





作者:上善若水 来源:公众号码农有道这几天没事的时候,翻了翻<>这本书,中间有一节通过一个问题讲述了一种比较巧妙的排序方法—位图排序。我们还是先看问题吧。
问题描述
编程珠玑这本书给出的问题如下:
- 输入:一个至多包含n个非负整数的文件,每个数都小于n; 且这些整数都不重复;数据之间也不存在关联关系。 此处n取值10000000。
- 约束:①最多1MB的内存空间可用;②磁盘空间充足;③运行时间最多几分钟, 最好是线性时间。
- 输出:按升序排列的整数序列。
位图排序思想
针对该题的特点,由于待排序的数据记录较多,如果使用常见的排序方法效率较低,而且内存空间有限(限制为1MB左右),不能一次性将数据如内存,需从文件中多次读入,该书引入了一种新的排序方法 ---位图法。
所谓位图法,就是使用一串二进制串来表示待排序列元素集合的方法。 比如,我们知道一个byte = 8bit,表示成二进制串就是:00000000.我们可以用bit的位置[对于一个字节就是0-7,)来表示待序序列中是否出现一个数,1表示出现,0表示不出现。比如说00000010则表示待排序列包含1,因为bit 1为1。如果还不明白,继续看下面的两个例子和示图。
例如:待排序集合{3,6,0,2},由于这个序列的最大数是6,因此用一个byte就够了,因此可以分配一个只含一个元素的char数组,如char arr[1],然后看待排序列第一个元素是3,因此将数组元素的第3bit设为1,依次扫描直到待排序列的最后一个元素2,其位图可以用下图的左边表示。
那么如果待排序列的最大数不能用一个byte的最大位置表示了,比如说{3,6,0,2,8,9,10,12}了。很简单,那么就用2个字节的char数组,char arr[2],比如说待排序列中出现8,那么就将arr数组第二个元素的第0位设为1就可以了,依次类推,如下图右边所示。
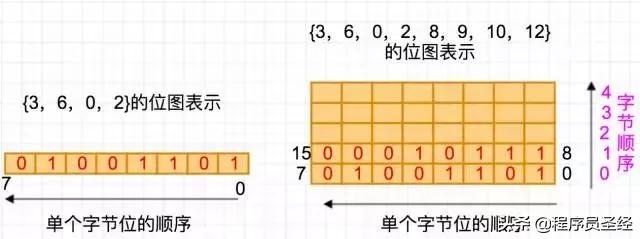
好了,现在已经根据待排序列分配好char arr[ ]数组了,也根据待排序列的数据将数组arr的相应位设置好了。最后我们要做的很简单,就是从低到高位依次扫描这个数组的每一位,如果该位为1,表示这个数在待排序列中出现过,那么打印出或者写入到输出文件中,扫描完也就得到了排序后的序列了。
根据上面所描述,不难得出位图排序的伪码如下:

位图排序实现
下面给出位图排序的实现,为了简化,这里使用了C++标准库中的bitset容器,bitset容器是C++中一种提供位集合的数据结构,我们可以像使用数组一样使用位。使用bitset很简单,不太了解的同学去网上查查相关的资料很快就会用的,下面就是位图排序的C++实现。
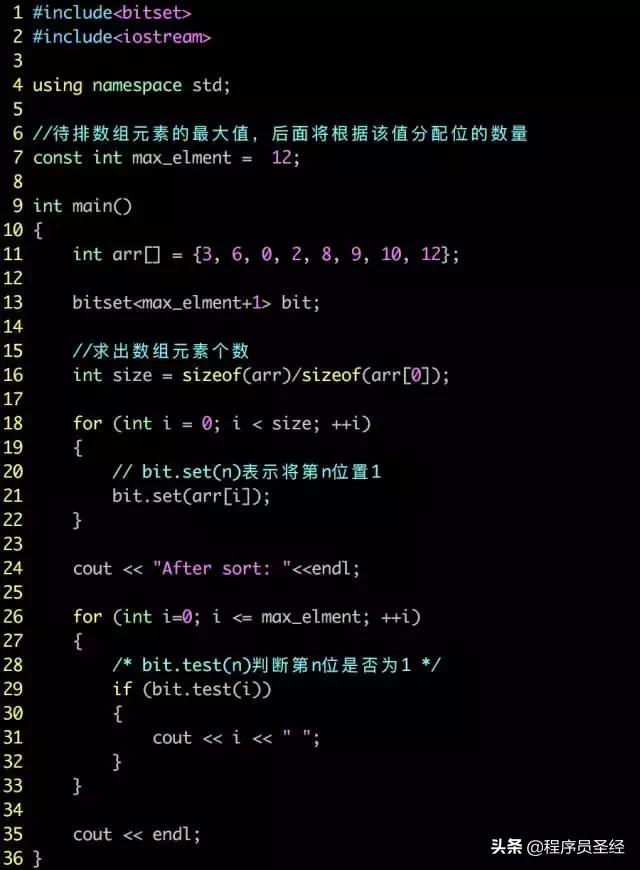

位图排序适用场景
根据位图排序的特点,不难看出位图排序的适用是有一定局限性的,也就是说位图排序只有在一定的场景下使用效果才最好,如下所示。
- 需要知道待排序序列中的最大数,因为位图排序时需根据该值来分配数组空间。
- 位图排序比较适合元素密集的序列,因为在位图排序中,有些数没有出现过,仍要为其保留一个位。如果元素稀疏,则空间浪费很多,比如说一个待排序列{1,10000000,2},总共三个元素,却要保留10000000/8个字节,是不是有点太得不偿失了。
- 待排序的元素最好不能重复。














 5177
5177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









