





本文主要会阅读bert源码(https://github.com/google-research/bert )中的optimization.py文件,已完成modeling.py、run_pretraining.py文件的源码阅读,后续会陆续阅读bert的数据准备、下游任务训练等源码等。本文大体以优化算法中各个概念为基础介绍optimization.py,先后介绍了学习率的衰减、学习率预热、权重衰减、Adam算法,以及作者自己添加的Adam矩估计校正。
实战系列篇章中主要会分享,解决实际问题时的过程、遇到的问题或者使用的工具等等。如问题分解、bug排查、模型部署等等。相关代码实现开源在:https://github.com/wellinxu/nlp_store ,更多内容关注知乎专栏(或微信公众号):NLP杂货铺。
http://weixin.qq.com/r/RzvD24fExdq6rcO4925V (二维码自动识别)
- 学习率衰减
- 学习率预热
- 权重衰减
- Adam算法
- 矩估计校正
学习率衰减
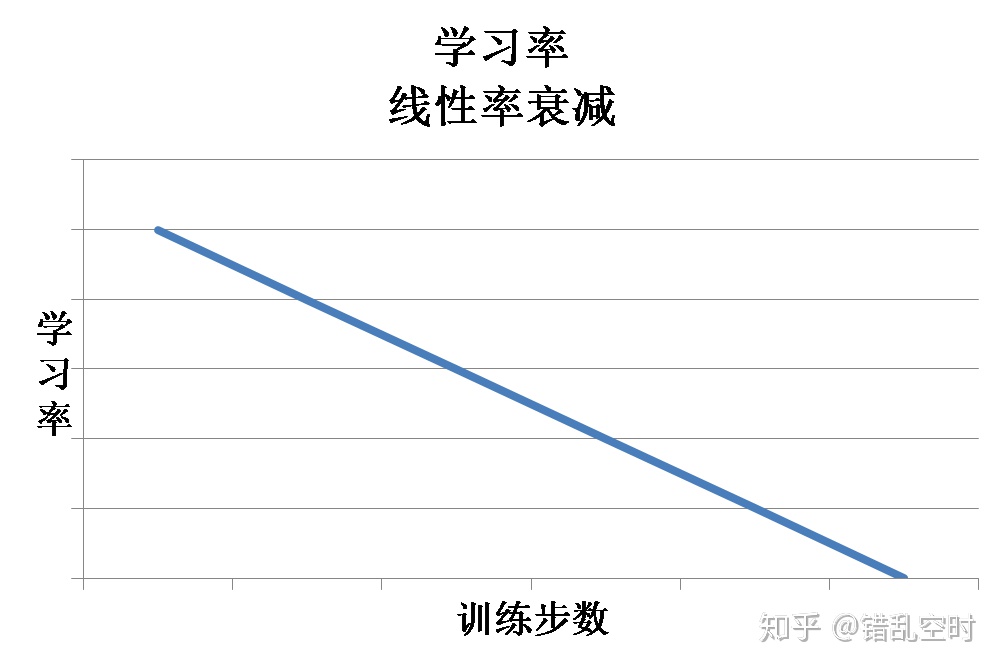
学习率在梯度下降类优化算法中有着特别重要的作用,学习率越大会使权重更新越快。大的学习率虽然能够让模型较快收敛,但也会引起模型震荡,从而错过更优解。所以通常情况下,我们希望学习率在一开始大一些,让权重快速收敛,然后再小一些,可以让模型得到一个更优的解空间。optimization.py中就使用了线性学习率衰减来达到这个目的,其中相关代码为:
# 实现学习率的线性衰减
具体公式是:
这里其实是多项式衰减,因为power等于1,所以变成线性衰减。学习率线性衰减的过程大概如下图所示:
学习率预热
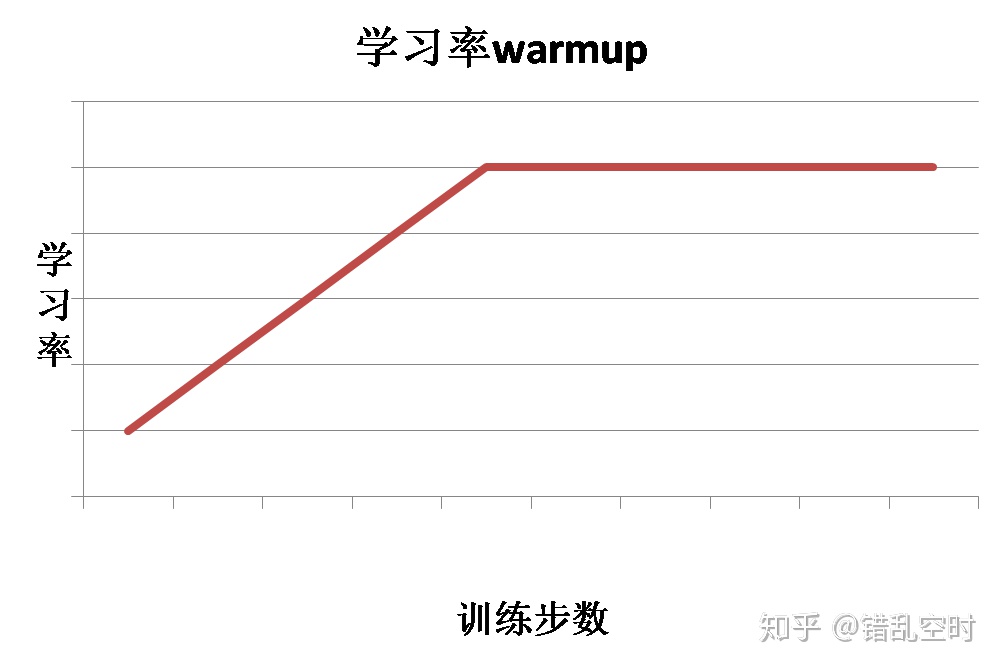
学习率预热是指在训练初期选择一个较小的学习率,然后在训练一定步数之后使用预先设置好的学习率。因为刚开始的时候模型是随机初始化权重,如果使用较大的学习率,会让模型不稳定,所以可以在一定训练步数内,使用较小的学习率,模型可以慢慢稳定,然后使用之前设定的学习率。这种情况下,学习率走势如下图所示:
具体代码如下:
# 实现线性warmup.
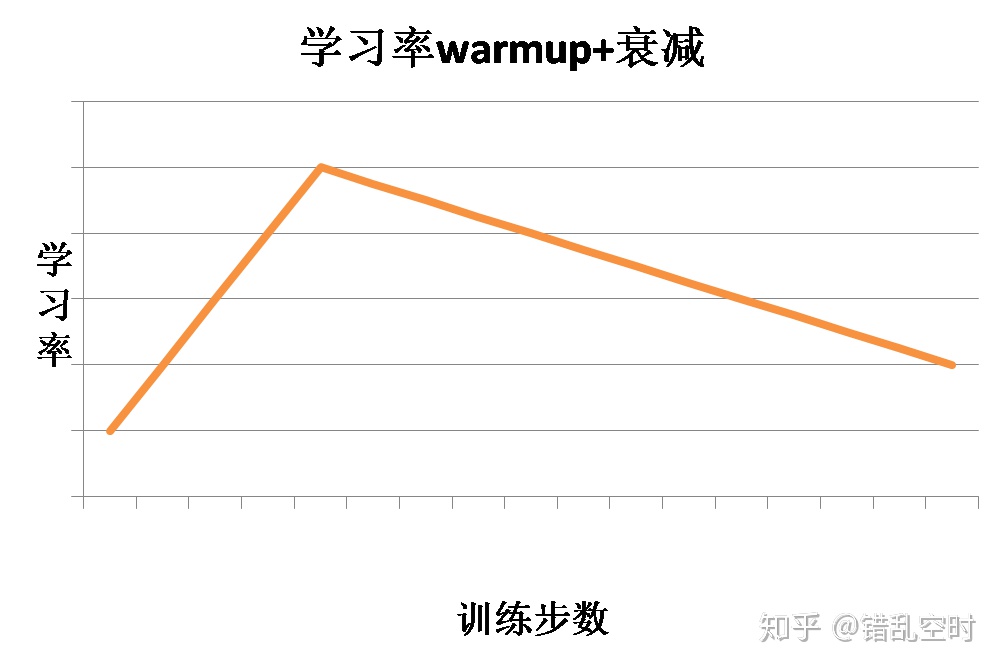
optimization.py中则是将学习率预热与衰减结合在一起使用,在一定训练步数内进行学习率预热,然后就开始学习率衰减,这样结合的效果如下图所示:
这样学习率先进过预热再进行衰减,代入Adam优化算法中,就实现了BERT的优化工作,整体代码如下所示:
def L2正则化
optimization.py中实现的Adam算法带了权重衰减(L2正则化),但是并没有直接将L2约束添加到loss函数中去,因为这样会影响Adam中梯度的一阶和二阶矩估计,所以使用了权重衰减的方式来处理,类似于在SGD中直接加上L2正则化,具体地,就是在每次权重更新时,进行一定比例的衰减,如下所示:
# 对于Adam算法来说,如果直接将权重的平方加到loss函数上,这不是正确的
当然也不是所有的参数都需要进行权重衰减的,代码中使用参数名来控制,首先使用_get_variable_name方法来获取变量名:
def 然后再使用_do_use_weight_decay方法来判断是否要进行权重衰减。
def 代码中,层标准化相关参数与偏置bias相关参数不进行权重衰减。
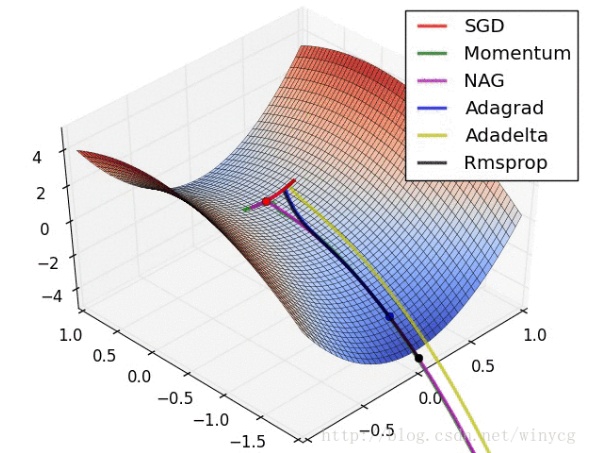
Adam算法
下图中显示了几个不同优化算法的迭代路线,Adam算法则是结合了Adagrad算法与Rmsprop算法的优点:
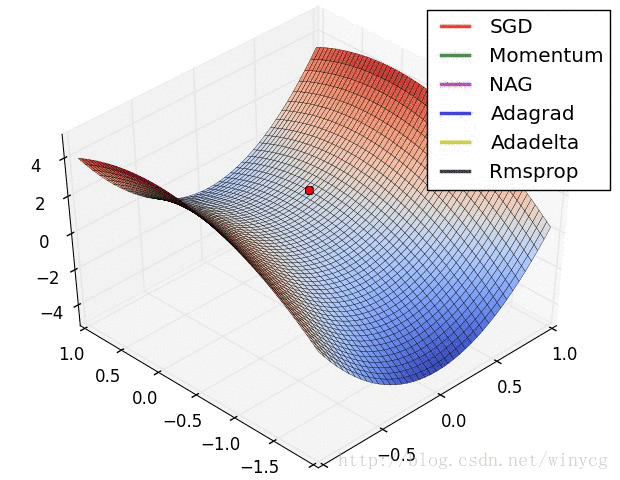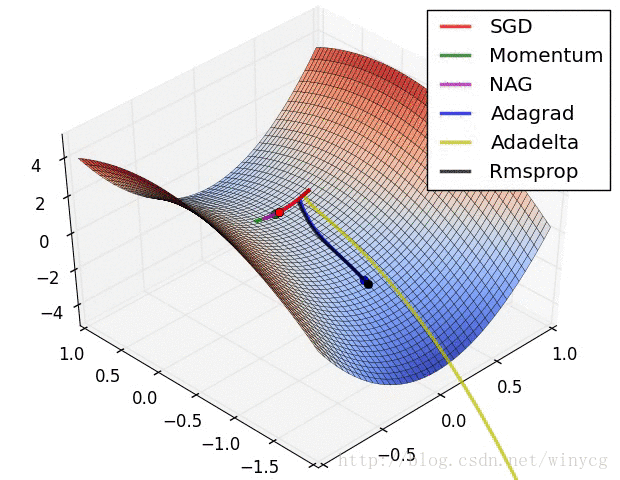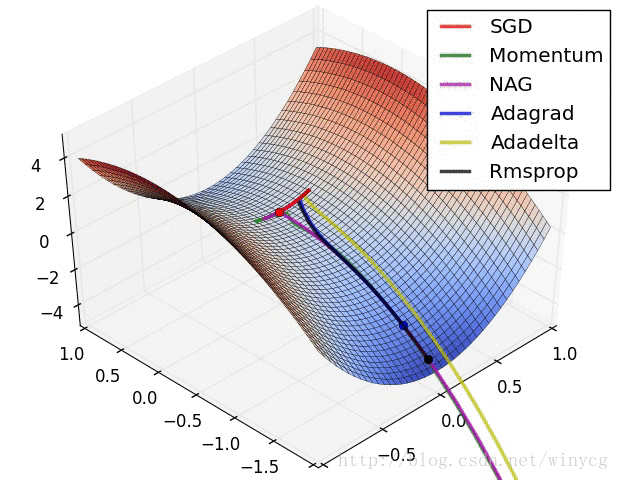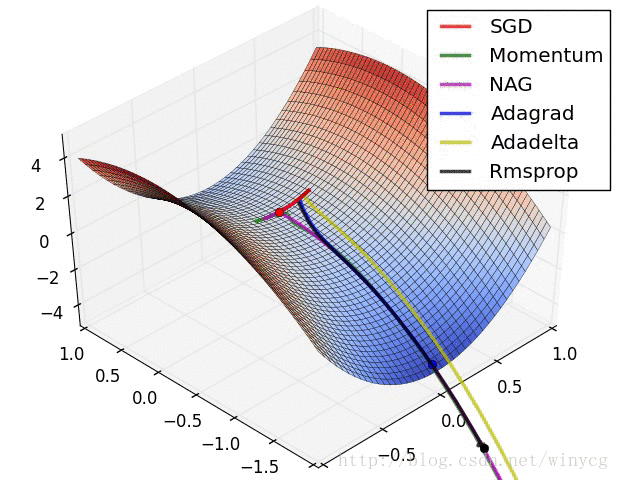
optimization.py中最核心的部分就是Adam相关算法的实现了,其具体公式如下所示:
其中gradient表示梯度计算函数,p为参数,g是p相对于loss的梯度,
所以,相关代码实现为:
class 矩估计校正
但optimization.py中实现的Adam算法并不是正宗的Adam算法,因为其一阶矩估计与二阶矩估计都没有校正,因为初始化时,
添加矩估计校正之后,相关的代码实现为:
def 













 2845
2845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









