







技术提高是一个循序渐进的过程,所以我讲的leetcode算法题从最简单的level开始写的,然后> 到中级难度,最后到hard难度全部完。目前我选择C语言,Python和Java作为实现语言,因为这三种语言还是比较典型的。由于篇幅和> 精力有限,其他语言的实现有兴趣的朋友请自己尝试。初级难度说的差不多的时候,我打算再加点其他内容,我可能会从操作系统到协议栈,从分布式> 聊到大数据框架,从大数据聊到人工智能,... ...。
如果有任何问题可以在文章后评论或者私信给我。
我会持续分享下去,敬请您的关注。
LeetCode 1002. 找出公共字符(Find Common Characters)
问题描述:
给定一个仅由小写字母组成的字符串数组A ,返回列表中所有字符串都存在的字符列表(包括重复的)。例如,如果一个字符在所有字符串中出现了3次但不是4次,则需要在最终答案中包含该字符三次。您可以按任何顺序返回答案。注:
1. 1 <= A.length <= 100
2. 1 <= A[i].length <= 100
3. A[i][j] 是一个小写字母
示例:

C语言实现:
我的实现是,先创建一个长度是26的数组counter,用来统计不同的字符作为公共字符出现的次数。
首先将A[0]中不同的字符出现的次数统计到counter中,单独对A[0]这样做,主要是为了填充counter,为后续的比较操作做准备。
然后我们开始从A[1]开始遍历数组A。在每次遍历中:
我们会创建一个局部的数组tmpCounter,它的形式和counter是完全一样的,用来统计当前字符串中不同的字符出现的次数。
tmpCounter的填充完成以后,要做的就是counter和tmpCounter的比较,这是最关键的步骤,比较的结果是,counter[i] = min(counter[i], tmpCounter[i])。即,counter只统计每个字符在所有字符串中出现次数的最小值。
当我们遍历结束的时候,counter里面统计的就是不同的字符作为公共字符出现的次数的状况。
最后我们遍历counter,填充返回数组res就可以了。
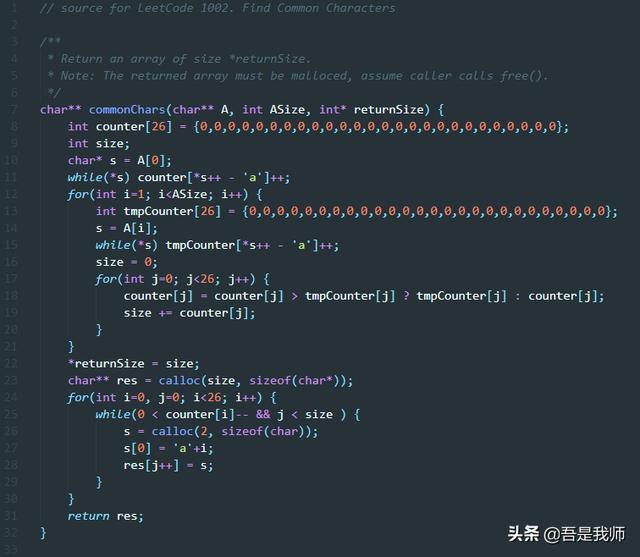
这里需要注意一点,对counter和tmpCounter的初始化,我们需要将去初始化为全0,推荐用静态初始化的方法,毕竟长度是只有26。不推荐用memset或bzero, 尤其是对于tmpCounter,每次循环都要将其重置为全0,如果用memset/bzero话,会有一些性能开销。
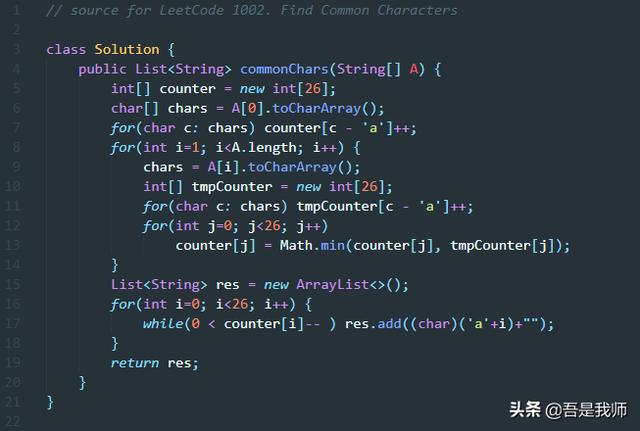
Java语言实现:
Java 的实现和C语言的实现一致,不再撰述。
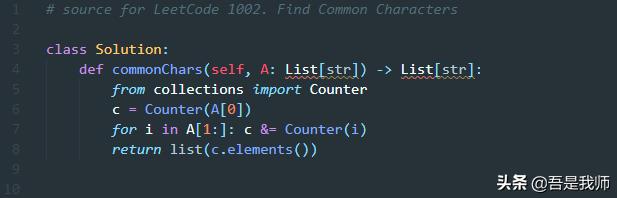
Python语言实现:
Python的话我们用Counter会比较简洁,其实思路和上面描述的没有本质区别,不再撰述。















 1688
1688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









