






今天读者群里有学员问我一个问题,他的交换机是华为的,他尝试用正则表达式去匹配交换机的hostname,这个hostname写在<>括号之间,比如下图中的。

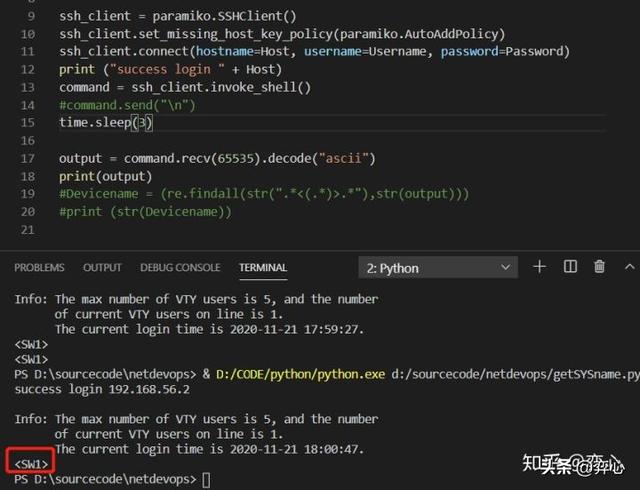
他的需求是只匹配<>里的内容,但是不匹配<>这两个括号其本身,并且他的交换机的hostname是没有统一格式的,也就是说交换机的hostname既可能是SW1,也可能是switch01,也可能是jiaohuanji001等等之类,hostname是完全没有规律,事先无法拿模板来套的。
要满足这种不管三七二十一只抓取括号里的内容,但是又不抓取括号本身的需求,正则表达式必须用到正向预查(Positive Lookbehind)和负向预查(Positive Lookahead)。
在正则表达式中,正向预查的写法为?<=,负向预查的写法为?=,下面举例讲解。
正向预查(Positive Lookbehind)
比如说我们有一个文本叫做abcd,现在我们希望匹配"a后面的bcd",那么可以用正向预查这么写:
(?<=a)bcd
这里的(?<=a)即为正向预查的写法,它代表的含义就是匹配a后面的内容,但是又不包含a本身,另外注意这里我们必须使用()(捕获分组的意思),如果你直接写成?<=a是不起作用的。
有人说,这里你直接用bcd做精确匹配不就行了吗?请注意,bcd的目的是"匹配bcd",但是 (?<=a)bcd的目的是匹配"a后面的bcd”,这两者是有本质上的区别的,你品,你细品。
负向预查(Positive Lookahead)
接下来再来看负向预查的写法,还是拿abcd来举例子,假设这里我们要匹配"d前面的abc",那么使用负向预查可以这么写
abc(?=d)
这里的(?=d)即为负向预查的写法,它代表的含义就是匹配d前面的内容,但是又不包含d本身。
知道了正向预查和负向预查的使用方法后,现在我们来看怎么匹配<>括号里的内容,但是又不匹配<>括号其本身,正则表达式写法如下:
(?<=)这里的(?<=为正向预查,它匹配的是
中间的.*?表示我们用非贪婪匹配来匹配<>中的所有内容。
最后的(?=>)为负向预查,它匹配的是>这个符号前面的内容(同样注意本身。
最后来做验证:

该学员也表示正则的这个写法完美解决了他的需求。

正则表达式是一门比较复杂的工具,这种抓取括号中的内容,但又不抓取括号其本身的需求在网络运维中是会偶尔碰上的,希望大家能彻底弄懂正则表达式中正向预查和负向预查的用法。















 1344
1344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









