







 Focal Loss是一种改进的交叉熵损失函数,旨在解决目标检测中正负样本不平衡的问题。该损失函数通过引入调制系数减少易分类样本的权重,使模型更关注难分类样本。适用于处理类别不平衡的数据集。
Focal Loss是一种改进的交叉熵损失函数,旨在解决目标检测中正负样本不平衡的问题。该损失函数通过引入调制系数减少易分类样本的权重,使模型更关注难分类样本。适用于处理类别不平衡的数据集。
Focal loss 出自ICCV2017 RBG和Kaiming大神的论文 Focal Loss for Dense Object Detection
对标准的交叉熵损失做了改进,效果如下图所示。
标准的交叉熵损失函数见:loss函数之NLLLoss,CrossEntropyLoss_ltochange的博客-CSDN博客_nll函数
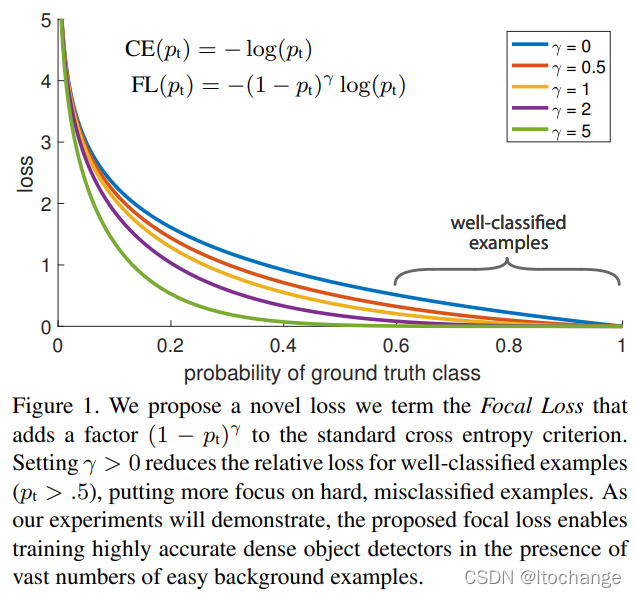
图中,横坐标为,代表样本实际类别的预测概率,
越大,代表样本越容易进行分类,纵坐标为loss。
通过引入调制系数
可减少loss中易分类样本的权重,从而使得模型在训练时更专注于难分类的样本。
具体来说:
- 当一个样本被分错的时候(难分类样本),
很小,
接近1,loss不被影响;
- 当
- 当
增加的时候,调制系数也会增加。 参数
最好。
- 直觉上来说,当
的loss要比标准的交叉熵loss小100+倍,当
时,要小1000+倍,但是对于难分类样本
,loss最多小了4倍。因此,难分类样本的权重相对就提升了很多。
Focal loss最后使用的公式为:
其中, 用于控制正负样本的权重,处理样本不均衡问题(pytorch中已有实现)。
用于控制难易样本的权重,使得模型更关注难样本。
当(向量1,维度为类别数大小),
时,即为标准交叉熵损失函数
论文实验如下图:
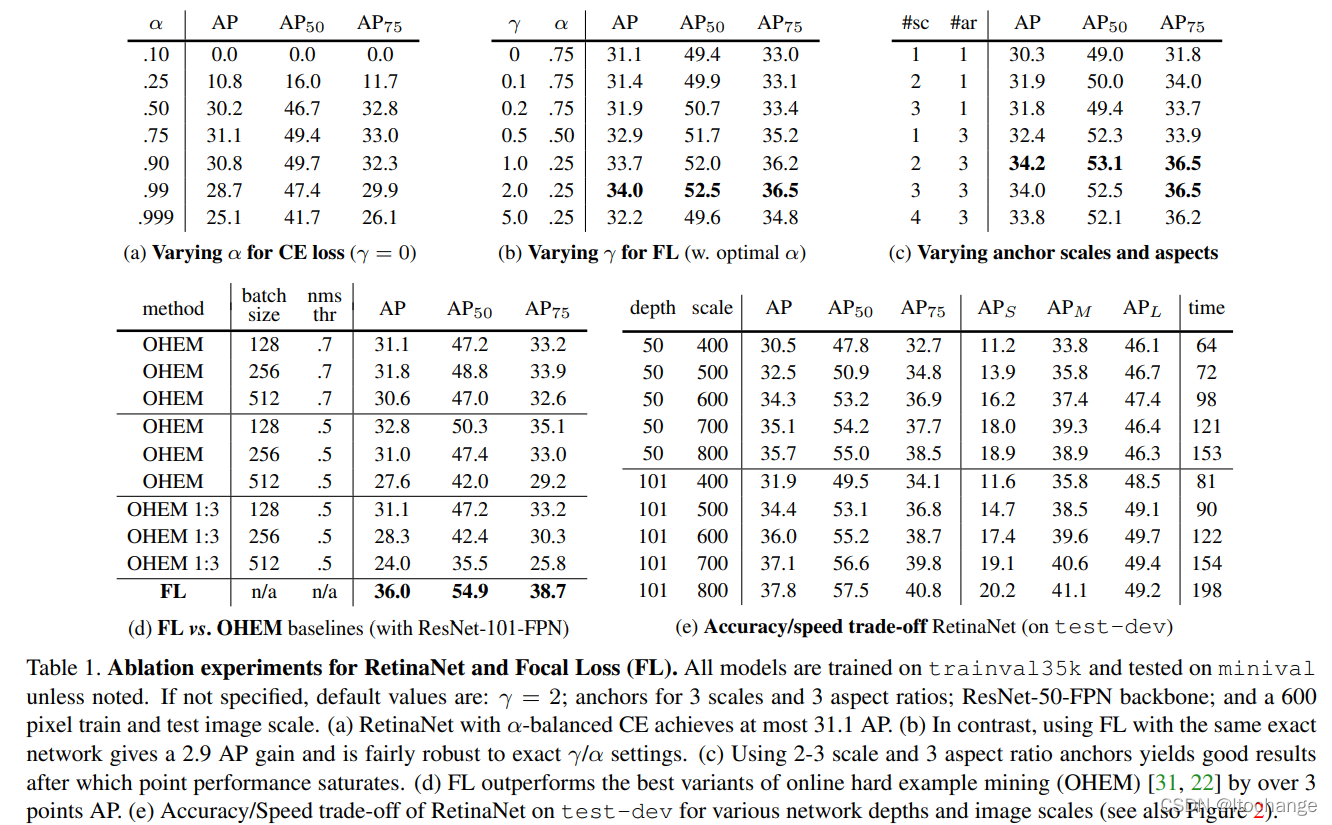
但是focal loss从公式上看只能用于二分类吧!对于多分类,例如自然语言处理中预测单词,可能是上万分类,即使模型训练得很好,尽管pt在所有概率中最大,但是和1还是相差比较多的,1-pt 一般情况下都是特别大的。这时可能用focal loss就不是很合适
后期补上代码,并在nlp领域尝试
pytorch实现(来自GitHub - lonePatient/TorchBlocks: A PyTorch-based toolkit for natural language processing:
# coding: utf-8
import torch
class FocalLoss(nn.Module):
def __init__(self, num_labels, activation_type='softmax', gamma=2.0, alpha=0.25, epsilon=1.e-9):
super(FocalLoss, self).__init__()
self.num_labels = num_labels
self.gamma = gamma
self.alpha = alpha
self.epsilon = epsilon
self.activation_type = activation_type
def forward(self, input, target):
"""
Args:
logits: model's output, shape of [batch_size, num_cls]
target: ground truth labels, shape of [batch_size]
Returns:
shape of [batch_size]
"""
if self.activation_type == 'softmax':
idx = target.view(-1, 1).long()
one_hot_key = torch.zeros(idx.size(0), self.num_labels, dtype=torch.float32, device=idx.device)
one_hot_key = one_hot_key.scatter_(1, idx, 1)
logits = torch.softmax(input, dim=-1)
loss = -self.alpha * one_hot_key * torch.pow((1 - logits), self.gamma) * (logits + self.epsilon).log()
loss = loss.sum(1)
elif self.activation_type == 'sigmoid':
multi_hot_key = target
logits = torch.sigmoid(input)
zero_hot_key = 1 - multi_hot_key
loss = -self.alpha * multi_hot_key * torch.pow((1 - logits), self.gamma) * (logits + self.epsilon).log()
loss += -(1 - self.alpha) * zero_hot_key * torch.pow(logits, self.gamma) * (1 - logits + self.epsilon).log()
return loss.mean()
参考:


















 2055
2055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











