







摘要
在云存储应用中,由于经济成本与系统性能的要求,分布式存储技术广泛采用多数据副本的策略。这种冗余存储模式可以确保,只有部署在磁盘上数据的所有副本都损坏时,才会发生数据丢失。在这种情况下,数据的持久性取决于故障恢复模型和副本组织策略。然而,当相关故障发生时,传统的方法在防止数据丢失方面的效果并不佳。在本文中,我们提出了一种针对云存储服务的数据持久性的建模和分析方法。首先,我们使用一个非可回退的马尔可夫链来对数据损坏和恢复的过程建模。此外,我们介绍了一种基于路由表的副本组织策略,以减少相关故障造成的数据丢失。最后,通过在仿真环境中进行的一系列定量评价,验证了提出的方法的有效性。
1. 引言
随着信息通信技术的发展,数据持续增加,对存储的要求越来越高,可能是结构化的文档,也可能是非结构化的图片和视频。因此,海量数据的存储和访问是云服务领域研究的热点。传统的方式是人们使用更大容量的硬盘来存储大量数据,这样不仅会产生额外的硬件资源成本,而且会限制数据访问的移动性。然而,随着云存储技术的发展,用户可以将自己的数据上传到云上,并将数据的管理交付给云服务提供商,这样,用户无需携带庞大的存储设备就可以随时随地访问自己的数据。虽然云存储技术使用户更方便地管理数据,但是数据的持久性一直是用户关注的焦点,这也是云服务提供商评估服务水平的一个重要依据。
虽然已经有一些传统方法对数据持久性进行建模和分析,但仍有一些挑战有待解决。首先,马尔可夫链通常用于对冗余云存储架构的故障和恢复过程建模。然而,一些方法中的最后的状态是可回退的,这并不适用于当所有副本都损坏时(此时数据已经丢失并且无法恢复)的情况。此外,传统的随机的副本组织策略在发生相关故障(如停电、网络拥塞、地震等)时,并不能有效地防止数据丢失。最后,在特定的情况下,分布式存储系统的数据持久性是有一个极值的。然而,现有的方法大多基于定性分析,缺乏定量计算,并不能给出最优的集群规模,以确保最大的数据持久性。
主要内容包括以下几点。
- 基于数据失效和恢复的过程,提出了一种数据持久性建模方法,即非可回退的马尔可夫链。
- 设计一种基于路由表的数据副本组织策略,以降低相关故障导致数据丢失的概率。
- 通过一系列实验对我们提出的方法进行了定量评估,并讨论了确保最大持久性的最优集群规模。
2. 可用性与持久性
大多数人对于数据持久性的概念是模糊的,通常包含了持久性(durability)和可用性(availability)两重含义。可用性,即系统服务不中断运行时间占实际运行时间的比例。所以,可用性其实是一个百分比,如99.9%。我们通常会听说一个词:高可用,其实指的就是高可用性。高可用指的就是系统服务不中断运行时间占实际运行时间的占比更大。
要了解可用性,躲不开的三个体现系统可用性的重要指标:MTTR、MTTF、MTBF
- MTTF 即 Mean Time To Failure,平均无故障时间。指系统无故障运行的平均时间,取所有从系统开始正常运行到发生故障之间的时间段的平均值。
- MTTR 即 Mean Time To Repair,平均修复时间,指系统从发生故障到维修结束之间的时间段的平均值。
- MTBF 即 Mean Time Between Failure,平均失效间隔,指系统两次故障发生时间之间的时间段的平均值。
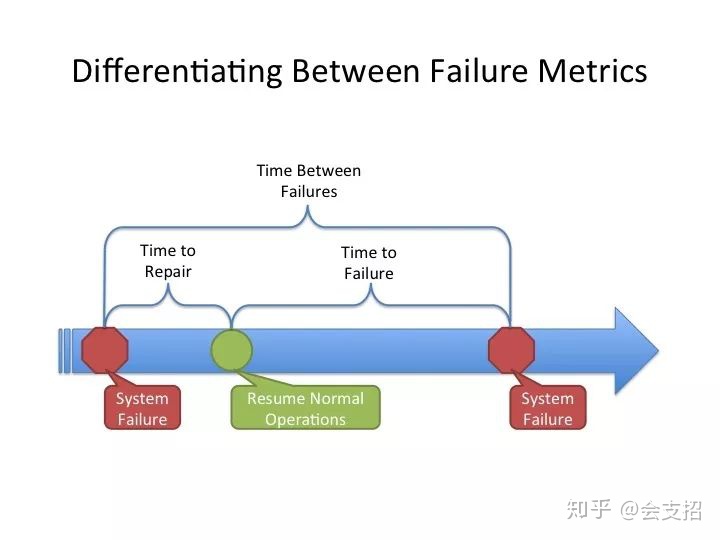
上图展示了三者之间的关系:
系统的可用性指的其实就是:
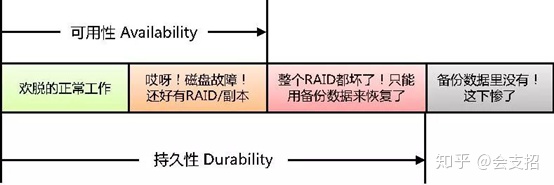
实际上,我们把数据的可访问性称为可用性。数据暂时不可访问并且在一段时间后可以找到时,这种状态称为不可用,但数据仍然是持久的。只有数据完全丢失,永远也找不到,才会涉及数据的持久性。可见,持久性比可用性更基础,前者是后者的必要非充分条件,从数值描述上,持久性
3. 故障率
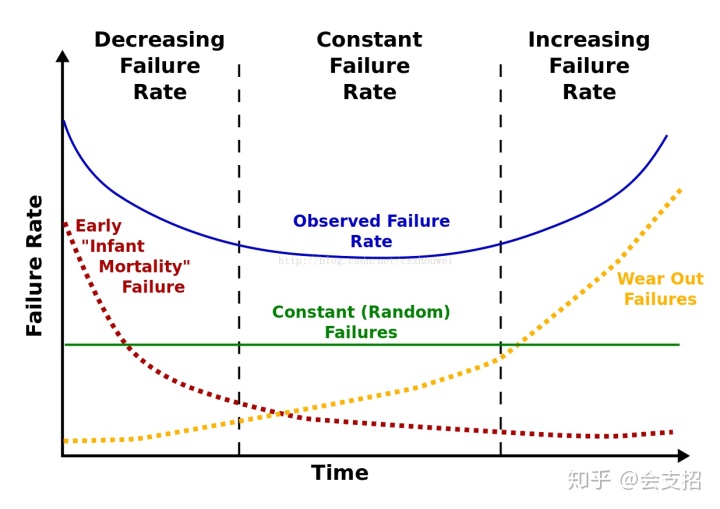
实践证明大多数设备的故障率是时间的函数,典型故障曲线称之为浴盆曲线(Bathtub curve,故障率曲线) 。浴盆曲线是指产品从投入到报废为止的整个寿命周期内,其故障率的变化呈现一定的规律。曲线的形状呈两头高,中间低,有些像浴盆,所以称为“浴盆曲线”,曲线具有明显的阶段性,失效率随使用时间变化分为三个阶段:早期故障期、随机故障期和耗损故障期。
- 早期故障期(Infant Mortality):表明产品在开始使用时,故障率很高,但随着产品工作时间的增加,故障率迅速降低,这一阶段失效的原因大多是由于设计、原材料和制造过程中的缺陷造成的。为了缩短这一阶段的时间,产品应在投入运行前进行试运转,以便及早发现、修正和排除故障;或通过试验进行筛选,剔除不合格品。
- 随机故障期(Random Failures):这一阶段的特点是故障率较低,且较稳定,往往可近似看作常数,产品可靠性指标所描述的就是这个时期,这一时期是产品的良好使用阶段, 偶然失效主要原因是质量缺陷、材料弱点、环境和使用不当等因素引起。
- 耗损故障期(Wearout):该阶段的故障率随时间的延长而急速增加, 主要由磨损、疲劳、老化和耗损等原因造成。
Weibull分布可以通过调整不同参数,表征整个产品生命周期,即上述的浴盆曲线。然而,在实际的场景中,一个集群中有大量的磁盘,混合着不同“年龄段”的磁盘,集群这种混合的状态趋于稳定,集群中磁盘的平均故障率趋于恒定。当故障率稳定时,Weibull分布就与指数分布的效果相同,因此,我们假设磁盘的寿命服从指数分布,便于计算并且对于实际场景是合理的。
指数分布介绍:https://www.zhihu.com/question/24796044
泊松分布介绍:https://www.zhihu.com/question/26441147
4. 模型的作用
存储系统的持久性日益受到关注,原因如下:
- 故障不仅会导致数据暂时不可用,而且最坏的情况会导致永久性的数据丢失。
- 由于技术和市场共同作用下,使未来的大规模的存储系统中的部分的故障会更频繁发生。
- 现在,存储系统已发展到前所未有的规模,一个集群中有数千个存储设备,使得部分故障成为常态而非例外。
数据持久性是根据平均数据丢失时间(MTTDL)或一年内丢失数据的概率来量化的。由于持久性数值很大,在现实世界中测试这些系统的持久性值是一项艰巨的任务,这需要大量的测试时间和数据进行分析,使用数学模型计算数据持久性值可以解决这个问题。
- 使用模型评估系统,帮助存储系统的设计,如指导设计者选择更为可靠的组件还是在不可靠的组件上构建冗余
- 使用模型更为准确估计系统持久性,数据中心可以使用这些模型快速修改硬件和软件参数(磁盘的数量和类型、冗余模式、存储区域、网络布局和风险选择)
- 使用模型可以对设备更换和替换成本进行评估,从而帮助系统设计人员决定应使用多少资源来容忍故障并满足服务质量目标
如何考虑多方面因素准确计算系统的持久性是关键,因为数据丢失代价很大,过高估计持久性值会使系统面临数据丢失风险,而低估持久性值会增加成本。因此,如何选择一个好的模型来评估数据的持久性是一个难题。持久性模型需要兼顾以下几个方面,即并行重建、相关故障以及分片的放置策略。马尔可夫链是一个很好的建模框架,它能够将这些方面结合在一起,从而快速计算现有系统的耐久性。
其他部分:
会支招:云存储中那么多“9”的来历(二)—— 持久性的数学计算过程zhuanlan.zhihu.com















 6364
6364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









