





0| 引言
Pandas是基于NumPy的一种工具,该工具是为了解决数据分析任务而创建的。
Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
Pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
1| 创建Series
Series是Pandas中最基本的对象,Series类似一种一维数组。
事实上,Series基本上就是基于NumPy的数组对象来的。
和NumPy的数组不同,Series能为数据自定义标签,也就是索引(index),然后通过索引来访问数组中的数据。
import pandas as pdimport numpy as nps1 = pd.Series([4,7,-3,0])print(s1)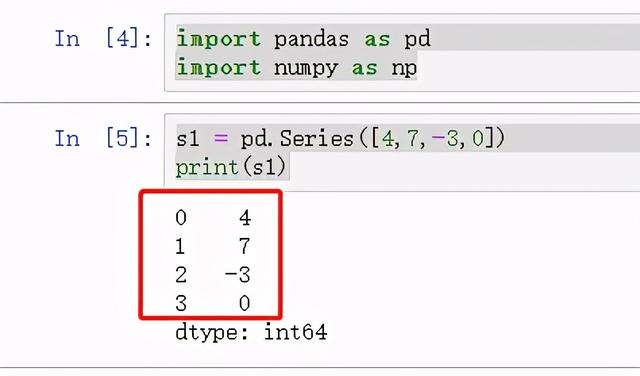
图 1 Series示例
- s1.values : 查看series的值
- s1.index : 查看series的索引值
s1.valuess1.index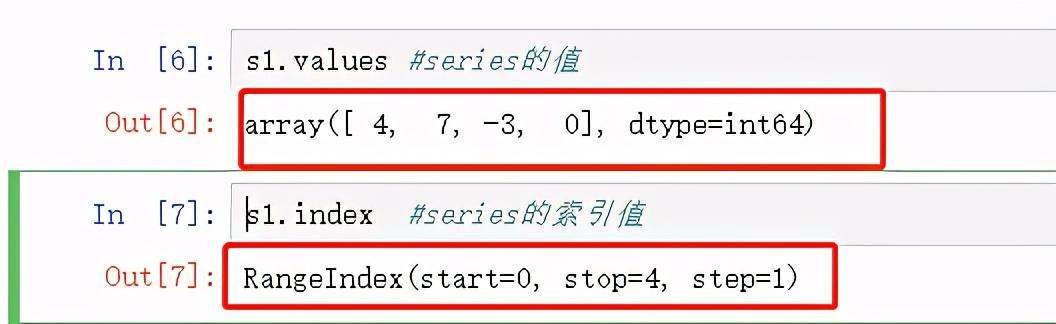
图2 查看values和index
s2 = pd.Series([4.0, 6.5, -0.5, 3],index= ['d','c','b','a'])print(s2)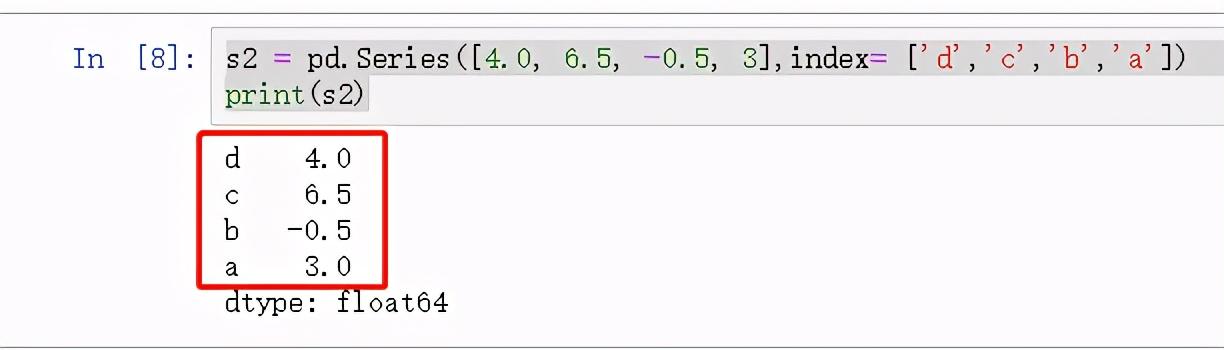
图3 s2示例
根据索引取值:
s2['b']s2[['a','b','c']]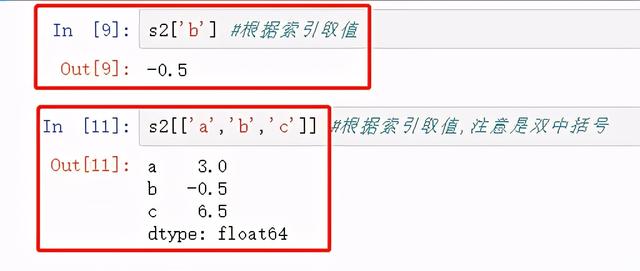
图4 根据索引取值

图5 查看索引序列是否在s2数组中
2| 创建DataFrame
DataFrame是一个二维的表结构.Pandas的DataFrame可以存储许多种不同的数据类型,
并且每一个坐标轴都有自己的标签。你可以把它想象成一个series的字典项。
# DataFramedata ={'year':[2013,2015,2016,2017], 'income':[1000, 2000,3000,4000], 'pay':[5000, 10000, 20000,30000] } # 以列排列df1=pd.DataFrame(data)df1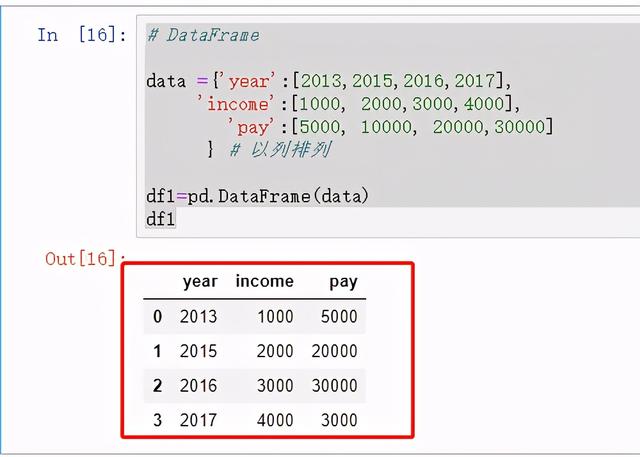
图6 DataFrame示例
DataFrame的属性
df1.columns :查看列元素
df1.index :查看索引
df1.values :查看所有元素
df1.describe:查看描述属性

图7 查看DataFrame的columns,index,values属性
describe(): 可以查看mean(), std(), min(), 四分之一分位,二分之一分位,四分之三分位,max()
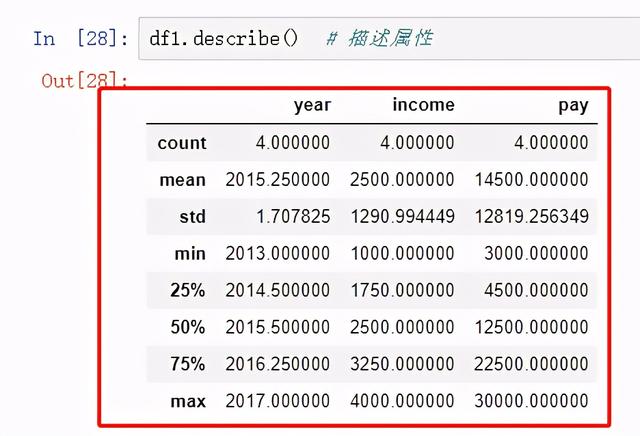
图8 查看describe属性
df3 =pd.DataFrame(np.arange(12).reshape((3,4)),index=['a','c','b'],columns=[2,33,44,5])df3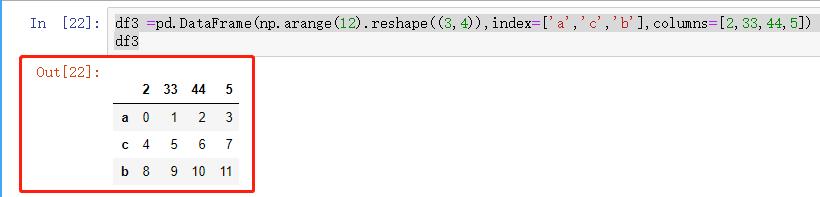
图8 示例
# 以列索引升序排列df3.sort_index(axis=1)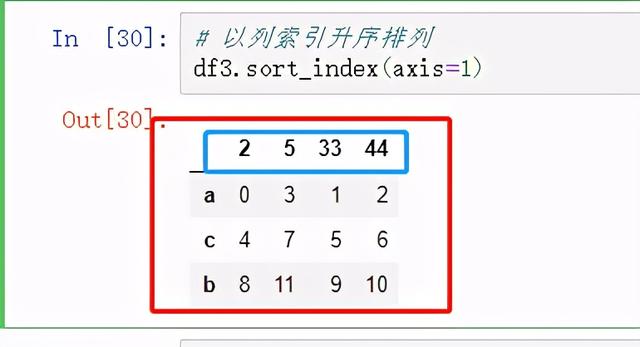
图9 列索引排序
# 以行索引升序排列df3.sort_index(axis=0)
图 10 行索引排序
# 以某值所对应的索引值进行排序df3.sort_values(by=44)
图 11 以某值所对应的索引值进行排序
3| Pandas的数据选择
import pandas as pd import numpy as npdates = pd.date_range('20170101',periods=6)df1 = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates, columns =['A','B','C','D'])df1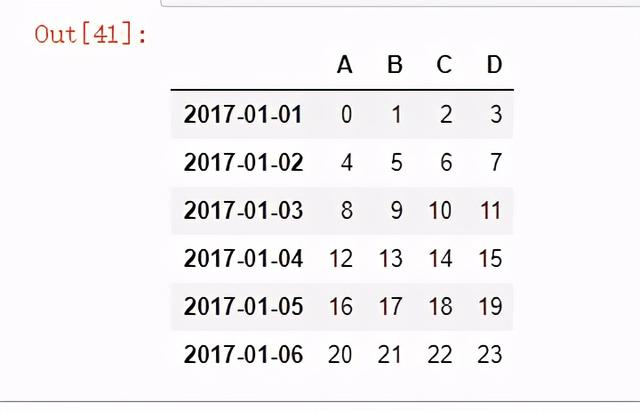
图12 示例
查看DataFrame的列Series
df1['A'] =df1.A
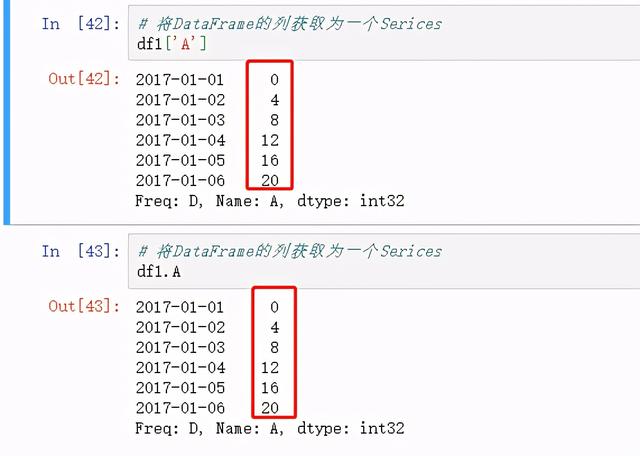
图 13
查看前两行:
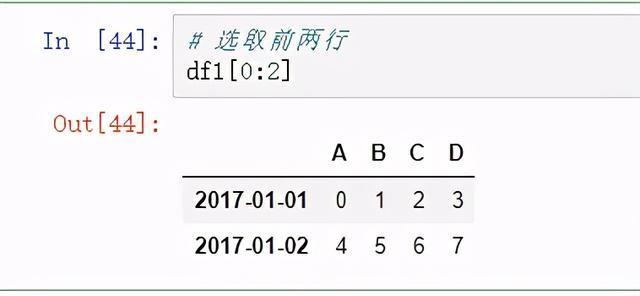
图14 查看前两行
以索引名选取:
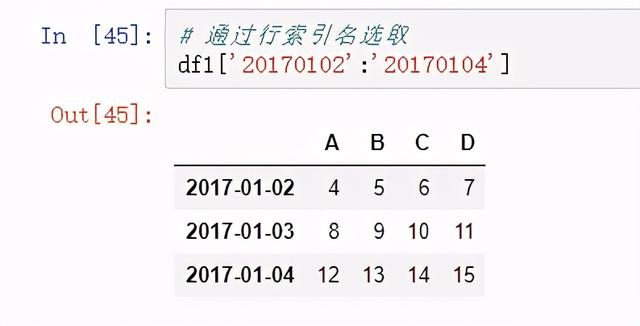
图15 以索引名选取
行索引:
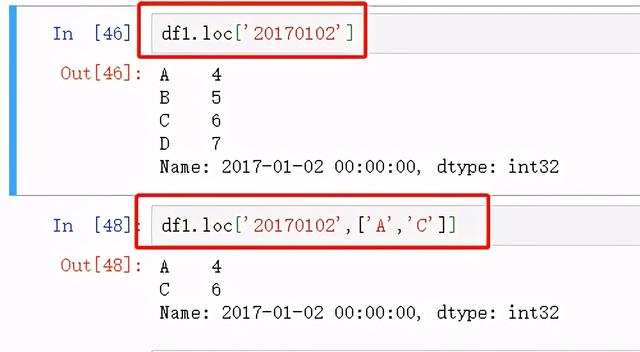
图16 行索引
通过位置【行与列】选择数据
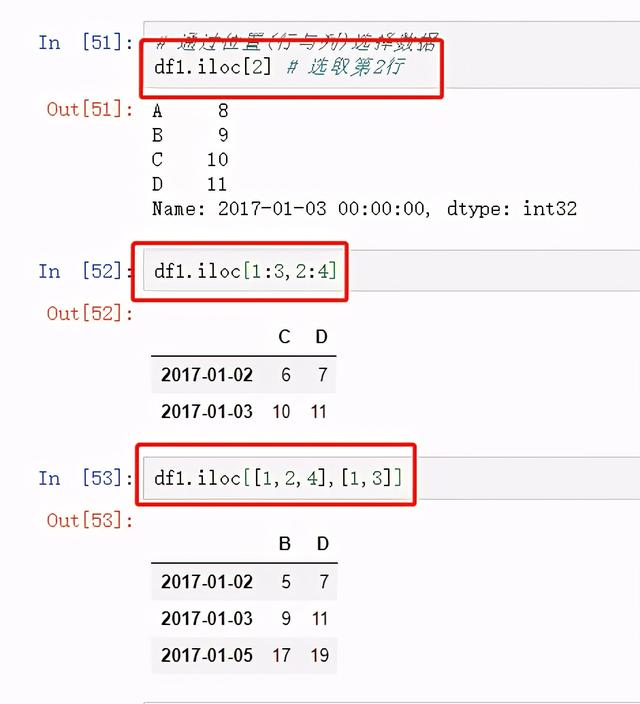
图17 通过位置索引
混合标签位置选择
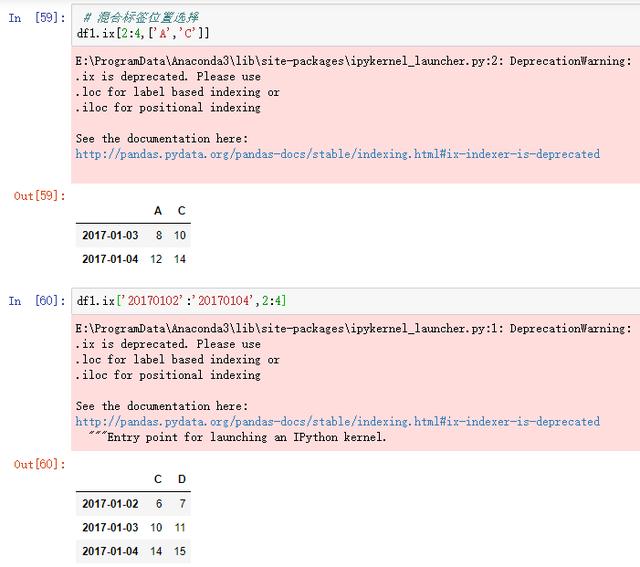
图18 混合标签索引
4 | Pandas的赋值与操作
import pandas as pd import numpy as npdates = np.arange(20201001,20201007)df1 =pd.DataFrame(np.arange(24).reshape((6,4)),index=dates, columns=['A','B','C','D'])df1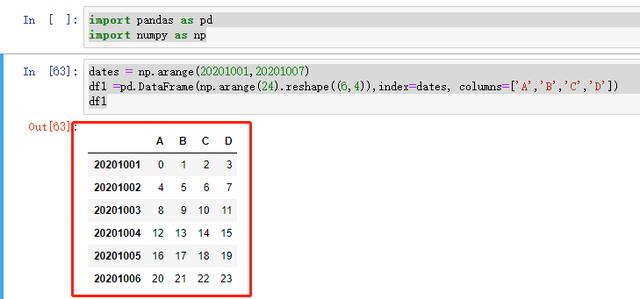
图 19 示例
利用位置赋值
df1.iloc[2,2]
图 20 查看位置
df1.iloc[2,2] =100df1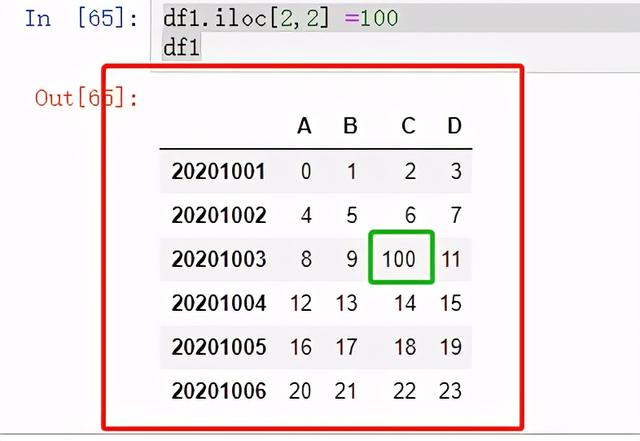
图 21 赋值
利用标签赋值
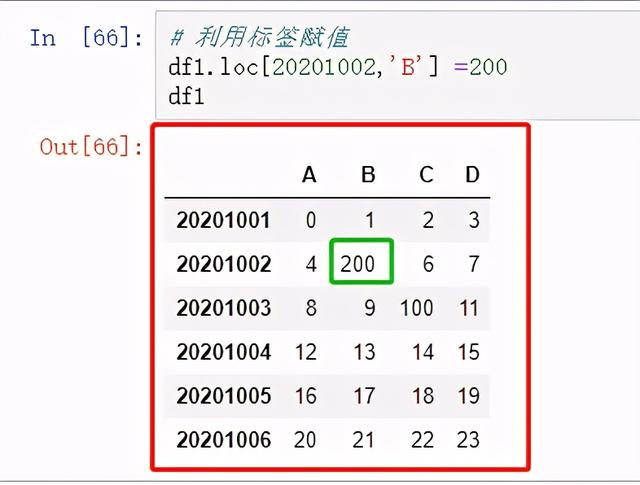
图 22 利用位置赋值
利用逻辑语句赋值
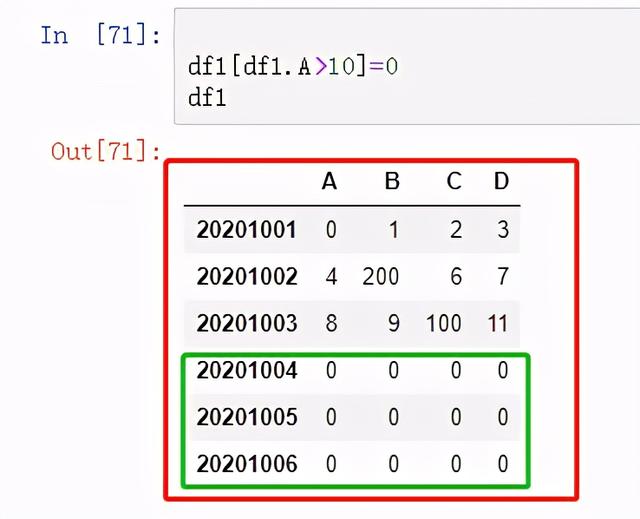
图 23 利用逻辑语句赋值1
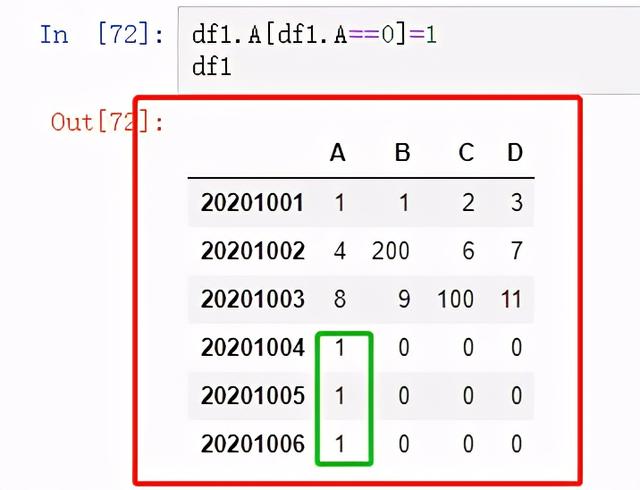
图24 利用逻辑语句 赋值2
添加一列:
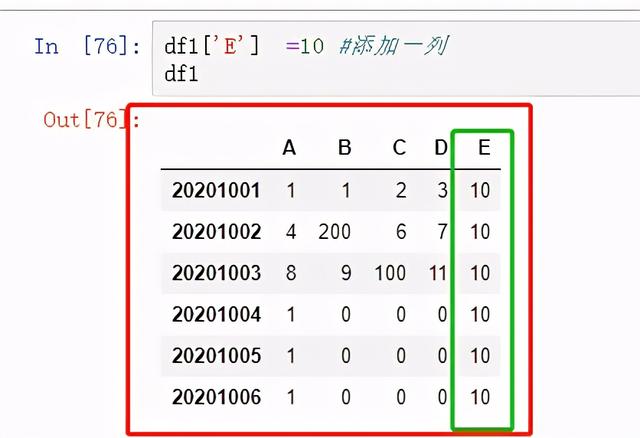
图 25 添加一列 1
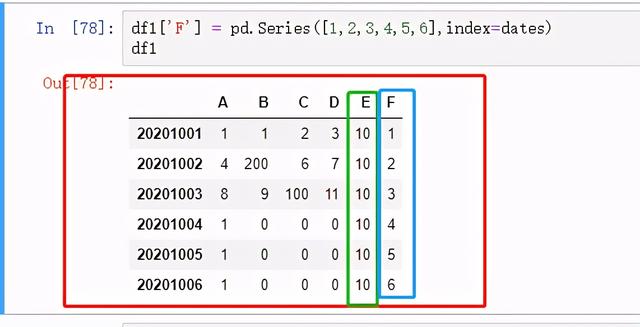
图 26 添加一列2
添加一行
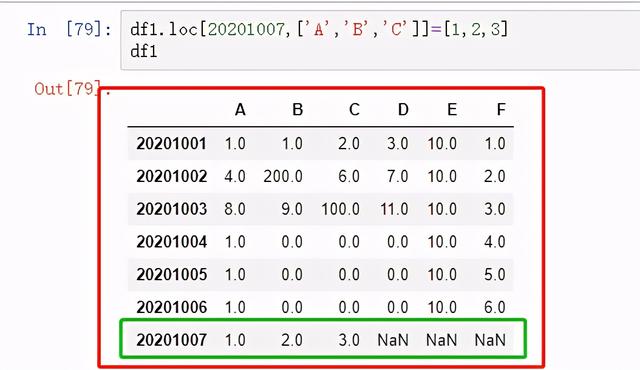
图 27 添加一行1
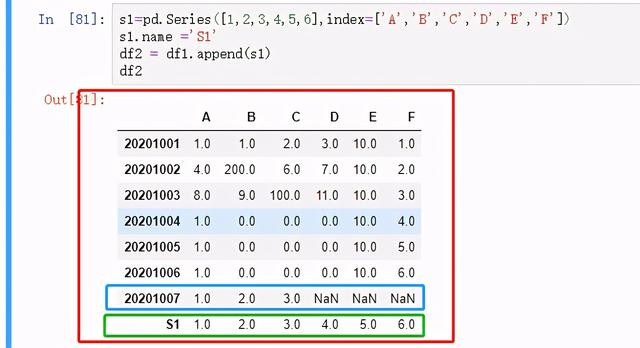
图 28 添加一行2
插入列
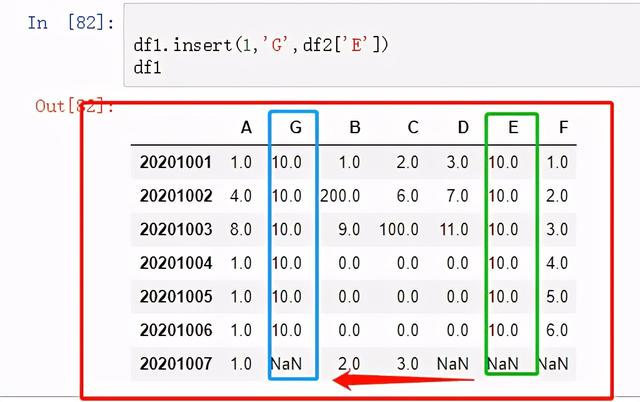
图29 将df2的E列元素,插入第2列的G标签的列
g = df1.pop('G')df1.insert(6,'G',g)df1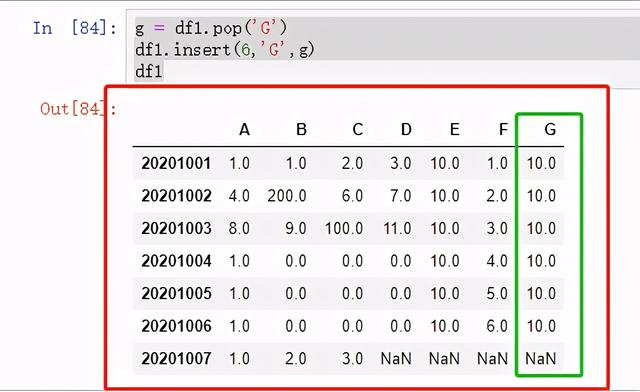
图 30 将g插入第7列的"G"列
删除 列
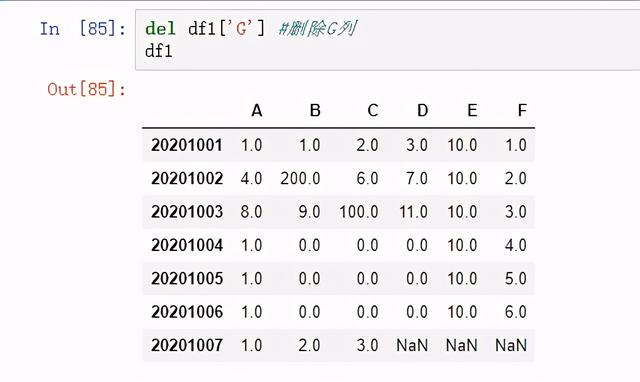
图 31 删除列
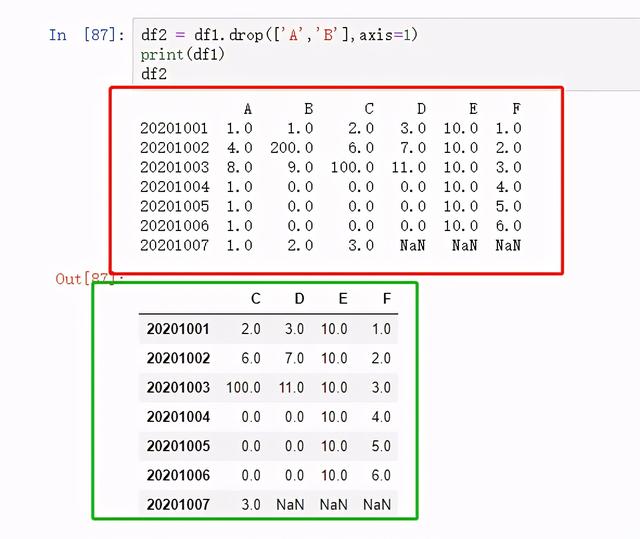
图 32 删除"A","B"列
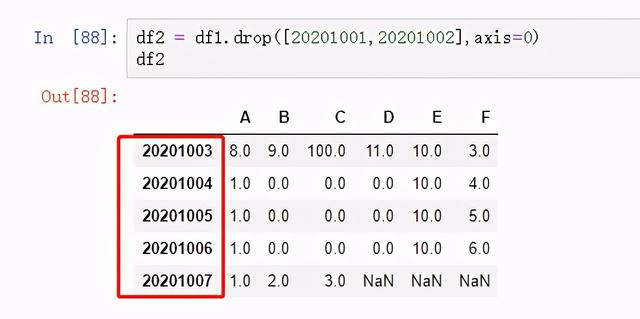
图 33 删除前两行
5 | Pandas 处理缺省值
import pandas as pd import numpy as npdates = np.arange(20201001,20201007)df1 = pd.DataFrame(np.arange(18).reshape((6,3)),index=dates, columns=['A','B','C'])df1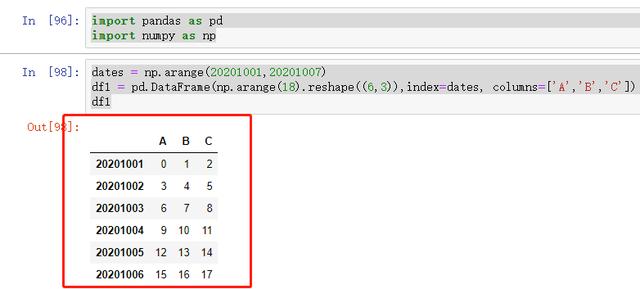
图 34 示例
df2 = pd.DataFrame(df1,index=dates, columns=['A','B','C','D','E'])df2 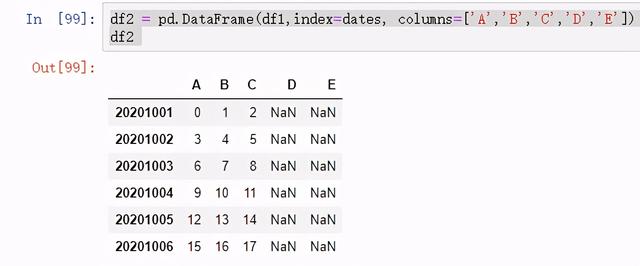
图 35 生成缺省数组 1
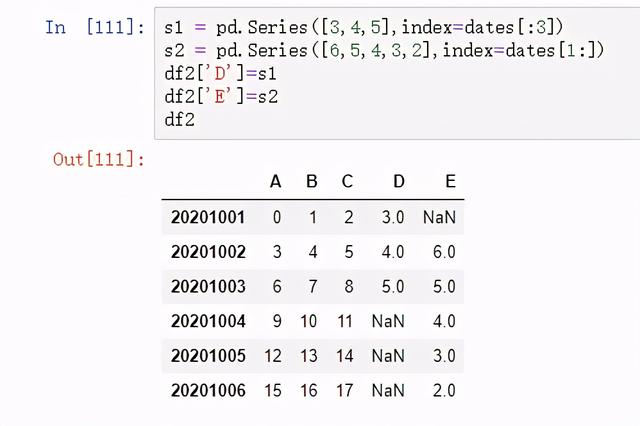
图 36 生成缺省数组 2
去除空值的行:
# 去除空值的行df2.dropna(axis=0, how='any') #axis =[0,1] 0表示行,列表示列。 how=['any','all'] any:表示任意一个NaN all:表示全部为NaN
图 37 去除空值的行1
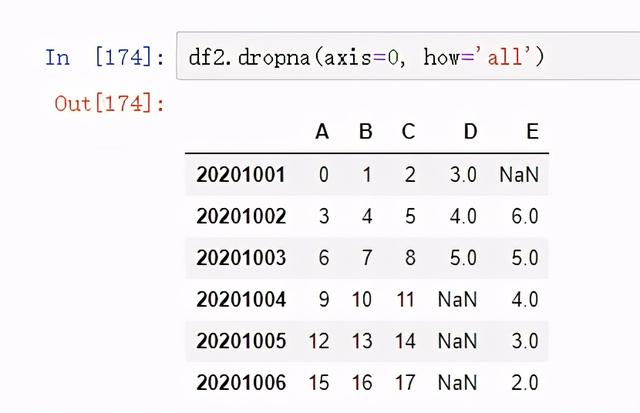
图 38 去除空值的行 2
将空值全部赋值为0:
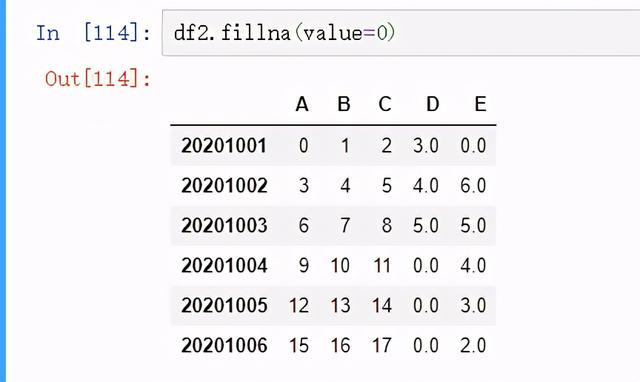
图 39 去除空值并赋值为0
查看空值
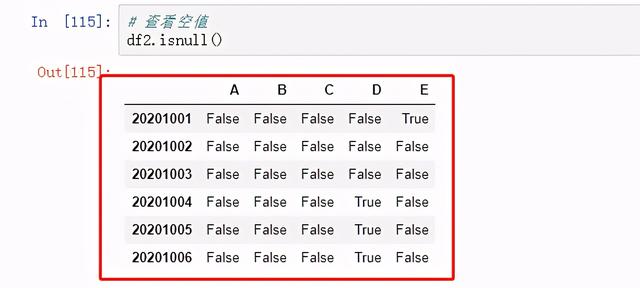
图 40 查看空值1
6|Pandas 合并
import pandas as pdimport numpy as npdf1 = pd.DataFrame(np.arange(12).reshape((3,4)),columns=['A','B','C','D'])df2 = pd.DataFrame(np.arange(12,24).reshape((3,4)),columns=['A','B','C','D'])df3 = pd.DataFrame(np.arange(24,36).reshape((3,4)),columns=['A','B','C','D'])print(df1)print('**__________**')print(df2)print('**__________**')print(df3)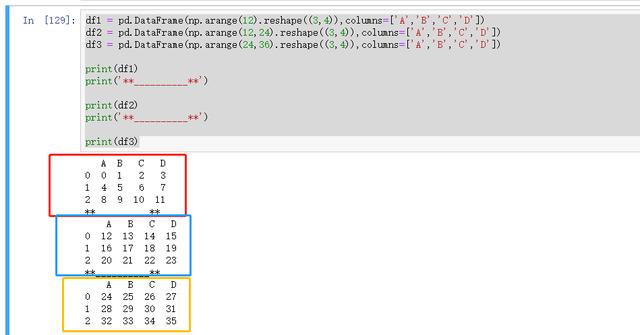
图 41 示例
纵向合并:
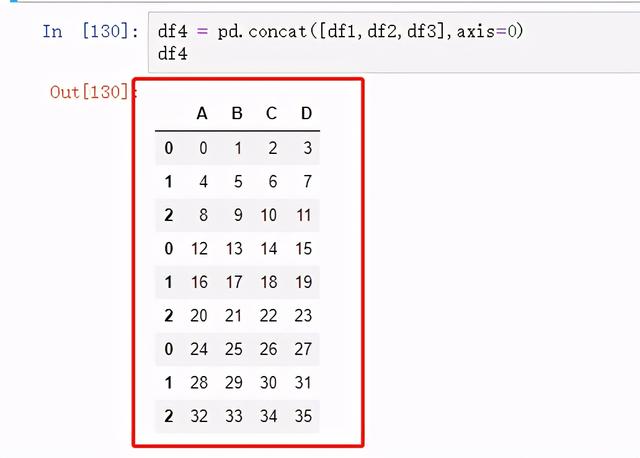
图42 纵向合并
纵向合并,不考虑原来的jndex
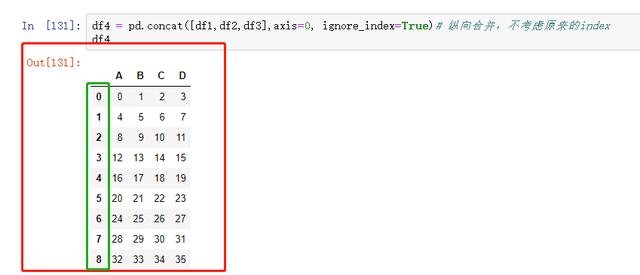
图43 纵向合并,不考虑原来的jndex
横向合并,不考虑原来的index

图44 横向合并,不考虑原来的index
生成两个表:
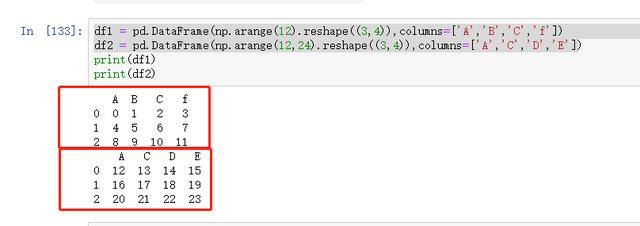
图 45 生成两个表
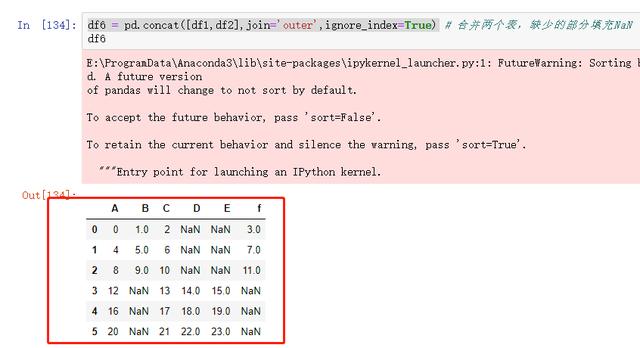
图 46 合并两个表,缺少部分用NaN填充
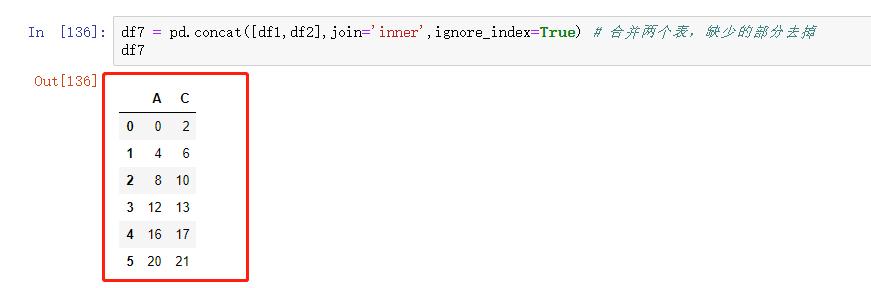
图 47 合并两个表, 缺少部分去掉
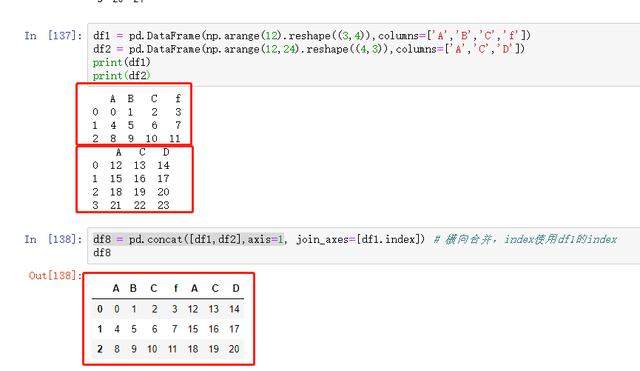
图 48 横向合并
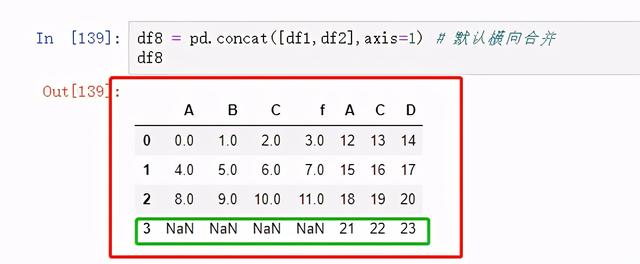
图 49 默认合并















 4338
4338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









