






# 基础篇
## Java基础知识
### 基本数据类型
#### 自动拆装箱
**1、实现原理**:
自动装箱:包装类.valueOf();
自动拆箱:包装类.xxxValue();
**2、应用场景:**
1、将基本类型放入集合中时(Java中的集合只能存储对象所以存储基本类型会进行自动装箱)
2、包装类与基本类型进行运算时,或者包装类之间进行运算时
3、函数参数与返回值
#### 拆装箱缓存机制
Java SE的自动拆装箱还提供了一个和缓存有关的功能,我们先来看以下代码,猜测一下输出结果:
```java
public static void main(String... strings) {
Integer integer1 = 3;
Integer integer2 = 3;
if (integer1 == integer2)
System.out.println("integer1 == integer2");
else
System.out.println("integer1 != integer2");
Integer integer3 = 300;
Integer integer4 = 300;
if (integer3 == integer4)
System.out.println("integer3 == integer4");
else
System.out.println("integer3 != integer4");
}复制ErrorOK!
```
我们普遍认为上面的两个判断的结果都是false。虽然比较的值是相等的,但是由于比较的是对象,而对象的引用不一样,所以会认为两个if判断都是false的。在Java中,==比较的是对象应用,而equals比较的是值。所以,在这个例子中,不同的对象有不同的引用,所以在进行比较的时候都将返回false。奇怪的是,这里两个类似的if条件判断返回不同的布尔值。
上面这段代码真正的输出结果:
```
integer1 == integer2
integer3 != integer4复制ErrorOK!
```
原因就和Integer中的缓存机制有关。在Java 5中,在Integer的操作上引入了一个新功能来节省内存和提高性能。整型对象通过使用相同的对象引用实现了缓存和重用。
> 适用于整数值区间-128 至 +127。
>
> 只适用于自动装箱。使用构造函数创建对象不适用。
具体的代码实现可以阅读[Java中整型的缓存机制](http://www.hollischuang.com/archives/1174)一文,这里不再阐述。
我们只需要知道,当需要进行自动装箱时,如果数字在-128至127之间时,会直接使用缓存中的对象,而不是重新创建一个对象。
其中的javadoc详细的说明了缓存支持-128到127之间的自动装箱过程。最大值127可以通过`-XX:AutoBoxCacheMax=size`修改。
实际上这个功能在Java 5中引入的时候,范围是固定的-128 至 +127。后来在Java 6中,可以通过`java.lang.Integer.IntegerCache.high`设置最大值。
这使我们可以根据应用程序的实际情况灵活地调整来提高性能。到底是什么原因选择这个-128到127范围呢?因为这个范围的数字是最被广泛使用的。 在程序中,第一次使用Integer的时候也需要一定的额外时间来初始化这个缓存。
在Boxing Conversion部分的Java语言规范(JLS)规定如下:
如果一个变量p的值是:
```
-128至127之间的整数(§3.10.1)
true 和 false的布尔值 (§3.10.3)
‘\u0000’至 ‘\u007f’之间的字符(§3.10.4)复制ErrorOK!
```
范围内的时,将p包装成a和b两个对象时,可以直接使用a==b判断a和b的值是否相等。
这种缓存行为不仅适用于Integer对象。我们针对所有的整数类型的类都有类似的缓存机制。
> 有ByteCache用于缓存Byte对象
>
> 有ShortCache用于缓存Short对象
>
> 有LongCache用于缓存Long对象
>
> 有CharacterCache用于缓存Character对象
`Byte`, `Short`, `Long`有固定范围: -128 到 127。对于`Character`, 范围是 0 到 127。除了`Integer`以外,这个范围都不能改变。
#### 自动拆箱带来的问题
当然,自动拆装箱是一个很好的功能,大大节省了开发人员的精力,不再需要关心到底什么时候需要拆装箱。但是,他也会引入一些问题。
> 包装对象的数值比较,不能简单的使用`==`,虽然-128到127之间的数字可以,但是这个范围之外还是需要使用`equals`比较。
>
> 前面提到,有些场景会进行自动拆装箱,同时也说过,由于自动拆箱,如果包装类对象为null,那么自动拆箱时就有可能抛出NPE。
>
> 如果一个for循环中有大量拆装箱操作,会浪费很多资源。
#### 什么时候使用包装类型
1、所有的POJO类属性使用包装类型,如果为Boolean类型,变量名不能以is开头,IDE自动生成布尔型变量的getter方法名称一般以is开头,在序列化时可能会导致找不到变量;
### String
#### substring()方法的使用
**1、JDK 6中的substring**
String是通过字符数组实现的。在jdk 6 中,String类包含三个成员变量:`char value[]`, `int offset`,`int count`。他们分别用来存储真正的字符数组,数组的第一个位置索引以及字符串中包含的字符个数。
当调用substring方法的时候,会创建一个新的string对象,但是这个string的值仍然指向堆中的同一个字符数组。这两个对象中只有count和offset 的值是不同的。
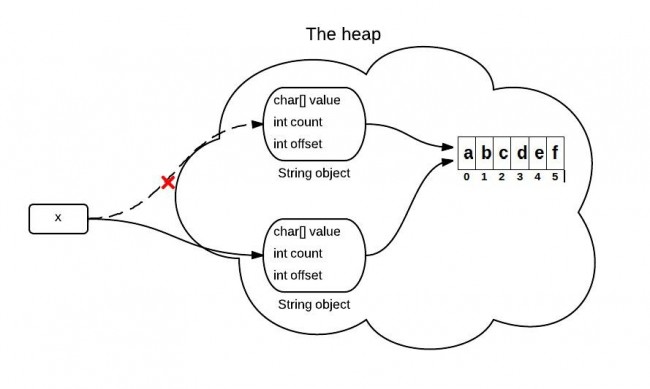
下面是证明上说观点的Java源码中的关键代码:
```java
//JDK 6
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}
public String substring(int beginIndex, int endIndex) {
//check boundary
return new String(offset + beginIndex, endIndex - beginIndex, value);
}
```
**2、JDK 6中的substring导致的问题**
如果你有一个很长很长的字符串,但是当你使用substring进行切割的时候你只需要很短的一段。这可能导致性能问题,因为你需要的只是一小段字符序列,但是你却引用了整个字符串(因为这个非常长的字符数组一直在被引用,所以无法被回收,就可能导致内存泄露)。在JDK 6中,一般用以下方式来解决该问题,原理其实就是生成一个新的字符串并引用他。
```java
x = x.substring(x, y) + ""
```
关于JDK 6中subString的使用不当会导致内存系列已经被官方记录在Java Bug Database中:
> 内存泄露:在计算机科学中,内存泄漏指由于疏忽或错误造成程序未能释放已经不再使用的内存。 内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,导致在释放该段内存之前就失去了对该段内存的控制,从而造成了内存的浪费。
**3、JDK 7 中的substring**
上面提到的问题,在jdk 7中得到解决。在jdk 7 中,substring方法会在堆内存中创建一个新的数组。
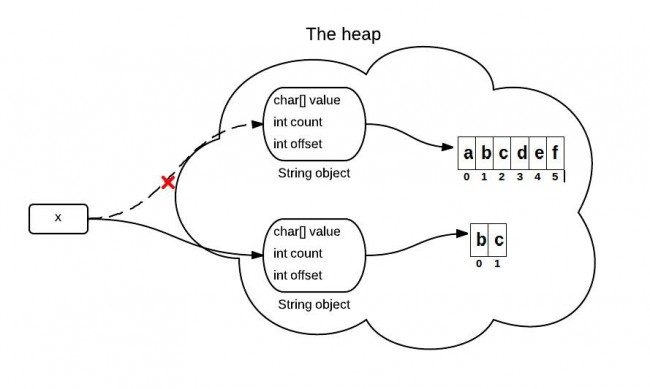
Java源码中关于这部分的主要代码如下:
```java
//JDK 7
public String(char value[], int offset, int count) {
//check boundary
this.value = Arrays.copyOfRange(value, offset, offset + count);
}
public String substring(int beginIndex, int endIndex) {
//check boundary
int subLen = endIndex - beginIndex;
return new String(value, beginIndex, subLen);
}
```
以上是JDK 7中的subString方法,其使用`new String`创建了一个新字符串,避免对老字符串的引用。从而解决了内存泄露问题。
所以,如果你的生产环境中使用的JDK版本小于1.7,当你使用String的subString方法时一定要注意,避免内存泄露。
####字符串拼接
`StringBuilder`
#### switch对String的支持
Java 7中,switch的参数可以是String类型了,这对我们来说是一个很方便的改进。到目前为止switch支持这样几种数据类型:`byte` `short` `int` `char` `String` 。
switch
1. 对于整型的实现就是直接比较大小
2. 对于char的实现是通过ASCII码,通过转化成int比较
3. 对于String
```java
public class switchDemoString {
public static void main(String[] args) {
String str = "world";
switch (str) {
case "hello":
System.out.println("hello");
break;
case "world":
System.out.println("world");
break;
default:
break;
}
}
}
```
对代码进行反编译:
```java
public class switchDemoString
{
public switchDemoString()
{
}
public static void main(String args[])
{
String str = "world";
String s;
switch((s = str).hashCode())
{
default:
break;
case 99162322:
if(s.equals("hello"))
System.out.println("hello");
break;
case 113318802:
if(s.equals("world"))
System.out.println("world");
break;
}
}
}
```
看到这个代码,你知道原来字符串的switch是通过`equals()`和`hashCode()`方法来实现的。**记住,switch中只能使用整型**,比如`byte`。`short`,`char`(ackii码是整型)以及`int`。还好`hashCode()`方法返回的是`int`,而不是`long`。通过这个很容易记住`hashCode`返回的是`int`这个事实。仔细看下可以发现,进行`switch`的实际是哈希值,然后通过使用equals方法比较进行安全检查,这个检查是必要的,因为哈希可能会发生碰撞。因此它的性能是不如使用枚举进行switch或者使用纯整数常量,但这也不是很差。因为Java编译器只增加了一个`equals`方法,如果你比较的是字符串字面量的话会非常快,比如”abc” ==”abc”。如果你把`hashCode()`方法的调用也考虑进来了,那么还会再多一次的调用开销,因为字符串一旦创建了,它就会把哈希值缓存起来。因此如果这个`switch`语句是用在一个循环里的,比如逐项处理某个值,或者游戏引擎循环地渲染屏幕,这里`hashCode()`方法的调用开销其实不会很大。
好,以上就是关于switch对整型、字符型、和字符串型的支持的实现方式,总结一下我们可以发现,**其实switch只支持一种数据类型,那就是整型,其他数据类型都是转换成整型之后在使用switch的。**
### 集合体系
#### List
List主要有ArrayList、LinkedList与Vector几种实现。
这三者都实现了List 接口,使用方式也很相似,主要区别在于因为实现方式的不同,所以对不同的操作具有不同的效率。
ArrayList 是一个可改变大小的数组.当更多的元素加入到ArrayList中时,其大小将会动态地增长.内部的元素可以直接通过get与set方法进行访问,因为ArrayList本质上就是一个数组.
LinkedList 是一个双链表,在添加和删除元素时具有比ArrayList更好的性能.但在get与set方面弱于ArrayList.
当然,这些对比都是指数据量很大或者操作很频繁的情况下的对比,如果数据和运算量很小,那么对比将失去意义.
Vector 和ArrayList类似,但属于强同步类。如果你的程序本身是线程安全的(thread-safe,没有在多个线程之间共享同一个集合/对象),那么使用ArrayList是更好的选择。
Vector和ArrayList在更多元素添加进来时会请求更大的空间。Vector每次请求其大小的双倍空间,而ArrayList每次对size增长50%.
而 LinkedList 还实现了 Queue 接口,该接口比List提供了更多的方法,包括 offer(),peek(),poll()等.
注意: 默认情况下ArrayList的初始容量非常小,所以如果可以预估数据量的话,分配一个较大的初始值属于最佳实践,这样可以减少调整大小的开销。
一键复制
编辑
Web IDE
原始数据
按行查看
历史
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









