






关注公众号:登峰大数据,阅读Spark实战第二版(完整中文版),系统学习Spark3.0大数据框架!如果您觉得作者翻译的内容有帮助,请分享给更多人。您的分享,是作者翻译的动力!
您可以重用为接入和转换而编写的大部分代码。但是,要执行union,必须确保模式完全相同。否则,Spark将不能执行union。
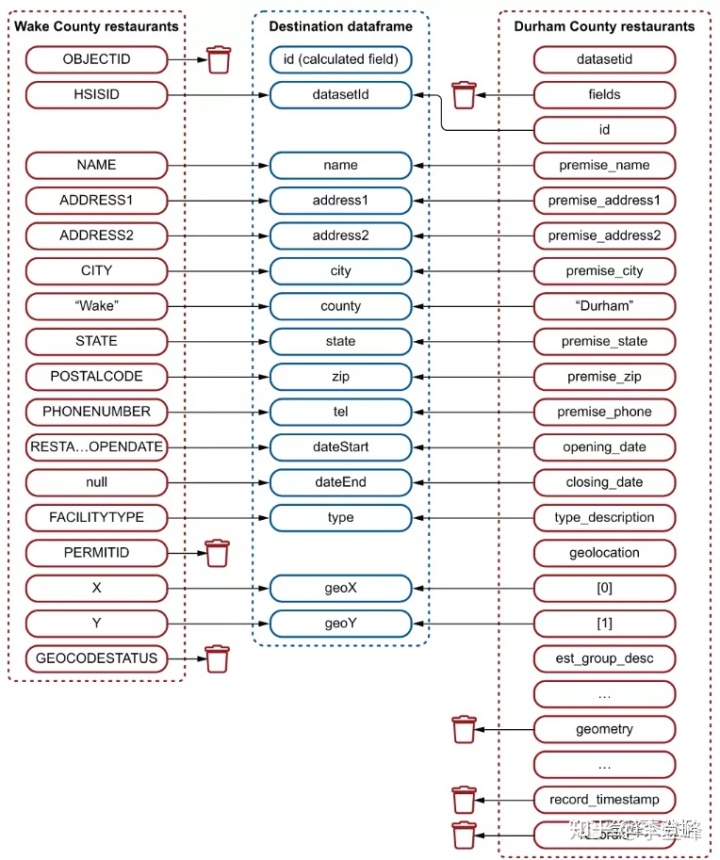
图3.16说明了将要进行的映射。
应用程序的最终输出如下(图3.17显示了一个完整的屏幕截图):
+-----------+--------------------+--------------------+--------+...
| datasetId| name| address1|address2|...
+-----------+--------------------+--------------------+--------+...
|04092016024| WABA|2502 1/2 HILLSBOR...| null|...
...
only showing top 5 rows
图3.17对应的模式如下:
root
|-- datasetId: string (nullable = true)
|-- name: string (nullable = true)
|-- address1: string (nullable = true)
|-- address2: string (nullable = true)
|-- city: string (nullable = true)
|-- state: string (nullable = true)
|-- zip: string (nullable = true)
|-- tel: string (nullable = true)
|-- dateStart: string (nullable = true)
|-- type: string (nullable = true)
|-- geoX: string (nullable = true)
|-- geoY: string (nullable = true)
|-- county: string (nullable = false)
|-- dateEnd: string (nullable = true)
|-- id: string (nullable = true)
We have 5903 records.
Partition count: 1让我们浏览一下代码。导入的类是一样的。为了简化这个过程,SparkSession的实例是一个私有成员,在start()方法中进行了初始化。剩下的代码使用三个封装的方法进行处理:
- buildWakeRestaurantsDataframe()构建包含维克县餐馆的dataframe。
- buildDurhamRestaurantsDataframe()构建包含Durham县餐馆的dataframe。
- combineDataframes()通过使用一个类似sql的union来组合这两个dataframe。现在,不要担心生成的dataframe的内存使用情况。在第4章中,你会看到dataframe是自优化的。
让我们来分析代码:
package 这部分代码很简单,对吧?让我们分析这些方法,从buildWakeRestaurantsDataframe()开始,它从CSV文件中读取数据集。这对你来说应该很熟悉,就像你之前在3.2.1节看到的那样:
private 现在准备处理第二个数据集:
private Dataset<Row> buildDurhamRestaurantsDataframe() {
Dataset<Row> df = this . spark .read().format( "json" )
.load( "data/Restaurants_in_Durham_County_NC.json" );
df = df .withColumn( "county" , lit ( "Durham" ))
.withColumn( "datasetId" , df .col( "fields.id" ))
.withColumn( "name" , df .col( "fields.premise_name" ))
.withColumn( "address1" , df .col( "fields.premise_address1" ))
.withColumn( "address2" , df .col( "fields.premise_address2" ))
.withColumn( "city" , df .col( "fields.premise_city" ))
.withColumn( "state" , df .col( "fields.premise_state" ))
.withColumn( "zip" , df .col( "fields.premise_zip" ))
.withColumn( "tel" , df .col( "fields.premise_phone" ))
.withColumn( "dateStart" , df .col( "fields.opening_date" ))
.withColumn( "dateEnd" , df .col( "fields.closing_date" ))
.withColumn( "type" ,
split ( df .col( "fields.type_description" ), " - " ).getItem(1))
.withColumn( "geoX" , df .col( "fields.geolocation" ).getItem(0))
.withColumn( "geoY" , df .col( "fields.geolocation" ).getItem(1))
.drop( df .col( "fields" ))
.drop( df .col( "geometry" ))
.drop( df .col( "record_timestamp" ))
.drop( df .col( "recordid" ));
df = df .withColumn( "id" ,
concat ( df .col( "state" ), lit ( "_" ),
df .col( "county" ), lit ( "_" ),
df .col( "datasetId" )));
return df ;
}注意,当删除父列时,所有嵌套列也会被删除。因此,当您删除fields列时,所有子字段(如risk , seats , sewage等)将同时删除。
您现在有两个具有相同列数的dataframes。因此,您可以在combineDataframes()方法中union它们。在一个类似sql的union中组合两个dataframes有两种方法:您可以使用union()或unionByName()方法。
union()方法不关心列的名称,只关心它们的顺序。这个方法总是将第一个dataframe中的第1列与第二个dataframe中的第1列联合起来,然后移动到第2列和第3列——不管名称是什么。在进行了几次转换操作(其中创建新列、重命名列、转储列或合并列)之后,可能很难记住列的顺序是否正确。如果字段不匹配,最坏情况下可能是数据不一致,或者程序停止。另一方面,unionByName()按名称匹配列,这样更安全。
这两种方法都要求数据集两边的列数相同。下面的代码显示了union操作并查看结果分区:
private void combineDataframes(Dataset<Row> df1 , Dataset<Row> df2 ) {
Dataset<Row> df = df1 .unionByName( df2 );//这就是组成一个union所需要的一切。
df .show(5);
df .printSchema();
System. out .println( "We have " + df .count() + " records." );
Partition[] partitions = df .rdd().partitions();
int partitionCount = partitions . length ;
//你能解释一下为什么有两个分区吗?两个数据集分区都是2,因此Spark保留了这个结构。
System. out .println( "Partition count: " + partitionCount );
}您可以联合更多的数据集,但不能在同一时间。
当您在一个dataframe中加载一个小型(通常小于128 MB)数据集时,Spark将只创建一个分区。但是,在这个场景中,Spark为基于css的数据集创建一个分区,为基于json的数据集创建一个分区。两个不同数据类型中的两个数据集至少会产生两个分区(每个数据集至少有一个分区)。将它们连接起来将创建一个惟一的dataframe,但是它将依赖于两个(或更多)原始分区。您可以尝试通过使用repartition()来修改示例,以查看Spark如何创建数据集和分区。使用分区不会带来很大的好处。在第17章中,您将看到分区可以提高在多个节点上拆分的大型数据集的性能,特别是(但不仅仅是)在连接操作中。
3.3 dataframe是Dataset<Row>
在本节中,您将了解有关dataframe实现的更多信息。您可以拥有几乎任何POJO的数据集,但是只有行数据集(dataset <Row>)被称为dataframe。让我们探索dataframe的好处,并进一步了解如何操作这些特定的数据集。
您可以将数据集与其他pojo一起使用,理解这一点很重要,因为您可以重用库中已有的pojo,或者更特定于您的应用程序的pojo。第9章说明了如何基于现有的pojo接入数据。
但是,dataframe实现为一个行数据集(dataset <Row>),具有更丰富的API。您将看到如何在需要时来回转换dataframe到dataset。
3.3.1重用pojo
让我们探讨在dataset API中直接重用pojo的好处,并进一步了解Spark存储。使用dataset而不是dataframe的主要好处是可以在Spark中直接重用pojo。dataset允许您使用熟悉的对象,而不受行带来的任何限制,比如从它提取数据。
当您查看dataset API时,将看到大量对Dataset<T>的引用,其中T代表泛型类型,而不是特定的行。但是,要注意,有些操作将丢失POJO的强类型,并返回Row:例如连接两个数据集或对数据集执行聚合。
这根本不是问题,但应该是一个预期的特性。例如,考虑一个基于书籍的数据集。如果按年对出版的图书进行group by,那么图书POJO中将没有count字段,因此Spark将自动创建一个dataframe来存储结果。
最后,Row使用称为Tungsten 的高效存储。但pojo不是这样的。
Tungsten :JAVA的疯狂快速存储
性能优化是一个永无止境的故事。Tungsten项目是Apache Spark的一个集成部分,它专注于增强三个关键领域:内存管理和二进制处理、感知缓存的计算和代码生成。让我们快速查看第一个领域以及Java存储对象的方式。
我喜欢Java(源自c++)的第一件事是,您不必跟踪内存使用情况和对象生命周期:所有这些都是由垃圾收集器(GC)完成的。尽管GC在大多数情况下都执行得很好,但当您处理数据集时,可能会很快被创建的数百万个对象所淹没。
存储一个4个字符的字符串,比如Java(8及以下版本)中的"Java"将占用48字节;使用UTF-8/ASCII编码时,存储这个字符串应该只占用4字节。Java Virtual Machine (JVM)本机字符串实现通过使用UTF-16编码的2字节对每个字符进行编码来不同地存储这些字符,并且每个字符串对象还包含一个12字节的头和8字节的哈希代码。当您调用Java(或任何其他基于JVM的语言).length()操作时,JVM仍然返回4,因为这是字符串在字符中的长度,而不是它在内存中的物理表示。请在http://openjdk.java.net/projects/code-tools/jol/查看JOL工具,以了解更多关于物理存储的信息。
GC和对象存储都是不错的选择。但是,在高性能和可预测的工作负载中,不能很好的进行数据处理。因此,一种更高效的存储系统诞生了。Tungsten直接管理内存块,压缩数据,并有新的数据容器,使用与操作系统的底层交互,性能提高了16倍到100倍。
3.3.2创建字符串数据集
为了理解如何使用datasets而不是dataframes,让我们看看如何创建一个简单的String类型的dataset。这将通过使用一个我们都很熟悉的简单对象——字符串来说明dataset的用法。然后,您将能够创建更复杂对象的dataset。
您的应用程序将从一个包含字符串的简单Java数组中创建一个字符串数据集,然后显示结果——没什么特别的。预期输出如下:
+------+
对应的代码如下:
package 要使用dataframe的扩展方法,您可以通过调用toDF()方法轻松地将dataset转换为dataframe。看看实验310(net.jgp .books.spark.ch03.lab310_dataset_to_dataframe.ArrayToDatasetToDataframeApp)。它在start()方法的末尾添加了以下代码片段:
Dataset输出与本节中的前一个实验(实验#300)相同,但是现在您有了一个dataframe!
3.3.3相互转换
在本节中,您将学习如何将一个dataframe转换为dataset并将其转换回dataframe。如果您希望操作现有的pojo和仅应用于dataframe的扩展API,那么这种转换非常有用。
您将读取一个CSV文件,其中包含一个dataframe中的图书。您将把dataframe转换为书籍的dataset,然后再转换回dataframe。尽管这听起来像是一个令人讨厌的流程,但作为一个Spark工程师,您可以参与其中的部分或全部操作。
想象一下下面的用例。在您的代码库中有一个现有的bookProcessor()方法。该方法获取Book POJO并通过api将其发布到Amazon、Fnac或Flipkart等商业网站上。您肯定不希望重写此方法以使用Spark。想使用Spark发布Book POJO。您可以加载数千本书,并将它们存储在一个图书dataset中,当您打算对它们进行迭代时,可以使用分布式处理来调用现有的bookProcessor()方法,而无需修改。
创建dataset
让我们关注第一部分:接入该文件并将dataframe转换为Book dataset。输出结果如下:
*** 在将dataframe转换为dataset之后,将对字段进行排序。这不是你要求应用程序去做的事情;这是一种奖励。然而,如果union两个数据集,记得使用unionByName()(而不是union()),因为字段顺序可能发生了变化。
应用程序如下所示。
package net.jgp.books.spark.ch03.lab320_dataset_books_to_dataframe;
import static org.apache.spark.sql.functions. concat ;
import static org.apache.spark.sql.functions. expr ;
import static org.apache.spark.sql.functions. lit ;
import static org.apache.spark.sql.functions. to_date ;
import java.io.Serializable;
import java.text.SimpleDateFormat;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import net.jgp.books.spark.ch03.x.model.Book;
public class CsvToDatasetBookToDataframeApp implements Serializable {
...
private void start() {
SparkSession spark = SparkSession. builder ()
.appName( "CSV to dataframe to Dataset<Book> and back" )
.master( "local" )
.getOrCreate();
String filename = "data/books.csv" ;
Dataset<Row> df = spark .read().format( "csv" )
.option( "inferSchema" , "true" )
.option( "header" , "true" )
.load( filename );
System. out .println( "*** Books ingested in a dataframe" );
df .show(5);
df .printSchema();
Dataset<Book> bookDs = df .map(
new BookMapper(),
Encoders.bean(Book. class ));
System. out .println( "*** Books are now in a dataset of books" );
bookDs .show(5, 17);
bookDs .printSchema();map()方法是一种有趣的动物,乍一看有点吓人,但它像小狗一样可爱。map()方法可能令人生畏,因为它需要更多的编码,而且它并不总是一个容易理解的概念。该方法将
- 检查数据集的每个记录
- 在MapFunction类的call()方法中做些什么
- 返回数据集
让我们更深入地了解一下map()方法签名。泛型在Java中并不总是很直接:
Dataset<U> map(MapFunction<T, U>, Encoder<U>)在你的情况下,U是Book, T是Row。因此map()方法签名是这样的:
Dataset<Book> map(MapFunction<Row, Book>, Encoder<Book>)被调用时,map()方法将
检查dataframe的每一条记录。
调用实现MapFunction<Row, Book>的类的实例;本例中是BookMapper。注意,它只实例化一次,无论处理的记录数量是多少。
返回Dataset<Book>(您的目标)。
在实现方法时,请确保具有正确的签名和实现,因为这可能比较棘手。包括签名和所需方法的骨架如下:
class 下面的清单将此骨架应用到正在构建的BookMapper mapper类。附录I列出了这些转换类型的引用,包括类签名。
class 您还需要一个表示图书(Book POJO)的简单POJO,如下一个清单所示。我删除了大多数getter和setter以简化可读性;我确信您可以在心里添加缺少的方法。将所有常见的工件存储在一个x子包中,以提高项目的可读性;在Eclipse中,x代表额外的。
package 创建dataframe
现在已经有了dataset,可以将其转换回dataframe,这样就可以执行join或聚合操作。
因此,让我们将dataset转换回dataframe来研究这部分机制。您将研究一个关于日期的有趣的情况,因为日期是以嵌套结构分割的。下面的清单显示了输出。
*** 现在,您已经准备好将dataset转换为一个dataframe,然后执行一些转换,例如将日期从这个讨厌的结构更改为dataframe中的日期列:
Dataset好吧,这并不难,对吧?要将dataset转换为dataframe,只需使用toDF()方法。但是,您仍然有这种奇怪的日期格式,所以让我们纠正它。第一步是将日期转换为具有该日期表示形式的字符串。在这种情况下,您将使用ANSI/ISO格式:YYYY - MM - DD,就像1971-10-05那样。
请记住,Java的起始年份是1900年,因此1971是71年,而2004是104年。同样地,月份从0开始,使得10月,一年的第10个月,成为第9个月。使用Java方法构建日期需要使用映射函数,如清单3.3所示。这是通过对数据的迭代来构建dataset或dataframe的方法。你也可以使用udf(第16章):
df2 静态函数expr()将计算一个类似sql的表达式并返回一个列。它可以使用字段名。表达式releaseDate.year + 1900将被spark转换计算,并将其转换为包含该值的列。releaseDate.year点表示法表示数据的路径,如清单3.5中的模式所示。您将通过示例看到更多静态函数,并将在第13章和附录G中学习转换。
一旦你有了一个日期字符串,你可以将它转换为一个日期,使用to_date()静态函数:
df2 您还可以drop()releaseDate列及其奇怪的结构;它不是很有用。现在您应该能够构建包含任何POJO的dataset,并将其转换为dataframe。
3.4 Dataframe的祖先:RDD
在前几节中,广泛地研究了dataset和dataframe。然而,Spark并不是带着这些组件诞生的。让我们来理解为什么记住弹性分布式数据集(RDD)的角色很重要。
在dataframes之前,Spark专门使用RDDs。不幸的是,您仍然会发现一些只依赖RDD而忽视或忽略数据的老警卫。为了避免疯狂的讨论,您应该知道什么是RDD,以及为什么在大多数应用程序中使用dataframes更容易,但是如果没有RDD它们就不能工作。
Spark最著名的创始人之一Matei Zaharia将RDD定义为:一种分布式内存抽象,它允许程序员以容错的方式在大型集群上执行内存中的计算。
RDDs的第一个实现是在Spark中。其想法是通过一组可靠的(弹性的)节点来实现内存中的计算:如果一个节点失败了,没有什么大不了的;另一个接替,比如raid5磁盘架构。RDD诞生时就有了不可变性的概念(在3.1.2节中定义)。
尽管围绕dataframe做了很多努力,RDDs并没有消失。没有人希望它们消失;它们仍然是Spark使用的低级存储层。
看待Dataframe和RDDs的一种方式是,Dataframe是RDDs的扩展。
如果说Dataframe是宏伟的,那么RDDs绝对不是丑陋和软弱的。RDDs将它们的所有存在都带到存储层。您应该考虑RDDs的时候:
- 您不需要模式。
- 您正在开发较低级别的transformation 和actions。
- 您有遗留代码。
RDDs是dataframes的基础块。正如您所看到的,在许多用例中,dataframes比RDD更容易使用,性能也更优,但是不要因为dataframes的高质量而取笑RDD的粉丝,明白吗?
总结
- dataframe是一个不可变的分布式数据集合,由指定的列组成。基本上,dataframe是一个带有模式的RDD。
- 一个dataframe被实现为一个行数据集——或者在代码中:dataset <Row>。
- dataset 被实现为除了行以外的任何数据集——或以代码的形式:dataset <String>, dataset <Book>,或dataset <SomePojo>。
- Dataframes可以存储列式信息(如CSV文件),也可以存储嵌套字段和数组(如JSON文件)。无论您使用的是CSV文件、JSON文件还是其他格式,dataframe API都是相同的。
- 在JSON文档中,可以使用点(.)访问嵌套字段。
- dataframe的API可以在http://mng.bz/qXYE中找到;有关如何使用dataframe的详细信息,请参阅参考部分。
- 静态方法的API可以在http://mng.bz/5AQD(及附录G)中找到;有关如何使用静态方法的详细信息,请参阅参考部分。
- 如果在联合两个dataframes时不关心列名,请使用union()。
- 如果在联合两个dataframes时关心列名,请使用unionByName()。
- 您可以在Spark的dataset中直接重用您的pojo。
- 如果要将对象作为dataset的一部分,则该对象必须是可序列化的。
- dataset的drop()方法删除dataframe中的一列。
- dataset的col()方法根据dataset的名称返回dataset的列。
- 静态函数的作用是:将一个日期字符串转换为一个日期。
- 静态函数expr()将使用字段名计算表达式的结果。
- lit()静态函数返回一个具有字面值的列。
- 弹性分布式数据集(RDD)是数据元素的不可变分布式集合。
- 当性能非常关键时,应该在RDD上使用dataframe。
- Tungsten存储器依靠dataframes。
- Catalyst是转换优化器(见第4章),它依靠dataframes来优化action和transformation。
- 跨越Spark库(图计算、SQL、机器学习或流处理)的API正在统一到dataframe API之下。















 290
290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









