





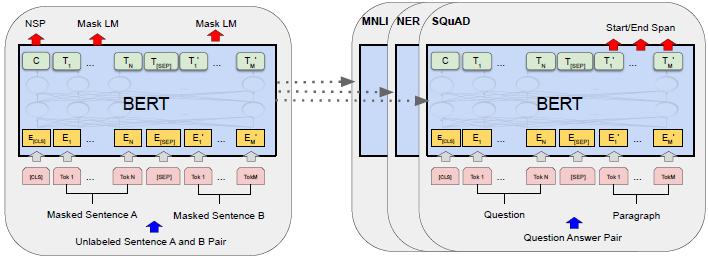
前言:最近在自己的RL方法里尝试加入BERT,想用base model却总是遇到OOM,观察内存占用量多数时候也就不到2GB,一到模型更新阶段占用率就蹭蹭蹭往上涨,一个不小心涨过头不是OOM就是killed... orz 为了溯源,开始看源码分析内存占用相关因素,分析完还意犹未尽,就有了这么一篇经验帖。
这篇文章的主要内容包括:
1、BERT模型结构梳理;
2、BERT参数统计;
3、BERT内存占用分析;
想要知道是哪些因素导致了大量内存占用,我们首先要知道BERT模型里到底做了些啥。
BERT的模型实质上就是Transformer encoder的堆叠,但Transformer里又包含Multi-head Attention,dropout、残差、layer normalization等,这些又具体是怎样组织的?对于这些问题,看论文只能理解个大体,要真实感受还是code来得更直接(当然,建议看代码前先把论文读了:[Transformer][BERT])。下面开始介绍我根据源码得出对BERT的模型结构的理解:
一、BERT模型结构梳理:
1.1、总体结构:
在我看来,BERT的模型总体由两大块组成,即Embedding Layer和Transformer Layers,此外还有一些对输出做的后处理(比如pooler)。BERT模型的总体结构如下图所示:
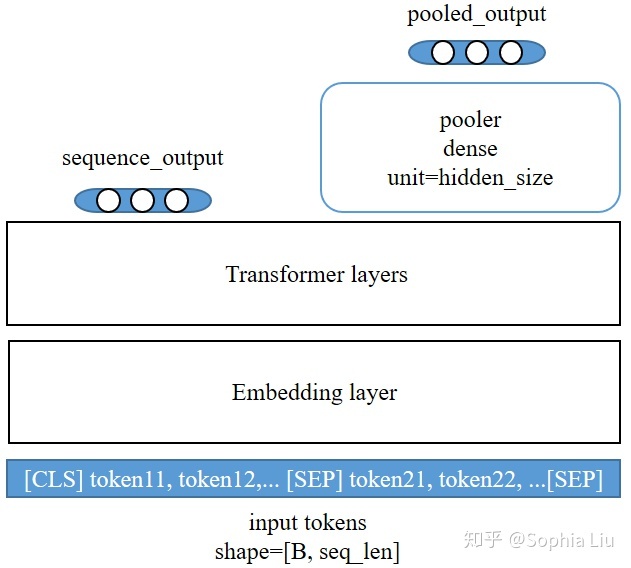
变量解释:
B: batch size, 即每次输入给BERT的sequence的个数;
seq_len:sequence的最大长度,即最长sequence中token的个数(不超过512);
L: BERT模型中Transformer的个数,如tiny model中L=2, base model中L=12, large model中L=24;
H: 也即hidden_size, 指BERT最终输出的向量维数,例如每个token会得到一个H维的向量作为embedding,
在tiny model中H=128, base model中H=768, large model中H=1024;
E: 也即embedding_size,指embedding layer输出的向量维数,BERT中要求E==H;
A: 即Multi-head Attention的head数,H必须能被A整除,从而得到每个head输出的向量维数=H/A;
vocab_size: 即Embedding Layer对token做embedding时使用到的vocabulary中包含的token数,BERT中为30000;
type_size: 即定义的token类型的个数,这部分只有当任务重指定了token类别才有用,是个可选的部分;
position_size: 即sequence中token位置的个数,可以看作是position embedding的词汇表的规模,等于512;
图形解释:
黑色矩形:表示复杂模块,将在后续展开讲解;
蓝色圆角矩形:表示全连接网络,或embedding变量;
蓝色直角矩形:表示layer_norm;
灰色圆角矩形:表示dropout;
灰色直角矩形:表示按位求和;
(灰色图形都没有待学参数)模型的输入是一系列的token序列,事先用BERT提供的tokenizer转化成token id的形式,所以BERT模型的输入是规模为[B, seq_len]的由token id构成的tensor。这些序列通过Embedding Layer得到每个token的初始向量表示,再经过Transformer得到最终的输出,sequence_output是最后一层Transformer的输出,包含输入序列中各token的向量表示。
在句子级的任务中,会需要对每个序列有一个向量表示,于是就有了pooled_output,它来自于最后一层Transformer对序列的首个token(即[CLS])的输出,经过一层全连接网络而得到。
这个操作之所以叫"pooler", 跟avg-pooling, max-pooling这些pooling操作并没有关系,而是指得到的pooled_output是对整个序列中所有token信息的汇集结果。
1.2、Embedding Layer
Embedding Layer的任务是为输入的每个token构建一个初始向量表示。这个初始向量表示与BERT最终得到的向量表示最大的不同点在于,前者是上下文无关的(context independent),而后者是上下文相关的(context dependent)。
这一部分的作用可以用BERT论文中的下图来表示:

而模型的结构可以理解为下图所示,即每一类Embeddings都对应一组待学变量。每个token得到的这三类embedding向量按位求和(element-wise add),并用layer_norm做归一化(因为求和改变了向量各维值的scale)。
layer_norm操作即在每个embedding向量内部各维之间做normalization,注意要和batch_norm做区分,batch_norm是在一个batch内的样本之间做normalization。
下图是Embedding Layer的代码结构,其中的token_type_embed(名称来源于源码)应该对应上图中的Segment Embeddings部分,type_size取决于用户输入数据时标记的segment的数量。
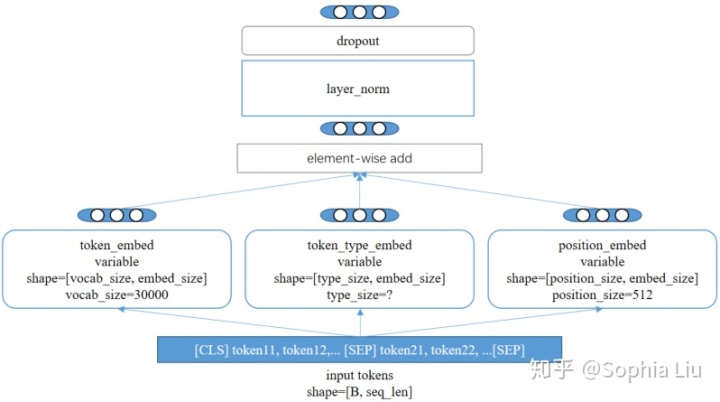
Embedding Layer的主要任务是学得对每个token的embedding。上图中三个蓝色圆角矩形,分别通过对token的某部分信息(word one-hot, token-type, position)加权变换来得到embedding向量,各权值是待学变量。Embedding Layer的输出是为每个token都得到一个融合了上述三种信息的embedding向量。
注意:Embedding Layer生成的这个向量是上下文无关的(content independent),即,只与token本身的内容(对应词表中第几个词?被标记为哪种type?在句子中处于什么位置?)相关,而句子中其他词不相关;
这要与BERT最终输出的embedding有所区别,BERT最终也输出每个token对应的embedding,但由于用到了multi-head attention,这个embedding是融合了句子中其他token的信息的,所以是上下文相关的(content dependent)。
1.3、Transformer Layers
参考:
BERT原论文
BERT GoogleResearch源码;
issue















 167
167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









