






在前几天写的一建抓取网站所有链接的脚步往后衍生了以下的两个脚步,一个是查询网站友情链接,另一个是查询网站的死链。我这里只是初步实现了功能,还有很多地方需要优化,比如说查询友情链接脚步会存在带www与不带www不能共存识别的问题,查询网站死链的脚步运行好慢的问题,这个问题是我目前解决不了的,我的能力还有限。
很多人说,爬虫学的好,“劳烦”吃的 饱。所以,在爬虫教程中,都会劝说大家善良,但是我现在能力有限,可以随便放开造,如果有喜欢一起学习的朋友,可以加我微信,相互讨论,共同学习。下面分享这两个脚步源代码,供大家欣赏,^_^。
一、友情链接查询
Python
import requests
from bs4 import BeautifulSoup
import time
url=input("输入主域名:")
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
def shouye():
r=requests.get(url,headers=headers)
soup=BeautifulSoup(r.content.decode('utf-8',"ignore"),'lxml')
suoyoua=soup.find_all('a')
alla=[]
for lia in suoyoua:
dana=lia.get("href")
try:
if dana.find('http')!=-1 and dana.find(url) == -1:
alla.append(dana)
except:
continue
# 去重
alla=sorted(set(alla), key=alla.index)
fanhui(alla)
def fanhui(alla):
for duiurl in alla:
try:
r=requests.get(duiurl,headers=headers)
except:
print('该网站打不开', duiurl)
continue
try:
soup = BeautifulSoup(r.content.decode('utf-8',"ignore"), 'lxml')
except Exception as ex:
print(duiurl,ex)
suoyoua = soup.find_all('a')
sya=[]
for lia in suoyoua:
dana = lia.get("href")
sya.append(dana)
sya=str(sya)
if sya.find(url)==-1:
print('该网站没有我们网站链接',duiurl)
if __name__ == '__main__':
startime = time.time()
shouye()
endtime = time.time()
thetime=endtime-startime
print(thetime)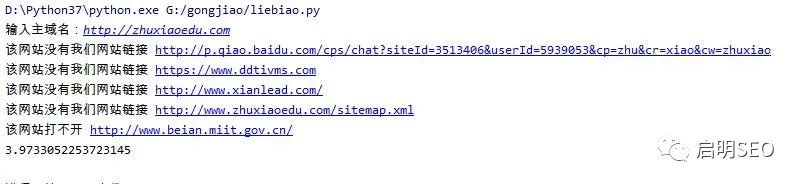
二、死链接查询
Python
import requests
from bs4 import BeautifulSoup
# 进程
from threading import Thread
import time
bbb=[]
jishu=0
def shouye():
global jishu
url=input("输入主域名:")
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
r=requests.get(url,headers=headers)
soup=BeautifulSoup(r.content.decode('utf-8'),'lxml')
suoyoua=soup.find_all('a')
alla=[]
for lia in suoyoua:
dana=lia.get("href")
alla.append(dana)
# 去重
alla=sorted(set(alla), key=alla.index)
# 开启多线程
t_list = []
for lianjie in alla:
for i in range(5):
t = Thread(target=neiye, args=(lianjie, url))
t_list.append(t)
t.start()
# 回收线程
for t in t_list:
t.join()
def neiye(lianjie,url):
global bbb
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
if lianjie.find(url)!=-1:
ciurl= lianjie
elif lianjie.find('http')==-1 and lianjie.find('/')!=-1:
ciurl=url + lianjie
else:
ciurl = url + '/' + lianjie
r = requests.get(ciurl , headers=headers)
bba=[]
alla = []
try:
soup = BeautifulSoup(r.content.decode('utf-8'), 'lxml')
suoyoua = soup.find_all('a')
except:
bba.append(ciurl)
else:
for lia in suoyoua:
try:
dana = lia.get("href")
except:
continue
alla.append(dana)
# 去重
alla = sorted(set(alla), key=alla.index)
global jishu
for lian2 in alla:
if lian2 in bbb:
continue
else:
bbb.append(lian2)
neiye(lian2,url)
if __name__ == '__main__':
startime = time.time()
shouye()
bbb = sorted(set(bbb), key=bbb.index)
num=0
for ads in bbb:
if ads.find('http')!=-1:
ads=ads
else:
ads='http://zhuxiaoedu.com'+ads
print(num, ads)
num += 1
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
try:
r = requests.get(ads, headers=headers)
except Exception as e:
print(e)
continue
print(r.status_code)
endtime = time.time()
thetime=endtime-startime
print(thetime)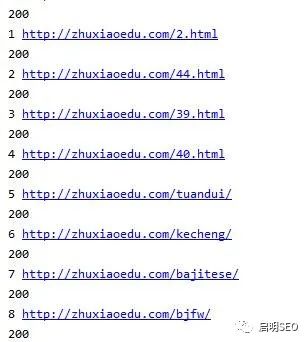
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









