





过去一年里,语言模型的研究有了许多突破性的进展,BERT、XLNet、RoBERTa等预训练语言模型作为特征提取器横扫各大NLP榜单。但这些模型的参数量也相当惊人,比如BERT-base有一亿零九百万参数,BERT-large的参数量则高达三亿三千万,从而导致模型的训练及推理速度过慢。本文提出了一种“耐心的知识蒸馏” (Patient Knowledge Distillation) 方法对模型进行压缩,PKD方法重新定义损失函数,使student模型的隐藏层表示更接近teacher模型的隐藏层表示,从而让student模型的泛化能力更强,在不损失太多精度的情况下,减小模型规模及推理时间。

研究者将提出的BERT-PKD模型与BERT模型微调 (fine-tuning) 和基线知识蒸馏模型在7个句子分类的基准数据集上比较,在12层teacher模型蒸馏到6层或者3层student模型的时候,绝大部分情况下PKD模型表现都优于两种基线模型。并且在五个数据集上SST-2 (相比于teacher模型-2.3%准确率),QQP (-0.1%),MNLI-m (-2.2%),MNLI-mm (-1.8%),and QNLI (-1.4%) 的表现接近于teacher模型。论文地址:https://arxiv.org/abs/1908.09355
引言
过去一年里,语言模型的研究有了许多突破性的进展,BERT、XLNet、RoBERTa等预训练语言模型作为特征提取器横扫各大NLP榜单。但这些模型的参数量也相当惊人,比如BERT-base有一亿零九百万参数,BERT-large的参数量则高达三亿三千万,从而导致模型的训练及推理速度过慢。本文提出了一种“耐心的知识蒸馏” (Patient Knowledge Distillation) 方法对模型进行压缩,PKD方法重新定义损失函数,使student模型的隐藏层表示更接近teacher模型的隐藏层表示,从而让student模型的泛化能力更强,在不损失太多精度的情况下,减小模型规模及推理时间。
具体来说,对于句子分类类型的任务,当普通的知识蒸馏模型用来对模型进行压缩的时候,通常带来较大精度损失。究其原因,student模型 (student model) 在学习的时候只是学到了teacher模型 (teacher model) 最终预测的概率分布,而忽略了中间隐藏层表示的学习。就像老师在教学生的时候,学生只记住了最终的答案,但是对于中间的过程却完全没有学习。这样在遇到新问题的时候,student模型犯错误的概率更高。BERT-PKD模型重新定义损失函数,使student模型的隐藏层表示接近teacher模型的隐藏层表示,从而让student模型的泛化能力更强。
模型
论文所提出的多层蒸馏,即student模型除了学习teacher模型的概率输出之外,还要学习一些中间层的输出。论文提出了两种方法,第一种是skip模式,即每隔几层去学习一个中间层,第二种是last模式,即学习teacher模型的最后几层。
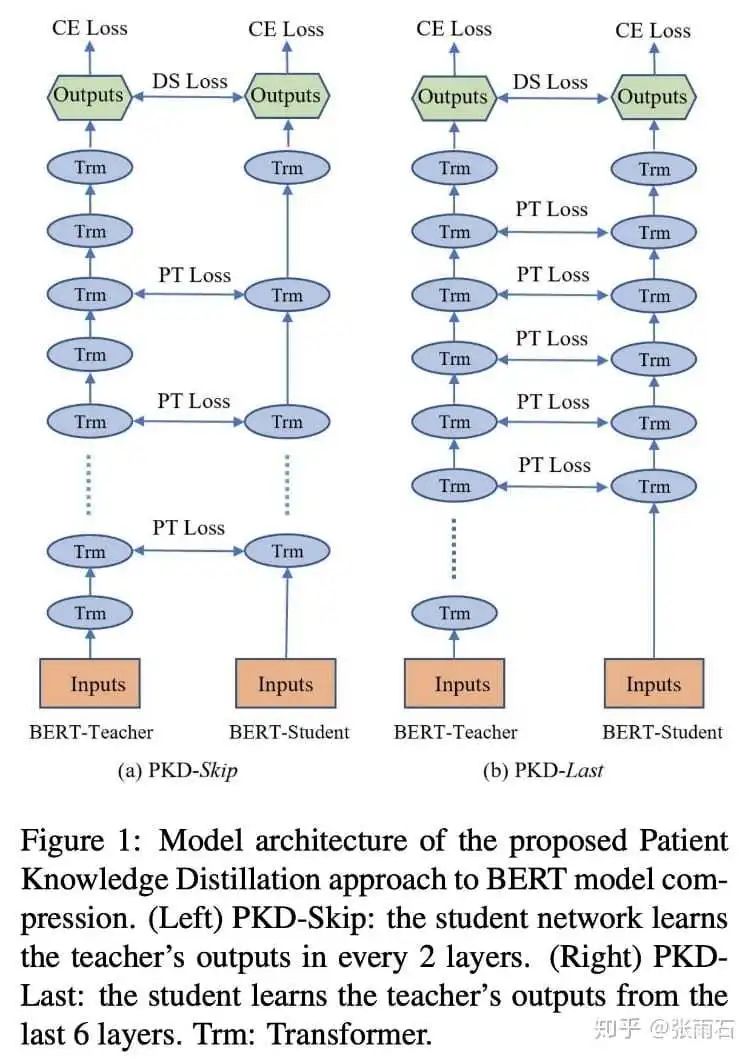
对于最初的知识蒸馏方法,student模型使用交叉熵函数尽量拟合teacher模型的概率输出,同时student模型还需要学习ground truth,然后再让两个损失去做加权平均。
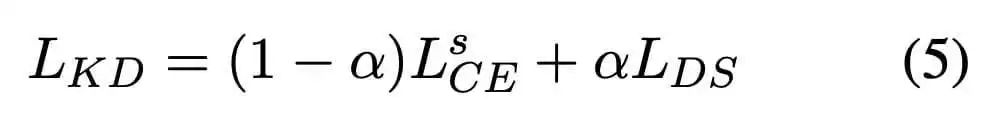
而PKD模型增加模型中间层的学习,同时为避免中间层学习计算量过大,让student模型仅学习[CLS]字符的中间层输出,使得模型能够同时学到[CLS]字符的各层的特征表示,对于中间层的学习,使用的损失函数是均方差函数。
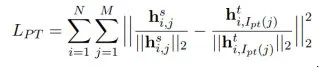
数据集
为了验证BERT-PKD的效果,本文在多个任务上将其与其他模型进行了比较。
实验结果
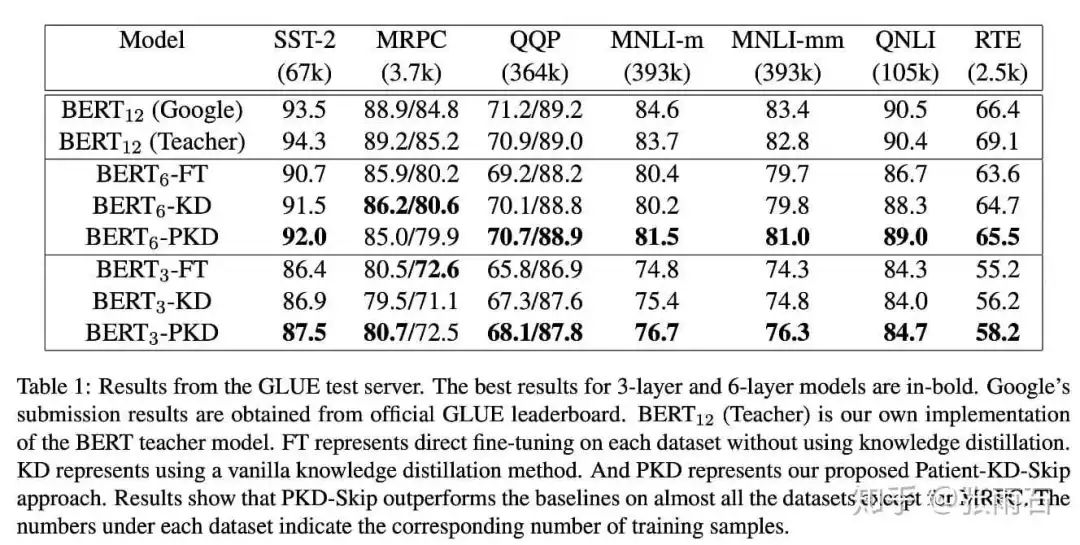
BERT-PKD模型、BERT模型微调 (fine-tuning) 和基线知识蒸馏模型在7个句子分类的基准数据集上比较如下表所示,在12层teacher模型蒸馏到6层或者3层student模型的时候,大部分情况下PKD的表现都优于同等规模的基线模型。并且在五个数据集上SST-2 (相比于teacher模型-2.3%准确率),QQP (-0.1%),MNLI-m (-2.2%),MNLI-mm (-1.8%),and QNLI (-1.4%) 的表现接近于teacher模型。这进一步验证了研究者的假设,学习了隐藏层表示的student模型优于只学模型预测概率的student模型。同时,student模型在MRPC任务上的表现较差,究其原因,可能是因为MRPC的数据较少,从而导致了过拟合。
BERT-PKD模型Last模式和Skip模式的对比如下表所示,Skip模式一般优于last模式。Skip模式下,层次之间的距离较远,从而让student学习到各种层次的信息。

student模型的计算量和参数数目如下表所示。在速度方面,6层BERT-PKD模型可将推理 (inference) 速度提高两倍,总参数量减少1.64倍;而三层BERT-PKD模型可以提速3.73倍,总参数量减少2.4倍。PKD模型由于需每层计算损失,student模型和teacher模型隐藏层的宽度(隐藏层的向量维度)相同,这其实对于模型是一个限制,student模型的参数量主要在层数的减少。

结论
本文提出一种基于BERT的知识蒸馏模型BERT-PKD,模型在GLUE基准大部分情况下的表现都优于同等规模的基线模型。并且在五个数据集上SST-2 (相比于teacher模型-2.3%准确率),QQP (-0.1%),MNLI-m (-2.2%),MNLI-mm (-1.8%),and QNLI (-1.4%) 的表现接近于teacher模型。同时,在速度方面,6层BERT-PKD模型可将推理 (inference) 速度提高两倍,总参数量减少1.64倍;而三层BERT-PKD模型可提速3.73倍,总参数量减少2.4倍。














 1157
1157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









