







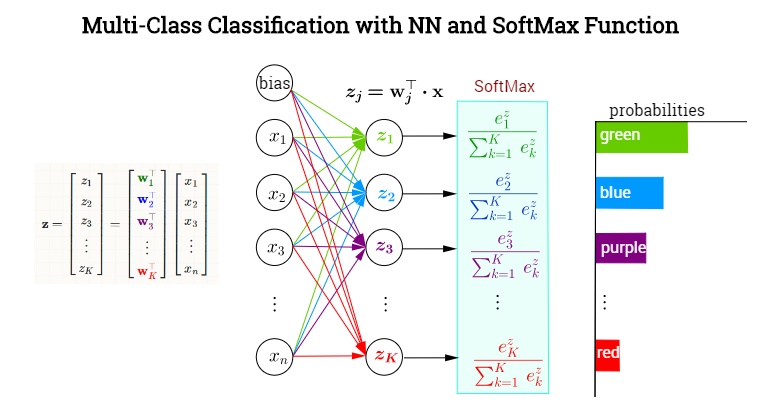
一、什么是 softmax 回归?
softmax 回归(softmax regression)其实是 logistic 回归的一般形式,logistic 回归用于二分类,而 softmax 回归用于多分类,关于 logistic 回归可以看我的这篇博客
小胡子:机器学习-logistic回归原理与实现zhuanlan.zhihu.com
对于输入数据
其中,
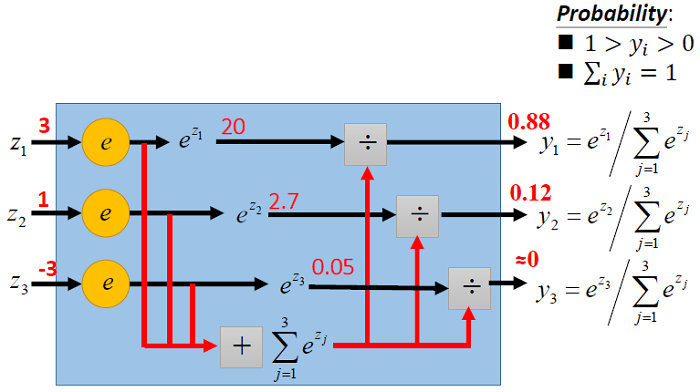
上面的式子可以用下图形象化的解析(来自台大李宏毅《一天搞懂深度学习》)。
二、原理
2.1 梯度下降法参数求解
softmax 回归的参数矩阵
定义 softmax 回归的代价函数
其中,1{·}是示性函数,即1{值为真的表达式}=1,1{值为假的表达式}=0。跟 logistic 函数一样,利用梯度下降法最小化代价函数,下面求解
感谢 CSDN 博主[2]提供了另外一种求解方法,具体如下
2.2 模型参数特点
softmax 回归有一个不寻常的特点:它有一个“冗余“的参数集。为了便于阐述这一特点,假设我们从参数向量
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 660
660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









