与属性筛选器组合为AND布尔值。不支持全文匹配和属性筛选器之间的OR关系。
建表的字段类型说明:
Text:文本(仅为文本或文本/字符串索引)数据类型构成表的全文部分。文本字段被编入索引,并且可以搜索关键字。例:content text
String:与全文字段不同,字符串属性(仅为字符串或字符串/文本属性)在接收时存储,不能用于全文搜索。相反,它们在结果中返回,可以在WHERE子句中用于比较筛选或REGEX,也可以用于排序和聚合。通常,不建议将大型文本存储在字符串属性中。例:author string。
如果还想为字符串属性编制索引,可以将两者都指定为已编制索引的字符串属性。它将允许全文搜索,并作为属性使用。例:title string attribute indexed
Integer:32位整数存储。例:total_num int
BigInt:64位整数存储。例:price bigint
Boolean:布尔属性。它相当于一个位计数为1的整数属性。例:flag bool
Float: 实数存储为32位IEEE 754单精度浮点。例:coeff float
Timestamps:时间戳类型表示存储为32位整数的unix时间戳。例:date timestamp
JSON:这种数据类型允许存储JSON对象,这对于存储无模式数据非常有用。例:data json
Multi-value integer (MVA):多值属性允许存储32位无符号整数的可变长度列表。例:product_codes multi
Multi-value big integer:一种允许存储64位有符号整数的可变长度列表的数据类型。例:values multi64
Manticore Srearch的安装:
这里作为测试,安装的是Manticore Search的windows版本安装包,下载地址: https://manticoresearch.com/install/
我下载的是manticore-6.2.12-230822-dc5144d35-x64.exe版本,安装完成后,在安装目录下的Manticore\bin\searchd.exe双击 启动
linux版本,可根据官方文档安装,这里没有环境安装,不作说明。
windows启动日志:
Manticore Search的java方法调用介绍:
Manticore Search支持通过http访问操作,默认端口9312或者9308,也可通过mysql连接方式连接,默认端口9306(可使用mysql客户端或dbeaver等连接)。 建表语句如: CREATE TABLE a_test(title string attribute indexed, contents text, author_id bigint, a_id int, post_date timestamp,a_type int) charset_table = 'english,cjk,0..9' morphology = 'stem_en,icu_chinese' 文章下的sql查询语句与代码操作语句基于此表来测试,其中charset_table设置英文,中文,数字都被分词,morphology是设置了中文和英文分词器,不然存储了中文也检索不到,只能检索到英文单词,Manticore Search 3.1.0 版引入了一种基于ICU文本分割算法的中文文本分割新方法,感觉默认的ICU中文分词效果一般,这里不对中文分词展开说明。
Manticore Search目前支持PHP、pyshon、java等语言的客户端集成,下面主要介绍java客户端的集成,和一些对Manticore Search的查询、新增、删除等操作的工具代码展示和说明。
1、在pom.xml加入如下配置引入jar包: <dependency> <groupId>com.manticoresearch</groupId> <artifactId>manticoresearch</artifactId> <version>3.3.1</version> <scope>compile</scope> </dependency>
2、java提供的客户端工具主要是用http进行接口访问。发送sql语句的工具方法:
import com.alibaba.fastjson.JSONObject;
import com.manticoresearch.client.ApiClient;
import com.manticoresearch.client.ApiException;
import com.manticoresearch.client.api.IndexApi;
import com.manticoresearch.client.api.SearchApi;
import com.manticoresearch.client.api.UtilsApi;
import com.manticoresearch.client.model.*;
import lombok.extern.slf4j.Slf4j;
import java.util.List;
@Slf4j
public class demoManticoreTest {
public static void main(String[] args) {
ApiClient defaultClient = com.manticoresearch.client.Configuration.getDefaultApiClient();
defaultClient.setBasePath("http://127.0.0.1:9312");
// defaultClient.setUsername("");
// defaultClient.setPassword("");
UtilsApi utilsApi = new UtilsApi(defaultClient);
try {
//创建表
List<Object> createResultList = utilsApi.sql("CREATE TABLE a_test(title string attribute indexed, contents text, author_id bigint, a_id int, post_date timestamp,a_type int) charset_table = 'english,cjk,0..9' morphology = 'stem_en,icu_chinese'", true);
System.out.println(createResultList);
//插入数据
List<Object> insertResultList = utilsApi.sql("insert into a_test(title,contents,author_id,a_id,post_date,a_type) values('测试demo','SCG对战平台:平台简介:SCG(SuperChinaGame)对战平台是一款线上电子竞技对战平台,于2013年3月上线测试运营。',66,1,1697678523,1)", true);
System.out.println(insertResultList);
//查询数据
List<Object> selectResultList = utilsApi.sql("select * from a_test where a_id=1", true);
System.out.println(selectResultList);
//删除表
// List<Object> dropResultList = utilsApi.sql("DROP TABLE a_test", true);
// System.out.println(dropResultList);
} catch (Exception e) {
log.info("error:{}", e);
}
}
}UtilsApi.sql方法可以向manticoresearch发送sql语句进行操作,sql语句和mysql类似,但不完全一致。下面列举一些manticoresearch的sql语句:
[1]查看表结构数据:
desc a_test;
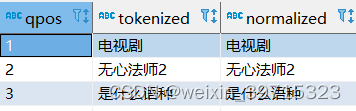
[2]测试分词结果:
call keywords('电视剧《无心法师2》是什么语种', 'a_test');
使用的分词器效果一般,如果需要比较理想的搜索效果,建议建一个关键词全文字段,关键词用空格隔开,会按照空格分词,可以准确匹配到关键词
返回如下所示:
[3]匹配查询:
--对所有索引字段全文检索,本文中的a_test表有tilte和contents加了索引
select * from a_test where match('SCG对战平台');
--对属性字段进行模糊查询,全文字段不可使用,否则报错
select * from a_test where REGEX(title, '^*测试*');
[4]其它查询类似mysql,比如分页,排序和分组:
--属性字段才能用 = 来查询,全文字段只能用match,比如contents,否则返回报错(stored field, NOT attribute) select * from a_test where a_id=1 limit 0,10; --排序方式asc和desc必须要加 select * from a_test order by id asc; --分组 select count(*) from a_test group by a_type
3、使用IndexApi对manticoresearch进行增删改操作
(1)bulk操作:
[1]新增
IndexApi indexApi = new IndexApi(defaultClient);
String insertBody = "{\"insert\": {\"index\" : \"a_test\", \"id\" : 6415491626298245122,\"doc\":{\"a_type\" : 2,\"title\":\"测试demo insert\",\"author_id\":77,\"a_id\":2,\"contents\":\"测试demo五经得起几分俏皮\"}}}";
BulkResponse insertBulkResult = indexApi.bulk(insertBody);
System.out.println(insertBulkResult);[2]修改
String body = "{\"update\": {\"index\" : \"a_test\", \"id\" : 6415491626298245121, \"doc\":{\"a_type\" : 2,\"title\":\"测试demo\",\"a_id\":1}}}";
BulkResponse bulkResult = indexApi.bulk(body);bulk方法能够调用成功,但是响应的数据无法转换成BulkResponse实体类导致报错,后续发现是版本问题,之前3.3.0版本有问题,更新成3.3.1后没有问题了。
(1)新增:
InsertDocumentRequest newdoc = new InsertDocumentRequest();
HashMap<String, Object> insetDoc = new HashMap<String, Object>() {{
put("title", "测试标题demo");
put("contents", "地球之肺是指亚马逊雨林,它是地球上最大的热带雨林,覆盖了南美洲大部分地区。亚马逊雨林拥有丰富的生物多样性,是地球上最重要的生态系统之一。");
put("author_id", 888);
put("a_id", 2);
put("post_date", new Date().getTime());
put("a_type", 1);
}};
newdoc.index("a_test").id(6L).setDoc(insetDoc);
SuccessResponse insertResult = indexApi.insert(newdoc);新增文档数据时,如果指定了id的值,则id使用指定的值存储,否则会生成long类型的id
(2)修改/替换
//修改文档
UpdateDocumentRequest updateDoc = new UpdateDocumentRequest();
Map<String, Object> doc = new HashMap<>();
doc.put("a_type", 3);
doc.put("title", "测试demo2");
doc.put("post_date", System.currentTimeMillis());
updateDoc.index("a_test").id(6L).setDoc(doc);
UpdateResponse uResult = indexApi.update(updateDoc);根据id更新,更新只能更新属性字段,如果更新是全文字段就会报错。目前此方法可根据id更新,根据query条件更新执行无作用。
//替换文档
InsertDocumentRequest docRequest = new InsertDocumentRequest();
Map<String, Object> doc = new HashMap<String,Object>(){{
put("title", "测试标题demo3");
put("contents", "地球之肾一般指湿地生态系统。 湿地生态系统属于水域生态系统。其生物群落由水生和陆生种类组成,物质循环、能量流动和物种迁移与演变活跃,具有较高的生态多样性、物种多样性和生物生产力");
put("author_id", 666);
put("a_id", 2);
put("post_date", new Date().getTime());
put("a_type", 0);
}};
docRequest.index("a_test").id(6L).setDoc(doc);
Object rResult = indexApi.replace(docRequest);根据id替换文档,类似于删除再插入的动作
(3)删除
DeleteDocumentRequest deleteRequest = new DeleteDocumentRequest();
deleteRequest.index("a_test").id(1L);
Object result = indexApi.delete(deleteRequest);根据id删除文档,根据query条件删除不起作用,会全删除,这个可能是工具客户端问题
4、使用SearchApi对manticoresearch进行查询操作
SearchApi searchApi = new SearchApi(defaultClient);
SearchRequest searchRequest = new SearchRequest();
//相等条件查询,只能作用于属性字段,否则报错
EqualsFilter equalsFilter = new EqualsFilter();
equalsFilter.setField("a_type");
equalsFilter.setValue(1);
searchRequest.setAttrFilter(equalsFilter);
// EqualsFilter equalsFilter3 = new EqualsFilter();
// equalsFilter3.setField("a_id");
// equalsFilter3.setValue(10);
//
// BoolFilter fBoolFilter = new BoolFilter();
// //多个相等条件筛选
// fBoolFilter.setMust(Arrays.asList(equalsFilter,equalsFilter3));
// searchRequest.setAttrFilter(fBoolFilter);
//模糊匹配查询,根据分词结果匹配,适用于全文字段
MatchOpFilter matchOpFilter = new MatchOpFilter();
matchOpFilter.setQueryString("顶楼");
matchOpFilter.setQueryFields("contents");
matchOpFilter.setOperator(MatchOpFilter.OperatorEnum.OR);
searchRequest.setFulltextFilter(matchOpFilter);
//分页,最多返回1000条数据,也就说只能对1000条数据分页,不适合业务分页查询
searchRequest.setLimit(10);
searchRequest.setOffset(0);
//根据属性字段排序
List<Object> sort = Lists.newArrayList();
SortOrder sortOrder = new SortOrder();
sortOrder.setAttr("id");
sortOrder.setOrder(SortOrder.OrderEnum.DESC);
sort.add(sortOrder);
searchRequest.setSort(sort);
SearchResponse searchResponse = searchApi.search(searchRequest);返回结果打印输出如下:
class SearchResponse { took: 0 timedOut: false aggregations: {} hits: class SearchResponseHits { maxScore: null total: 73 totalRelation: eq hits: [{id=1187, _score=1, _source={title=电视剧《顶楼 第二季》是什么语种?1187_jiping, contents=1187电视剧《顶楼 第二季》的语种是韩语, a_id=1187, a_type=1, author_id=5, post_date=4193561957}}, {id=1178, _score=1, _source={title=电视剧《顶楼 第二季》是什么语种?1178_jiping, contents=1178电视剧《顶楼 第二季》的语种是韩语, a_id=1178, a_type=1, author_id=5, post_date=4193561940}}] } profile: null warning: {} }
说明:
(1)搜索报错时,无法转换为SearchResponse对象,会报json解析的异常如:com.fasterxml.jackson.databind.exc.MismatchedInputException: Cannot deserialize value of type com.manticoresearch.client.model.SearchResponse from Array value (token JsonToken.START_ARRAY),这个可以拉取源码自己修改下返回解析,或者到git上反应这个客户端问题,期望后续版本应该会修复。
(2)使用属性字段做match匹配查询,或者使用全文字段做equals精准匹配查询都会报错
Manticore Search总结
1、Manticore的原生语法是SQL,它支持HTTP上的SQL和MySQL协议,允许通过任何编程语言的流行MySQL客户端进行连接,但和mysql的sql语句并不完全相同。同时也提供了类似于Elasticsearch的HTTPJSON协议
2、Manticore提供了java、python、php、.net等客户端,可以通过api调用访问Manticore的数据,本文就java客户端做了说明,但目前来看客户端还不够成熟,还需优化。
3、Manticore产品本身目前安装起来比较方便,对各种语言的集成方式支持广泛,但却有许多问题,还需慢慢迭代,个人的使用来看感觉与es还有差距。

















 1509
1509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









