






HashSet是Set接口的一个实现类,它所存储的元素是不可重复的,并且元素都是无序的。当向HashSet集合中添加一个对象时,首先会调用该对象的hashCode()方法来确定元素的存储位置,然后再调用对象的equals()方法来确保该位置没有重复元素。Set集合与List集合存取元素的方式都一样,在此不再进行详细的讲解,接下来通过一个案例来演示HashSet集合的用法,如例所示。import java.util.Enumeration;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Vector;
public class Example {
public static void main(String[] args) {
HashSet set = new HashSet(); // 创建HashSet 集合
set.add("Jack"); // 向该Set 集合中添加字符串
set.add("Eve");
set.add("Rose");
set.add("Rose"); // 向该Set 集合中添加重复元素
Iterator it = set.iterator(); // 获取Iterator 对象
while (it.hasNext()) { // 通过while 循环,判断集合中是否有元素
Object obj = it.next(); // 如果有元素,就通过迭代器的next()方法获取元素
System.out.println(obj);
}
}
}
运行结果:Eve
Rose
Jack
例中,首先通过add()方法向HashSet集合依次添加了四个字符串,然后通过Iterator迭代器遍历所有的元素并输出打印。从打印结果可以看出取出元素的顺序与添加元素的顺序并不一致,并且重复存入的字符串对象“Rose”被去除了,只添加了一次。
HashSet集合之所以能确保不出现重复的元素,是因为它在存入元素时做了很多工作。当调用HashSet集合的add()方法存入元素时,首先调用当前存入对象的hashCode()方法获得对象的哈希值,然后根据对象的哈希值计算出一个存储位置。如果该位置上没有元素,则直接将元素存入,如果该位置上有元素存在,则会调用equals()方法让当前存入的元素依次和该位置上的元素进行比较,如果返回的结果为false就将该元素存入集合,返回的结果为true则说明有重复元素,就将该元素舍弃。整个存储的流程如图所示。
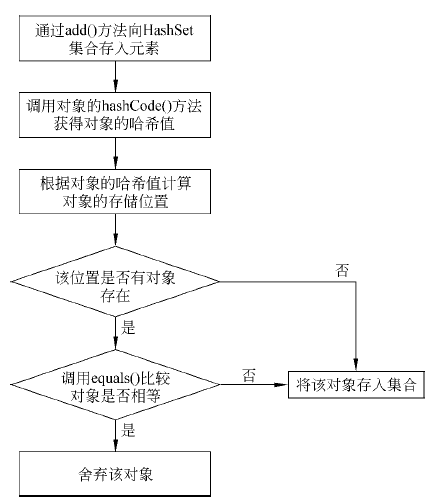
根据前面的分析不难看出,当向集合中存入元素时,为了保证HashSet正常工作,要求在存入对象时,重写该类中的hashCode()和equals()方法。例中将字符串存入HashSet时,String类已经重写了hashCode()和equals()方法。但是如果将Student对象存入HashSet,结果又如何呢? 接下来通过一个案例来进行演示,如例所示。import java.util.HashSet;
class Student {
String id;
String name;
public Student(String id, String name) { // 创建构造方法
this.id = id;
this.name = name;
}
public String toString() { // 重写toString()方法
return id + ":" + name;
}
}
public class Example {
public static void main(String[] args) {
HashSet hs = new HashSet(); // 创建HashSet 集合
Student stu1 = new Student("1", "Jack"); // 创建Student 对象
Student stu2 = new Student("2", "Rose");
Student stu3 = new Student("2", "Rose");
hs.add(stu1);
hs.add(stu2);
hs.add(stu3);
System.out.println(hs);
}
}
运行结果:[2:Rose, 1:Jack, 2:Rose]
在例中,向HashSet集合存入三个Student对象,并将这三个对象迭代输出。图所示的运行结果中出现了两个相同的学生信息“2:Rose”,这样的学生信息应该被视为重复元素,不允许同时出现在HashSet集合中。之所以没有去掉这样的重复元素是因为在定义Student类时没有重写hashCode()和equals()方法。接下来针对例中的Student类进行改写,假设id相同的学生就是同一个学生,改写后的代码如例所示。import java.util.HashSet;
class Student {
private String id;
private String name;
public Student(String id, String name) {
this.id = id;
this.name = name;
}
// 重写toString()方法
public String toString() {
return id + ":" + name;
}
// 重写hashCode 方法
public int hashCode() {
return id.hashCode(); // 返回id 属性的哈希值
}
// 重写equals 方法
public boolean equals(Object obj) {
if (this == obj) { // 判断是否是同一个对象
return true; // 如果是,直接返回true
}
if (!(obj instanceof Student)) { // 判断对象是为Student 类型
return false; // 如果对象不是Student 类型,返回false
}
Student stu = (Student) obj; // 将对象强转为Student 类型
boolean b = this.id.equals(stu.id); // 判断id 值是否相同
return b; // 返回判断结果
}
}
public class Example {
public static void main(String[] args) {
HashSet hs = new HashSet(); // 创建HashSet 对象
Student stu1 = new Student("1", "Jack"); // 创建Student 对象
Student stu2 = new Student("2", "Rose");
Student stu3 = new Student("2", "Rose");
hs.add(stu1); // 向集合存入对象
hs.add(stu2);
hs.add(stu3);
System.out.println(hs); // 打印集合中的元素
}
}
运行结果:[1:Jack, 2:Rose]
在例7-11 中,Student类重写了Object类的hashCode()和equals()方法。在hashCode()方法中返回id属性的哈希值,在equals()方法中比较对象的id属性是否相等,并返回结果。当调用HashSet集合的add()方法添加stu3对象时,发现它的哈希值与stu2对象相同,而且stu2.equals(stu3)返回true,HashSet集合认为两个对象相同,因此重复的Student对象被成功去除了。















 1054
1054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









