






本文介绍一种神奇的排序方法——堆排序。
堆排序不像插入排序和归并排序那样直观,它利用了一种称为堆的数据结构。
堆
堆本质上是一个数组,但我们将其当做一个近似的完全二叉树来看待。树上的每一个结点对应数组中的一个元素,按层排列。除了最底层外,该树是完全充满的,而且是从左向右填充。
下图(a)为我们想象中堆的结构,而(b)则是其实际存储形式。
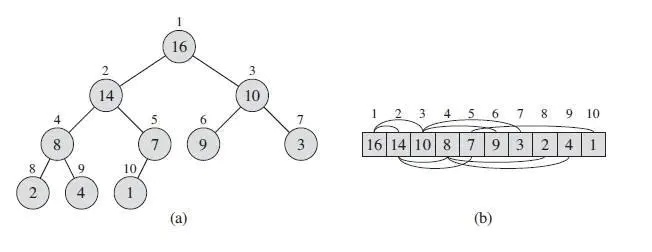
最大堆的特点是,每一个结点都比它的两个孩子结点大(如果孩子结点存在的话)。类似地,最小堆的每一个结点都比它的两个孩子结点小。但需要注意的是,大小关系只存在于根节点与其孩子结点中,兄弟结点或不同子树中的结点没有大小关系。根据这条性质,很容易发现,最大堆的根结点是所有元素的最大值,最小堆的根结点是所有元素的最小值。
无论是最大堆还是最小堆,它们的工作原理都是一样的,因此本文以最大堆为例,因为使用最大堆排序得到的恰好是递增序列。
堆具有两个重要操作——建堆和维护堆。
维护堆
先来介绍维护堆,这是堆最基本的操作。当一个根节点的左子树和右子树都是最大堆,而根结点对应的树却不是最大堆时,说明根结点小于其左孩子或右孩子。此时,我们需要令根结点“逐级下降”,与其某个孩子结点交换位置,使整个树重新满足最大堆的性质。
维护堆的过程如下图所示。
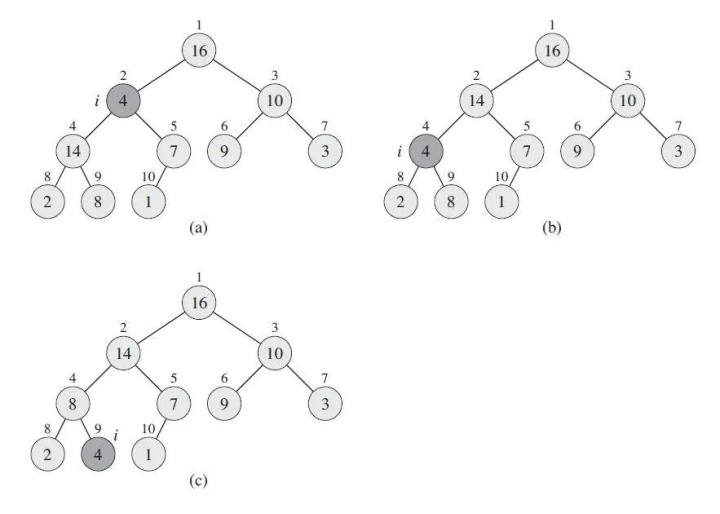
图中,我们要维护结点2对应的堆。由图(a)可以看到,其左子树符合最大堆的性质,其右子树也符合最大堆的性质,但其本身却小于左孩子和右孩子。此时,我们要从结点2、结点4和结点5中选择最大的结点,将其与结点2交换位置,从而得到图(b)所示的状态。接下来,结点4又不满足最大堆的性质了,再将其与结点8和结点9比较大小,从而交换结点4与结点9,得到图(c)的状态。此时,结点9已经成为叶子结点,维护堆的操作结束。
建堆
建堆将一个无序的数组建立成满足堆性质的数组,建堆的过程如下图所示。
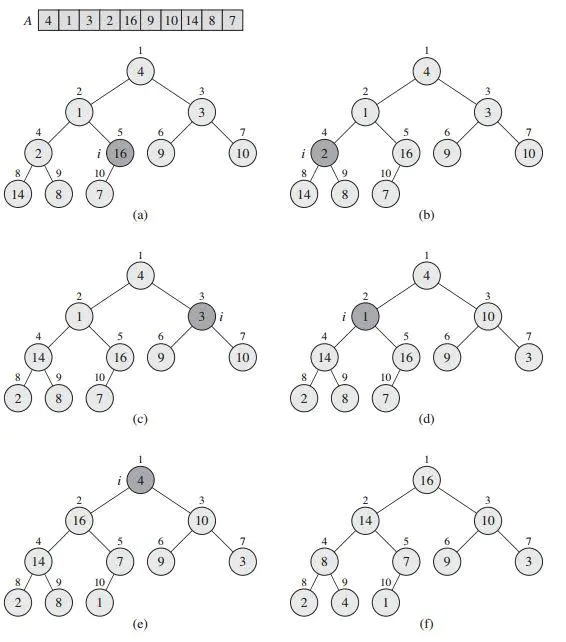
首先,给定无序数组A。先将其按从上到下、从左到右的顺序建立二叉树,如图(a)所示。然后从后向前找到第一个不是叶子结点的结点,对该结点执行维护堆操作,完成后该结点对应的子树就满足了堆的性质。继续向前遍历所有的结点,重复维护堆操作,直到根结点对应的堆(即完整的堆)满足堆的性质。
堆排序
现在我们可以考虑如何使用堆实现一个排序算法。由于最大堆的根结点保存了数组的最大值,因此可以每次将根结点的值从数组中取出,再令剩下的元素重新形成堆,如此往复,就可以依次从大到小取出数组中的所有元素。
下图所示为堆排序的完整流程。
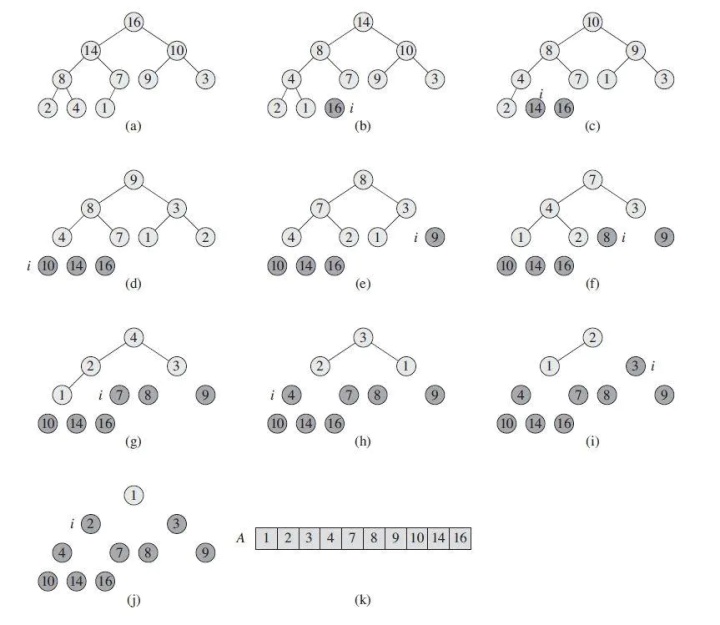
图(a)为建堆后的结果。从(a)到(b)的具体过程为,取出根结点16放到末尾,然后把最后一个叶子结点1放到根结点的位置(注意此时堆的元素少了一个),执行一次“维护堆”操作,结果就成了图(b)所示的样子。不断重复这个过程,直到所有结点都离开了堆,堆排序算法就结束了。结果是一个从小到大的数组。
堆排序是原址排序,不需要额外的内存空间,因为堆中元素只存在交换位置的操作,数组在原有地址里排序。
性能分析
堆排序应用了一次建堆操作和
维护堆的时间复杂度很容易分析,对于元素个数为
建堆操作内部调用了
其中,第三行做了一次放缩,将有限级数求和扩大到无限级数求和,而后者的极限为常数2。于是,我们得到建堆操作更紧确的渐进时间复杂度
最后,堆排序的时间复杂度为
实现代码
具体实现时,需要先实现堆数据结构,然后利用该数据结构实现堆排序。实现原理本文已经解释清楚,因此不再赘述,代码位于Heap.java和HeapSort.java。
堆的应用
堆除了用于排序之外,还有其它众多用途。
最常见的用途莫过于优先队列。将普通队列建堆,即可得到一个优先队列,最大堆对应着最大优先队列,最小堆对应着最小优先队列。当用户需要从优先队列中取出一个元素时,直接返回堆顶元素,然后将堆的末尾元素补充到堆顶,并执行一次维护堆操作。当用户需要向优先队列插入数据时,直接将该元素置于堆的末尾,然后做一次“逐级上升”的维护堆操作。这样保证了在插入或取出数据时堆的性质都得以保留。
优先队列具有很多实际用途,比如从海量数据中搜索top k、作业调度器、合并有序序列、查找中位数等等,这里就不一一介绍了,感兴趣的同学可以自行查找相关资料。
参考资料
堆的应用 MakeSail















 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









