






写在开头
- 以下内容所用术语并不一定是标准的, 流程也不一定是专业的, 我仅仅是尽量表述明白, 请轻喷, 谢谢各位大哥大姐头了, 多原谅一下这个彩笔.
- 这是个很基础的小工程, 没什么技术含量, 看完以后你可能会觉得: 就这? 对...就这...
- 这个文章可能会稍微有点长, 其中的一些设计部分都是我自己瞎搞的, 也许并不是精通编译原理或者是其他领域的大哥大姐头们能够接受的, 但是也是自己尝试了很久, 使用了很多办法最后找到的一条比较适合的. 总之也请原谅我, 感激不尽.
嘛我实现的最终效果长这样, 如果您看着动心, 不妨耐着性子看下去吧...

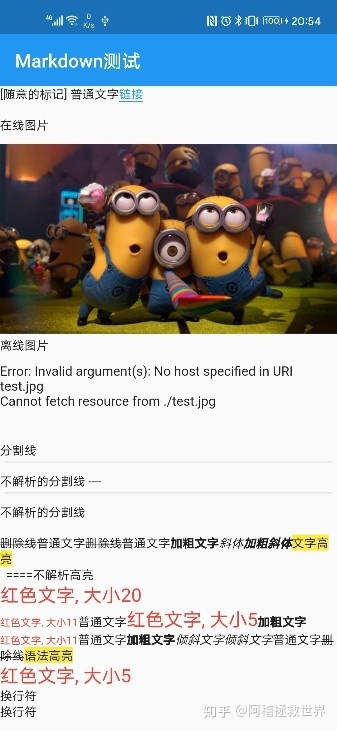
问题引入
Flutter的Markdown解析一直是一大痛点. 虽然官方已经有flutter_markdown这个插件帮助我们搞定Markdown文本到Widget的转换了, 但是它并不是非常令人满意, 而且现在似乎还有止步不前的趋势. 什么代码块的语法高亮啊, 一些简单的html标签, 比如字体的样式显示, 都没法得到很好地支持, 可是在flutter_markdown的代码里, 却是有着不少Markdown标记转html标签再做Widget转换的成分, 想必在这样的基础上实现颜色支持应该也不是一件难事的说...
在这样的使用需求下, 我曾尝试用正则表达式直接替换掉flutter_markdown的代码块部分, 直接用dart packages上一个很优秀的高亮轮子flutter_highlight来搞定代码高亮, 效果很显著, 显示效果就像演示图的第一张那样, 但是别人的轮子终究不是自己的, 每当自己提出更新的需求时, 功能的添加就变得越发的困难, 所以最后, 我还是决定自己写一个轮子, 这个轮子要求有如下几点:
- 直接通过解析Markdown内部的标签转换成Flutter的组件, 也就是从原来flutter_markdown的这种流程:
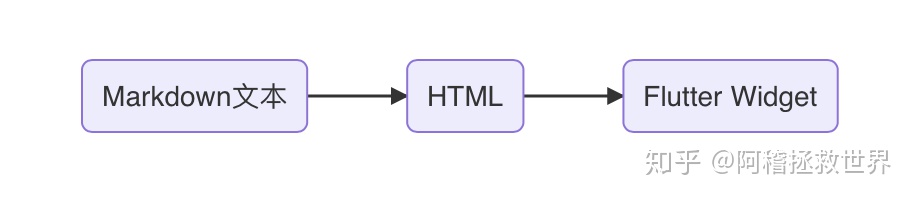
变成这样的流程:
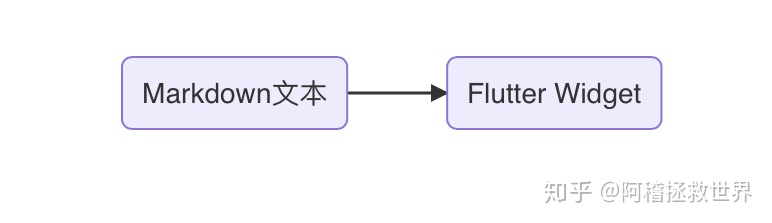
2. 所有的Markdown标记必须实现灵活的解析, 这就是说, 再块级标记上遵循一定程度的优先级顺序, 而在每一行的字体样式等方面采用灵活的解析和转换模式, 这一点几乎是废话
3. 必须创建一个支持解析标记的列表或者字典, 所有的标记识别和转换必须独立运作. 也就是说, 可以直接通过简单的增加和减少解析功能, 来实现对解析器的拓展, 而不影响插件整体的稳定性, 大概就像这样:
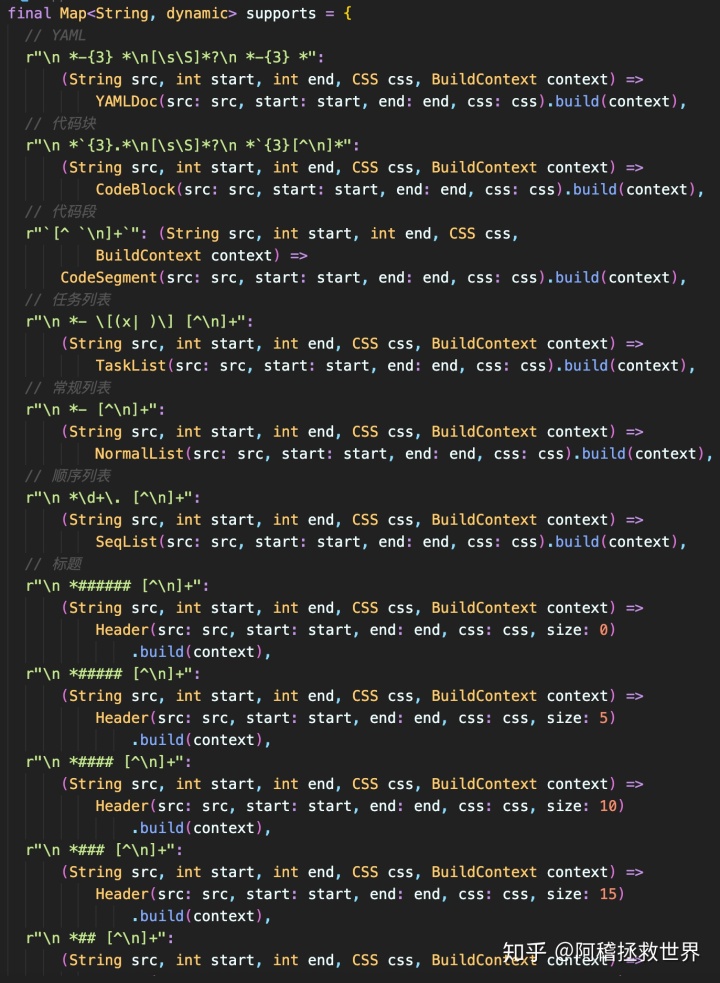
开始整活
如何实现Markdown文本直接转换成Flutter Widget?
使用正则表达式匹配对应的标记, 例如Markdown标题, 然后递归转换文本为Widget (确切来说, 是InlineSpan而不是Widget, 但是说Widget比较方便, 后面都说Widget了). 以正则表达式为例, 流程如下:
- 正则查找满足:
1) 开头是n的
2) n后可以有很多个空格;
3) 一直读取到下一个n
2. 找出"#"的后一位置, 取出内容, 递归解析成Widget
代码上的实现是这样的:
查找Markdown内"标题"的部分
// support.dart
{
r"n *###### [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 0)
.build(context),
r"n *##### [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 5)
.build(context),
r"n *#### [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 10)
.build(context),
r"n *### [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 15)
.build(context),
r"n *## [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 20)
.build(context),
r"n *# [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 25)
.build(context),
}转换成Widget的部分
// renderer.dart
class Header extends Renderer {
final String src;
final int start;
final int end;
final double size;
final CSS css;
const Header({
Key key,
@required this.src,
@required this.start,
@required this.end,
@required this.size,
@required this.css,
}) : super(src: src, start: start, end: end, css: css);
@override
InlineSpan build(BuildContext context) {
// 假设提取的字符串是: "###### H6"
// 1. 定位"#####"的位置
RegExp symbol = RegExp(r"#+");
var match = symbol.firstMatch(src.substring(start, end));
int symbolEnd = start + match.end; // 最后一个"#"的后一位
// 2. 提取关键字符串"H6"
String keyStr = src.substring(symbolEnd, end).trim();
// 3. 定义Header的叠加样式
CSS headerCSS = CSS.copyFrom(css);
headerCSS.fontSize = size + css.fontSize;
headerCSS.isBold = true;
return TextSpan(
children: [
Analyser(
text: src.substring(0, start),
css: css,
).parseTextSpan(context),
TextSpan(text: "n"),
Analyser(
text: keyStr,
css: headerCSS,
).parseTextSpan(context),
Analyser(
text: src.substring(end, src.length),
css: css,
).parseTextSpan(context),
],
);
}
}如何实现递归解析Markdown标记并转换成Widget呢?
我自己构想了一个结构, 它由一个解析器(analyser)和一个转换器(renderer)构成(抱歉, 之前因为没有仔细想两个的名字, 源码里面就直接是analyser.dart和renderer.dart了, 这里就索性这么写吧), 解析器先在support.dart, 也就是这里
// support.dart
{
r"n *###### [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 0)
.build(context),
r"n *##### [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 5)
.build(context),
r"n *#### [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 10)
.build(context),
r"n *### [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 15)
.build(context),
r"n *## [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 20)
.build(context),
r"n *# [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 25)
.build(context),
}通过遍历每一个key, 查找出符合要求的match, 并对这些match做一些无脑的排序处理(后面会说的, 请不要在意, 只是无脑的排序处理罢了), 然后对找到的最优的match进行转换, 也就是直接访问key下的value值 Header(src: src, start: start, end: end, css: css, size:0).build(context), 然后在Header内部, 由示例代码
// renderer.dart
class Header extends Renderer {
final String src;
final int start;
final int end;
final double size;
final CSS css;
const Header({
Key key,
@required this.src,
@required this.start,
@required this.end,
@required this.size,
@required this.css,
}) : super(src: src, start: start, end: end, css: css);
@override
InlineSpan build(BuildContext context) {
// 假设提取的字符串是: "###### H6"
// 1. 定位"#####"的位置
RegExp symbol = RegExp(r"#+");
var match = symbol.firstMatch(src.substring(start, end));
int symbolEnd = start + match.end; // 最后一个"#"的后一位
// 2. 提取关键字符串"H6"
String keyStr = src.substring(symbolEnd, end).trim();
// 3. 定义Header的叠加样式
CSS headerCSS = CSS.copyFrom(css);
headerCSS.fontSize = size + css.fontSize;
headerCSS.isBold = true;
return TextSpan(
children: [
Analyser(
text: src.substring(0, start),
css: css,
).parseTextSpan(context),
TextSpan(text: "n"),
Analyser(
text: keyStr,
css: headerCSS,
).parseTextSpan(context),
Analyser(
text: src.substring(end, src.length),
css: css,
).parseTextSpan(context),
],
);
}
}我们可以很直观的看出, 只是按照一定规则切出了其中的有效部分, 并把它再放入analyser中分析, 递归处理, 与此往复, 最后将整个Markdown内容转换为Widget.
这样一个流程可以画图为:
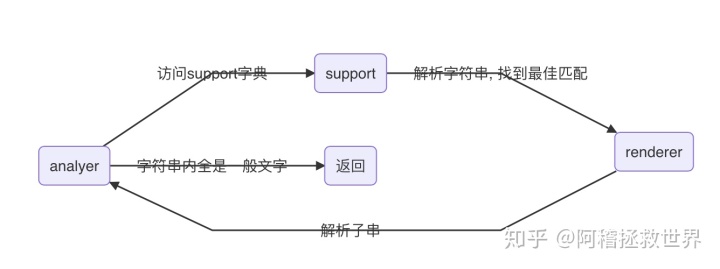
关于analyser
analyer做的事情基本上只有两件
- 遍历support的所有key并做正则查询
- 找到最前的一个Markdown的标记, 传入renderer做转换工作
核心代码如下
InlineSpan parseTextSpan(BuildContext context) {
int start = text.length;
int end = 0;
String finPtrn;
for (var pattern in supports.keys) {
RegExp regExp = RegExp(pattern);
var firstMatch = regExp.firstMatch(text);
if (firstMatch == null) continue;
if (firstMatch.start < start ||
(firstMatch.start == start && firstMatch.end > end)) {
start = firstMatch.start;
end = firstMatch.end;
finPtrn = pattern;
}
}
if (finPtrn != null) {
return supports[finPtrn](text, start, end, css, context);
}
return (inheritedWidgetBuilder != null)
? inheritedWidgetBuilder(text)
: TextSpan(
text: text,
style: css.castStyle(),
);
}只有这么几行, 只不过是对每一个match的结果做了一个比较, 找到第一个匹配到的标记, 然后交由support -> key → value(renderer) 来做转换工作, 如果最后没能匹配到任何标记, 就开始返回转换结果.
关于renderer
这个基类接收传入的待解析的字符串src, 找到的Markdown的标记起始位置start和结束位置end, 以及一个叠加样式css(这个后面会说, Flutter自己也有这样的东西, 但我还是自己写了一个, 请不必过多在意), 它通过build方法, 转换src的内容为Widget, 返还给analyser, 然后就是反复递归递归了. 总的来说, renderer就是个用来触发递归转换的类, 通过截取到的Markdown标记做进一步的字符串切割处理, 并把它们组装成一个个子Widget.
abstract class Renderer {
final String src;
final int start;
final int end;
final CSS css;
const Renderer({
Key key,
@required this.src,
@required this.start,
@required this.end,
@required this.css,
});
InlineSpan build(BuildContext context);
}关于样式的叠加问题
之所以把这个问题单独拿出来说, 是因为它并不影响到本Markdown解析器整体流程的理解, 但又在这之中起到了举足轻重的作用. 这个CSS是我自己定义的类, 它的作用顾名思义就是做样式的叠加.
在深入了解前, 我们思考一个这样的问题:
如果我们在字体加粗的外部或内部嵌套代码段标记, 那么优先解析完外层的标记以后, 要如何将这个外层的代码段标记和内层的文本加粗标记最终转换的Widget确定下来呢?

因为这样一个原因, 说实话我这个笨脑瓜子还想了好久好久, 最后我决定传入一个叫做CSS的东西进去, 它可以在每一层递归的时候不断的积累文本的样式, 当我们解析到代码段时, 就直接把css设定为代码段的样子, 然后再把这个css传入子组件内, 子组件拿到之前的css, 再在它的基础上叠加新的样式, 就类似于这样
// 定义Header的叠加样式
CSS headerCSS = CSS.copyFrom(css);
headerCSS.fontSize = size + css.fontSize;
headerCSS.isBold = true;
// code...
Analyser(
text: keyStr,
css: headerCSS, // 看这里
).parseTextSpan(context),插件可拓展性的研究
这个轮子制作的一大核心目的就是实现高度的可拓展性, 而我也为此做出了很多的尝试, 最后确定了support.dart. 这个文件里面写着的就是正则表达式以及每个正则表达式下转换为Widget的方法. 通过这样的设计可以使Markdown的解析器得到高度拓展. 目前的support如下:
import 'dart:io';
import 'package:flutter/material.dart';
import './css.dart';
import './renderer.dart';
/// 解析支持表, 支持渐进式开发. 当需要渲染新的Markdown标记时, 只需要实现基于Renderer的渲染类即可
final Map<String, dynamic> supports = {
// YAML
r"n *-{3} *n[sS]*?n *-{3} *":
(String src, int start, int end, CSS css, BuildContext context) =>
YAMLDoc(src: src, start: start, end: end, css: css).build(context),
// 代码块
r"n *`{3}.*n[sS]*?n *`{3}[^n]*":
(String src, int start, int end, CSS css, BuildContext context) =>
CodeBlock(src: src, start: start, end: end, css: css).build(context),
// 代码段
r"`[^ `n]+`": (String src, int start, int end, CSS css,
BuildContext context) =>
CodeSegment(src: src, start: start, end: end, css: css).build(context),
// 任务列表
r"n *- [(x| )] [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
TaskList(src: src, start: start, end: end, css: css).build(context),
// 常规列表
r"n *- [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
NormalList(src: src, start: start, end: end, css: css).build(context),
// 顺序列表
r"n *d+. [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
SeqList(src: src, start: start, end: end, css: css).build(context),
// 标题
r"n *###### [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 0)
.build(context),
r"n *##### [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 5)
.build(context),
r"n *#### [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 10)
.build(context),
r"n *### [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 15)
.build(context),
r"n *## [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 20)
.build(context),
r"n *# [^n]+":
(String src, int start, int end, CSS css, BuildContext context) =>
Header(src: src, start: start, end: end, css: css, size: 25)
.build(context),
// 粗斜体
r"*{3}[^n*]+*{3}": (String src, int start, int end, CSS css,
BuildContext context) =>
BoldItalicText(src: src, start: start, end: end, css: css).build(context),
// 粗体
r"*{2}[^n*]+*{2}":
(String src, int start, int end, CSS css, BuildContext context) =>
BoldText(src: src, start: start, end: end, css: css).build(context),
// 斜体
r"*[^n*]+*":
(String src, int start, int end, CSS css, BuildContext context) =>
ItalicText(src: src, start: start, end: end, css: css).build(context),
// 删除线
r"~{2}[^n~]+~{2}":
(String src, int start, int end, CSS css, BuildContext context) =>
DelLine(src: src, start: start, end: end, css: css).build(context),
// 文字高亮
r"={2}[^n=]+={2}": (String src, int start, int end, CSS css,
BuildContext context) =>
HighlightText(src: src, start: start, end: end, css: css).build(context),
// 文字样式
r"<font[^n>]*>.+</font>":
(String src, int start, int end, CSS css, BuildContext context) =>
StyledText(src: src, start: start, end: end, css: css).build(context),
// 文字样式
r"<br */>":
(String src, int start, int end, CSS css, BuildContext context) =>
BreakRow(src: src, start: start, end: end, css: css).build(context),
// 图片
r"![[^n[]]*](.+)":
(String src, int start, int end, CSS css, BuildContext context) =>
MDImage(src: src, start: start, end: end, css: css).build(context),
// 链接
r"[[^n[]]*](.+)":
(String src, int start, int end, CSS css, BuildContext context) =>
Link(src: src, start: start, end: end, css: css).build(context),
// 分割线
r"n *-{4,} *":
(String src, int start, int end, CSS css, BuildContext context) =>
MDDivider(src: src, start: start, end: end, css: css).build(context),
};
支持的解析规则还不是很多, 但是我也在慢慢晚上, 基本上这些在Typora里面是非常常用的, 我都已经做好了.
support的可拓展性非常强. 当你需要添加新的解析规则的时候, 你只需要写入一个键值对, key是匹配这个Markdown标记的正则表达式, 值是转换这个标记为Widget的对应类. 这个类里面的基础设施都是建设好的, 你只需要按照上述的转换流程, 照葫芦画瓢画上递归的转换方法, 一个新的Markdown解析规则就完成了; 如果你觉得哪个规则没有必要, 则直接删掉那个规则对应的键值对和实现类就好了, 我个人觉得非常方便, 完全不会影响其他解析规则的执行.
事后
刚开始说实话, 我完全不知道这个东西要怎么下手, 我太笨了. 我在网上查找了很多的办法, 但那些都是现成的轮子, 而奈何本人并不对HTML和JS抱有十分的好感. 虽然我尝试过直接通过Webview加载本地html模板, 在模板内引入markedjs等轮子, 试图直接通过他们完成Markdown的显示. 先说结果, 单显示是十分成功的, 但是涉及到交互层面, 大家都懂的, 毕竟套的Webview, 直接在页面内跳转了, 场面一度十分尴尬. 当然确实是可以通过增加Webview的一些点击事件的方式来尝试这一问题, 但我觉得: 既然成本都一样高, 那么直接写一个新的轮子它不香吗? 只要能超越之前那些轮子的一切, 那就是舒服的. 于是我开始了尝试, 并且得到了一定程度上的成功. 虽然目前这个插件还不是十分完善, 但基础的转换已经十分稳定, 我现在自己的Flutter工程里面都是用的自己写的这个轮子, 它的名字叫做refined_markdown, 在Dart packages上面查得到的, 源码也在Github上面. 如果您对它有兴趣, 不妨给个Start, 有任何问题也随时Issue搞上来, 在我的可用时间内我一定尽快解决问题.
我设计了很多个提高拓展性的方案, 最终找到了这个相对来说最好的, 也是希望这个插件能在大家的共同努力下做得更好. 现在"不造重复轮子"的说法在卑微渺小的我看来有点可笑, 我觉得不管是谁来做这个东西, 确实是应该要竞争起来, 要做就是要做到最好, 没有竞争就不可能有更好的产品产生, 只会让一家独大变成一种奇妙的垄断, 最终大家都会止步不前, 你我应该深知这个道理.
话已至此, 感谢您耐心看完~















 987
987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









