





享学课堂特邀作者:周周
转载请声明出处!
接上文:
4. 连接拦截器 ConnectInterceptor
顾名思义:它自然是管理网络连接的。如何管理?
我们都知道,HTTP协议的底层,还是要走TCP,他们分属于 TCP/IP四层架构的应用层和传输层。传输层会三次握手,Socket建立成功之后,就会开启IO流传输数据。那么是不是每一次我们的网络请求都需要重新取三次握手建立新的Socket连接?显然不用。如果已经就有了现成的闲置连接,没有必要去建立新的Socket连接. 而这些连接的管理逻辑,就在这个ConnectionInterceptor中.
这个类相当简洁:

上面的关键点:
就是这个叫做 StreamAllocation (顾名思义,流的分配者,是用来管理数据流通道的)的类,如果进入它的源码,就会发现,它管理着一个连接池,
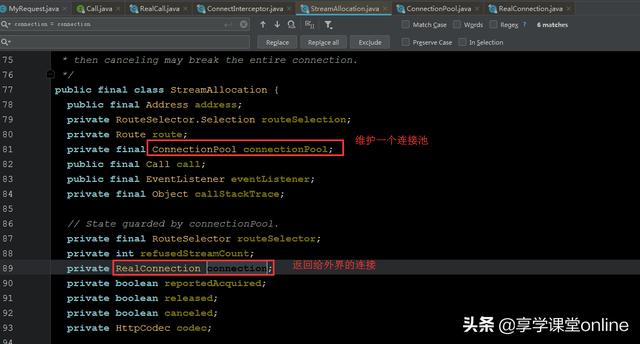
那么,它是如何管理所有连接的呢?核心逻辑在哪里?
我们跟踪,RealConnection connection = streamAllocation.connection(); 这一句代码:
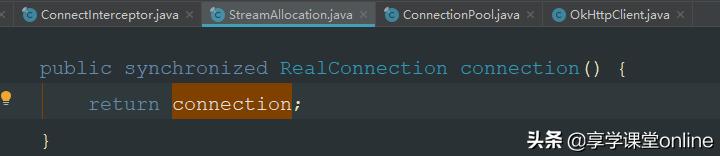
这一个connection变量的赋值,在这里
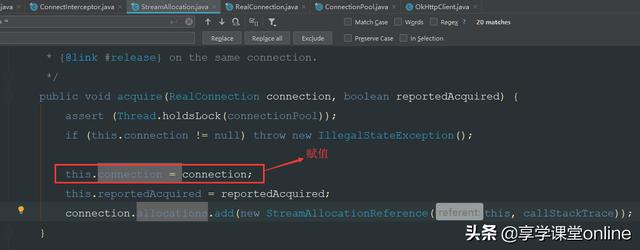
从而找到 ConnectionPool 的 get方法:
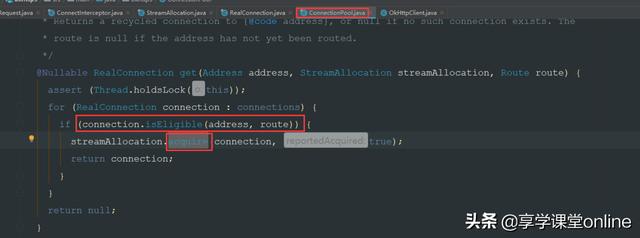
此处有一个isEligible方法,它的作用是 遍历连接池的双端队列(观察connections的类型,它是一个Deque)中是否有合格的 连接可用。
/** * Returns true if this connection can carry a stream allocation to {@code address}. If non-null * {@code route} is the resolved route for a connection. */ public boolean isEligible(Address address, @Nullable Route route) { // If this connection is not accepting new streams, we're done. if (allocations.size() >= allocationLimit || noNewStreams) return false; // If the non-host fields of the address don't overlap, we're done. if (!Internal.instance.equalsNonHost(this.route.address(), address)) return false; // If the host exactly matches, we're done: this connection can carry the address. if (address.url().host().equals(this.route().address().url().host())) { return true; // This connection is a perfect match. } // At this point we don't have a hostname match. But we still be able to carry the request if // our connection coalescing requirements are met. See also: // https://hpbn.co/optimizing-application-delivery/#eliminate-domain-sharding // https://daniel.haxx.se/blog/2016/08/18/http2-connection-coalescing/ // 1. This connection must be HTTP/2. if (http2Connection == null) return false; // 2. The routes must share an IP address. This requires us to have a DNS address for both // hosts, which only happens after route planning. We can't coalesce connections that use a // proxy, since proxies don't tell us the origin server's IP address. if (route == null) return false; if (route.proxy().type() != Proxy.Type.DIRECT) return false; if (this.route.proxy().type() != Proxy.Type.DIRECT) return false; if (!this.route.socketAddress().equals(route.socketAddress())) return false; // 3. This connection's server certificate's must cover the new host. if (route.address().hostnameVerifier() != OkHostnameVerifier.INSTANCE) return false; if (!supportsUrl(address.url())) return false; // 4. Certificate pinning must match the host. try { address.certificatePinner().check(address.url().host(), handshake().peerCertificates()); } catch (SSLPeerUnverifiedException e) { return false; } return true; // The caller's address can be carried by this connection. }解读一下这段代码:
- 返回值: 如果这个连接可以给这个访问地址一个流,那么返回true。(可见,判断连接是否可用,会考虑当前访问的ip地址是否匹配,很好理解,如果访问的ip都不一样,我凭什么把现成的连接给你复用。)
然后是众多if判断(这里存在一个当前连接与目标地址的参数值对比),总结起来:
- 连接到达最大并发流或者连接不允许建立新的流,那就不允许复用;
- 如果地址的非host字段没有完全相同,也不允许复用。(解释一下,一个Address对象包含了host字段和其他字段,这里的非host字段,就是指的这个类中的其他字段)
- 如果到了这里,那就判断host是不是相同,如果相同,那就允许复用。
- 如果上面的3步判断都没有命中,那么,我们依然有机会去复用,只要不命中下面的判断。
- 1)HTTP2连接为空,不允许复用
- 2)使用了代理,并且代理的类型不是直接代理 或者 ,不允许复用
- 3)此连接的服务器证书必须覆盖新主机,否则也不能复用
- 4)证书固定必须与主机匹配,否则,也不能复用
- 上面的4个if都没有命中,那么还是判定为可以复用。
总结:如果在连接池中找到个连接参数一致并且未被关闭没被占用的连接,则可以复用旧连接,无需新建连接。
5. 服务调用拦截器 CallServerInterceptor
经历了 上面4个拦截器,我们最终拿到了 request,connection,有了请求,有了连接,那么就可以向服务器发起网络请求了。这一步,就包含执行网络请求的具体逻辑。
注意:我们这里的request,它是一个java对象,但是底层用的TCP协议,发送的是报文(在http1.X下,报文全都是明文字符串格式拼接,那么你一个request对象中包含的内容如何去拼接成一个 报文字符串呢?)
反过来想,我们TCP底层从服务器取得的也最先是 响应报文,他也是一大串字符串,那么如何封装成java需要的Response对象呢?逻辑也在这里。具体在哪个类?
HttpCodeC.java
在这里我关心两个问题:
1)真正与底层发生socket网络通信是如何进行的?
2)httpCodeC是如何解析request成请求报文,又是如何将相应报文变成Response的?
来探索,首先进入到CallServerInterceptor的Interceptor方法,这是核心入口:
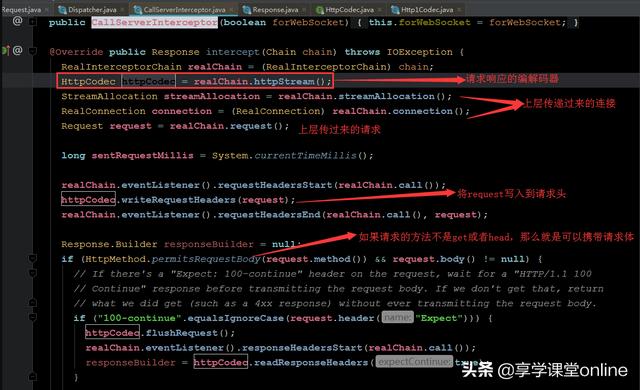
首先回顾一下TCP socket通信的过程:
1)建立Socket连接
2)打开IO流通道(socket是双工通讯协议,可以同时调用输入和输出流)
3)在这个案例中,移动端作为客户端需要往IO流通道中去写数据,然而我们知道,OutputStream,当我们写了数据之后,必须调用flush,刷新缓存区,才能将数据发送过去。
这里,我们就能得出上面一个问题的答案:
Q:真正与底层发生socket网络通信是如何进行的?
A:OkHttp使用了 OkIo来发送数据给远端,在这个Intercept 方法中,我们可以找到两句代码:httpCodec.flushRequest(); 和 httpCodec.finishRequest(); 如果你进去看实现,会发现,
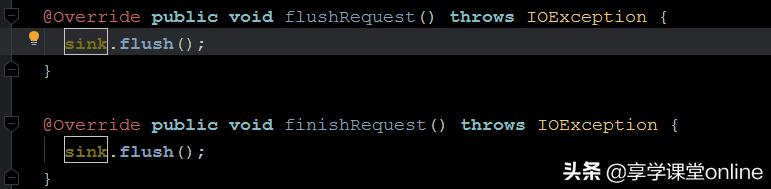
他们执行的是同一个flush过程,将缓存去数据发送给远端。(至于更细节的,比如 sink.flush是如何实现的,我就不去探索了,有兴趣的可以继续深入)
下面来探究问题2:
Q: httpCodeC是如何解析request成请求报文,又是如何将相应报文变成Response的?
继续在Intercept方法中寻找,发现:
httpCodec.writeRequestHeaders(request); //写入请求头httpCodec.createRequestBody(request, contentLength) //构建请求体深入可以发现,这两个方法其实都是接口方法,他们的具体实现分为了http1 和http2 ,两者实现并不相同,我们只看http1的:
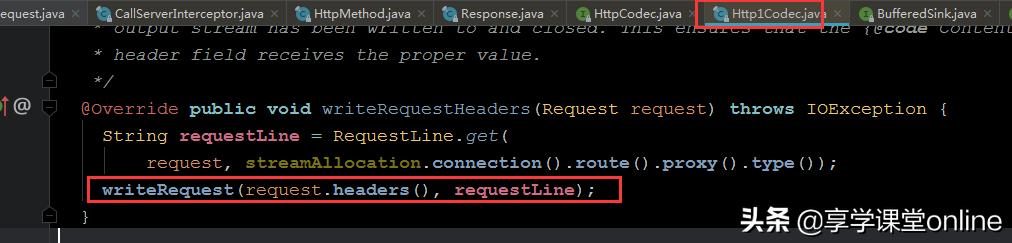
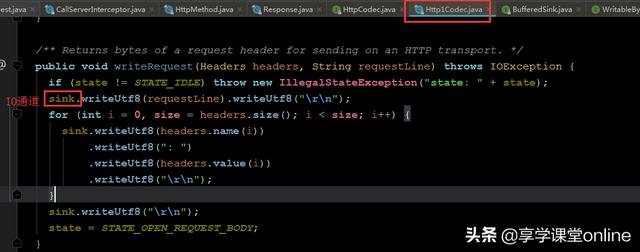
看到了吧,这里其实就是在利用 io通道 sink来写入字符串而已。至此,request变成字符串报文已经有答案了。
那么,报文如何变成response对象呢?
响应,分为响应头和响应体,先看响应头:
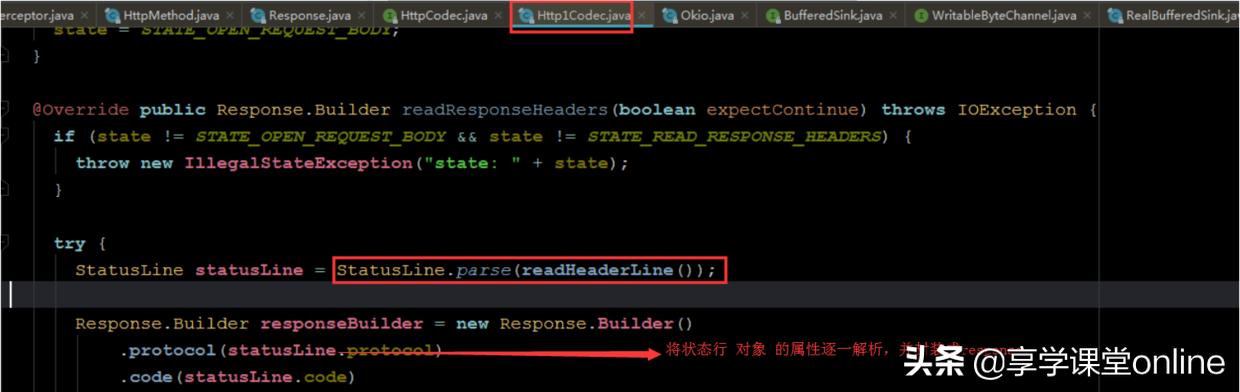
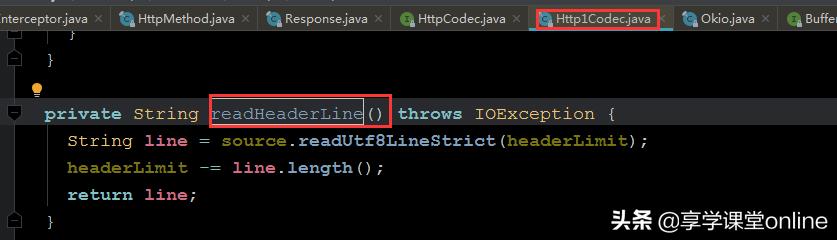
可以看出,响应头,是利用通道中读取出来的响应行,解析成StatusLine对象,然后将StatusLine对象的属性逐一读取,构建一个Response对象。
那么响应体呢?
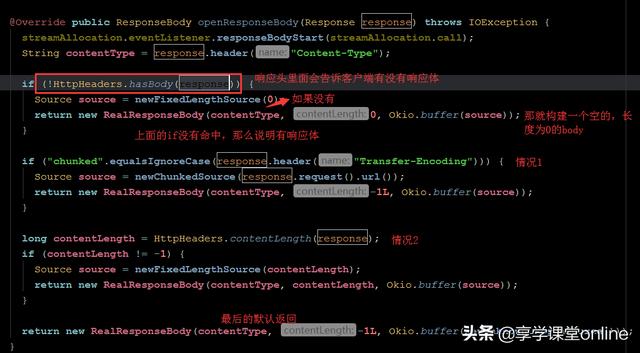
上图中,利用了OkIo来缓存source通道中的数据,构建一个RequestBody对象。现在有了ResponseHeader 和ResponseBody,就能组成一个完整的Response对象。
最后的结论:
CallServerInterceptor拦截器 就是真正向远端socket发送数据以及 接收远端socket数据的一层,利用OkIO作为数据通道。 HTTP1中以字符串拼接的方式,解析Request数据然后发送 / 解析响应报文并封装成Response对象.
结语
OkHttp作为知名第三方开源框架的佼佼者,其中值得探索学习的细节非常至多。但是我们学习框架,探索源码,一定要有自己的明确的目标。网上介绍okhttp的文章很多,每个人的侧重点都不一样,但是 okhttp的大思想都是一样,比如:分发器/拦截器,分发器的三个双端队列的作用,5大系统拦截器的职责,责任链模式设计思路。
一定有人会说,上面文章的这么多细节,我是可以根据你的文章看一遍,走一遍,能够在脑子里留个印象,但是过两天又忘了,怎么办?
大可不必担忧,自己走过一遍的路,想要走第二遍,手到擒来,但是如果是完全没有走过的路,就是完全的陌生区域,会发生什么事,你完全把控不了。
程序员修炼路遥遥,深入学习过源码,和完全没看过源码,是截然不同的两个境界。
(PS:缓存拦截器的具体细节,后面有时间会出文章补上!)
你的赞和关注是我继续创作的动力~















 7818
7818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









