






 本文介绍了如何在R语言中使用tableone包快速绘制临床研究中的基线特征表,包括单组和多组汇总,处理分类和连续变量,指定非正态分布变量,进行统计检验,并添加overall列。内容涵盖了从数据准备到输出表格的全过程。
本文介绍了如何在R语言中使用tableone包快速绘制临床研究中的基线特征表,包括单组和多组汇总,处理分类和连续变量,指定非正态分布变量,进行统计检验,并添加overall列。内容涵盖了从数据准备到输出表格的全过程。
临床研究中常需要绘制两组或多组患者(如非AKI组和AKI组)的基线特征表。
下图就是临床中常见的基线特征表,从下图我们可以看出,第1列为两组患者需要比较的变量;第2列为所有患者的基线特征,这一列在论文中可有可不有;第3列和第4列分别为非AKI组和AKI组的基线特征;第5列比较两组基线特征有没有统计学差异。
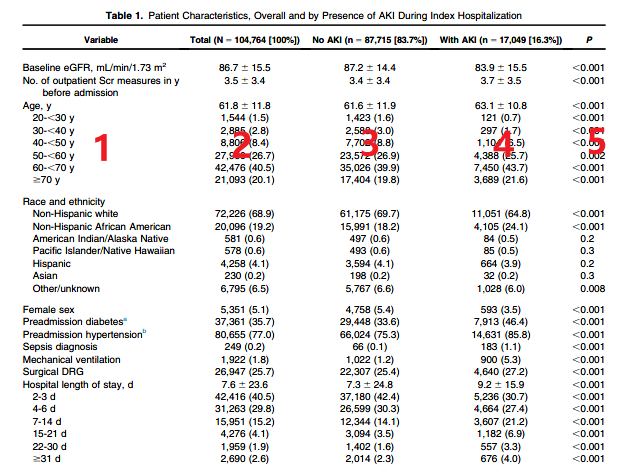
在上图中,分类变量表示为计数(百分比),连续变量若呈正态分布表示为均值±标准差,呈非正态分布表示为中位数和四分位数。
那么在R中怎么快速绘制绘制临床论文中的基线特征表1?
可以使用tableone包来绘制。
目 录
1. 绘制基线表前的准备
2. 单组汇总数据
3. 分类变量处理
4. 优化单组汇总
5. 显示基线表所有数据信息
6. 指定非正态分布变量
7. 多组汇总数据
8. 统计检验
9. 添加overall列
10. 输出基线特征表
11. 后续
12. CreateTableOne()函数
End
1. 绘制基线表前的准备
安装需要用到的R包
install.packages("tableone") # 安装tableone包,绘制基线表需要
install.packages("survival") # 安装需要内置数据集的包
加载数据集和包
library(tableone) # 加载包
library(survival) # 加载包,需要使用survival包的colon数据
data(colon) # 加载数据集
View(colon) # 预览数据集
本次用来演示的数据集为survival包的colon数据,数据集介绍查看《常用内置数据集介绍》这篇文章。
2. 单组汇总数据
CreateTableOne(data = colon) # 汇总整个数据集特征
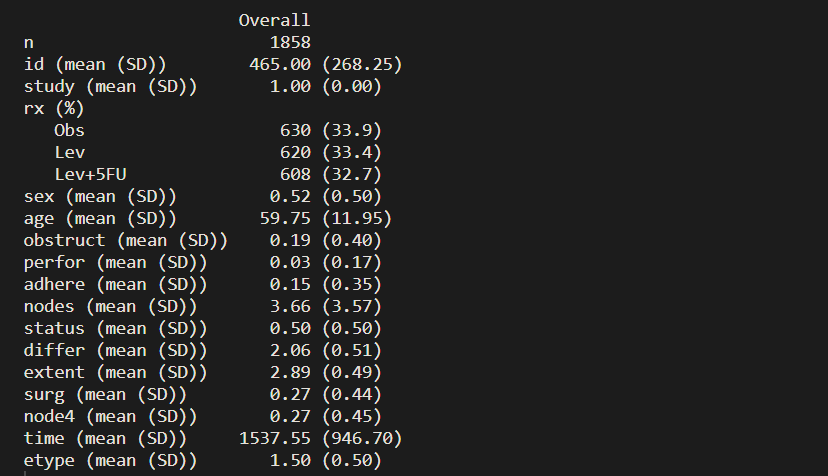
从上面可以看出,colon数据集中共有1858例患者,但由于没有将分类变量转化为因子,所以分类变量显示的也是均值+标准差。
3. 分类变量处理
在数据处理中,大多数分类变量是采用数字编码,二分类变量常表示为0和1,多分类变量表示为0、1和2等。
有两种方法可以将分类变量转化为因子:一是先在数据集中将分类变量转化为因子,然后再使用tableone包进行汇总,二是在tableone包中直接指定哪些变量属于因子(使用factorVars参数进行转换),然后在进行汇总。
dput(names(colon)) # 输出colon数据集变量名称
输出变量名称:
c("id", "study", "rx", "sex", "age",
"obstruct", "perfor", "adhere",
"nodes", "status", "differ", "extent",
"surg", "node4", "time", "etype")
从数据集介绍中,我们知道 "rx"、"sex"、"obstruct"、"perfor"、"adhere"
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









