






 本文介绍了如何使用Web Scraper插件爬取网页图片,包括尝试使用旧版插件和结合Python的方法。详细步骤包括设置sitemap、选择器、延迟加载以及数据导出和使用Python脚本下载图片。
本文介绍了如何使用Web Scraper插件爬取网页图片,包括尝试使用旧版插件和结合Python的方法。详细步骤包括设置sitemap、选择器、延迟加载以及数据导出和使用Python脚本下载图片。

最近在倒腾Web Scraper的玩法,爬爬知乎,看看微博之类的,几天体验下来,Web Scraper作为一个轻量级的爬虫插件,能够免除写代码的过程,只需要动动鼠标就能爬取简单的页面数据,在日常生活和学习中使用是完全够了。
唯一不太好的地方就是没办法直接抓取图片,每次在浏览到漂亮小姐姐的时候都无从下手,搞得我很是难受

我又不想写代码,于是我就谷歌找找有没有解决方案,终于功夫不负有心人,下面我就来介绍一下如何解决Web Scraper爬图片的问题:
1,重装
第一种解决方案就是下回旧版,旧版的Web scraper在image的选项下面是有下载图片的选项的,新版的是没有的。
我嫌重装太麻烦了,也就没有实战截图,大家如果想直接重装的话就自己下来用吧
百度云密码:f81upan.baidu.com2,Python加Web scraper
第二种方式需要装有Python,下面用知乎演示一下:
- 先找到要爬取的漂亮小姐姐的网站
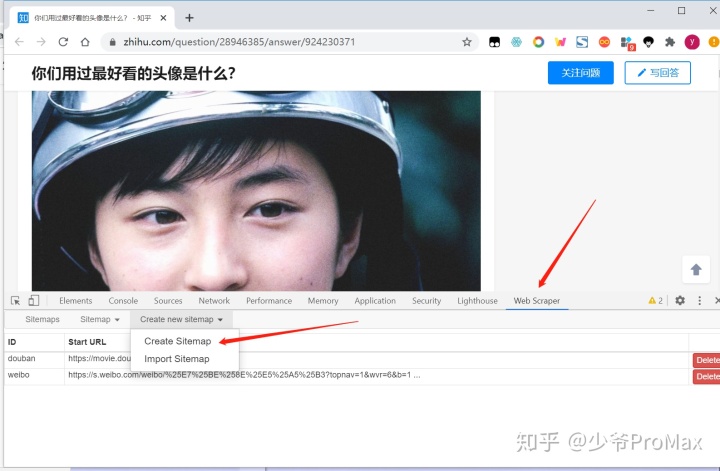
- 按F12打开Web scraper,新建一个sitemap
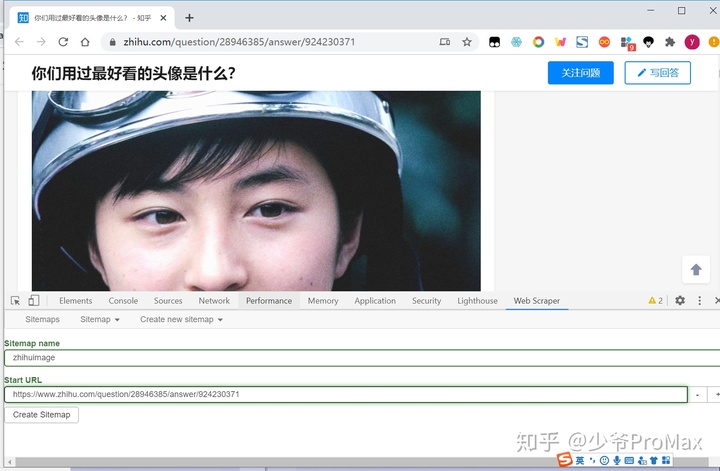
- 第一行随便输入一个名字,将要爬取的网址复制到第二行,点击create sitemap
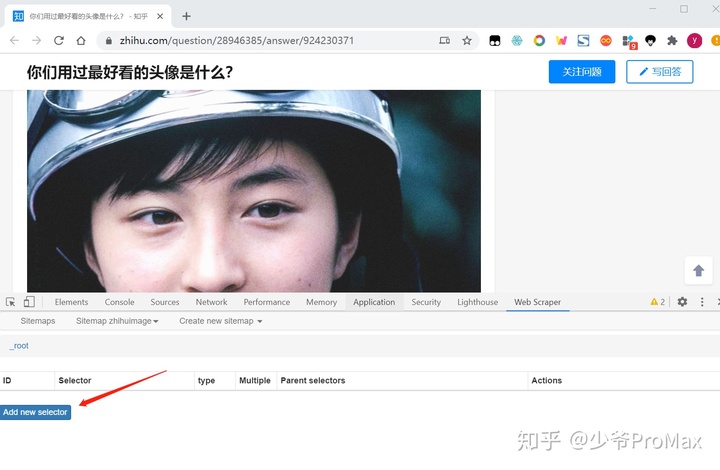
- 点击add new selector
- ID栏输入选择器的名字
- Type栏选择Element scroll down
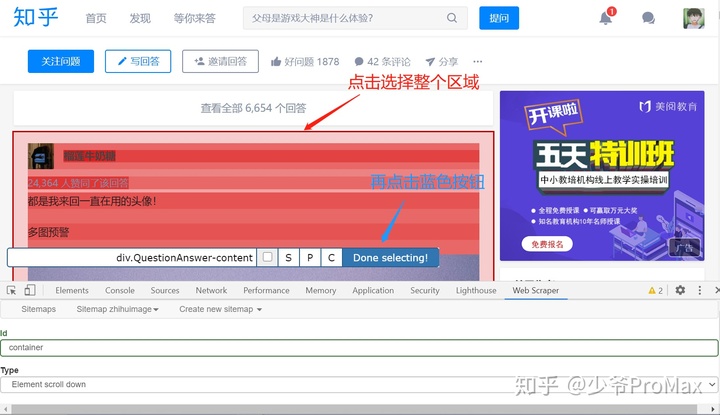
- 点击Select,点击下图中区域进行选择
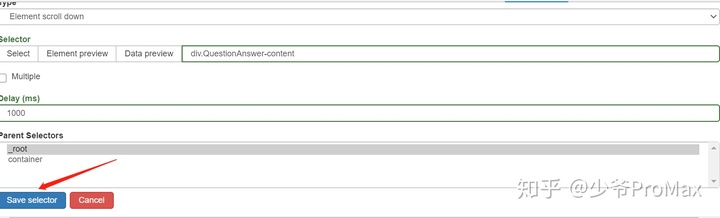
- Delay 输入1000,方便网页加载,如果网速较慢可以填2000或3000
- 最后点击save selector

- 其实上面那一步主要是为了给点网页的加载时间,毕竟图片比较多
- 再点击蓝色按钮,添加一个选择器
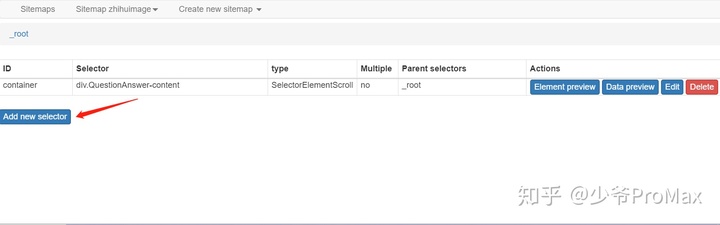
- Id输入名字
- Type选择Image
- 先点击Multiple多选,点击select后,点击选择两张图片
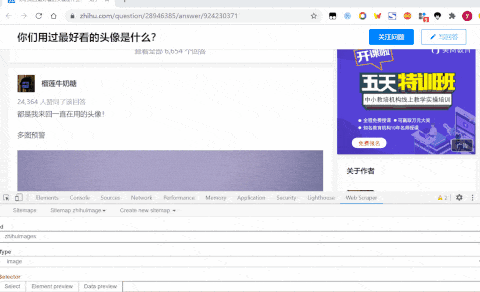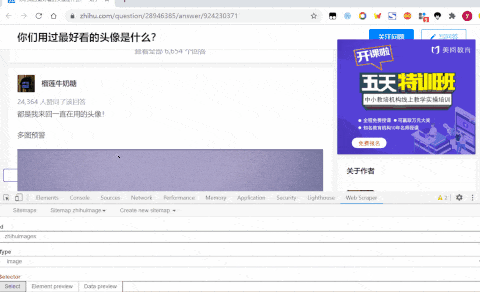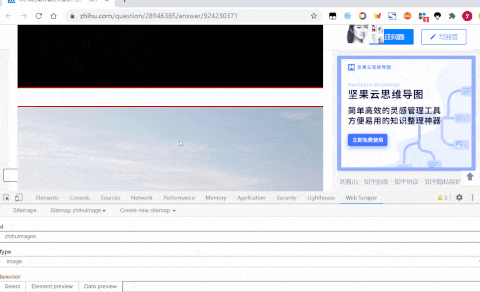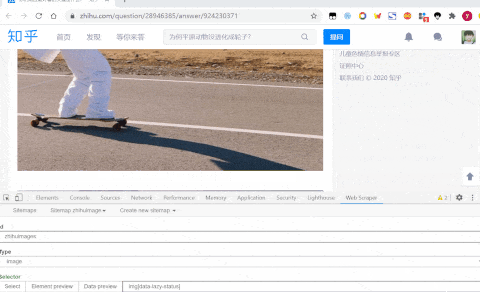
- 最后选择save selector保存
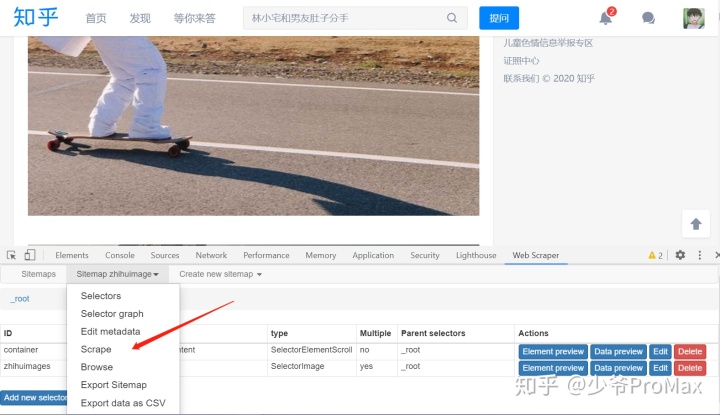
- 如下图点击Scraper,点击start,就开始爬取图片了

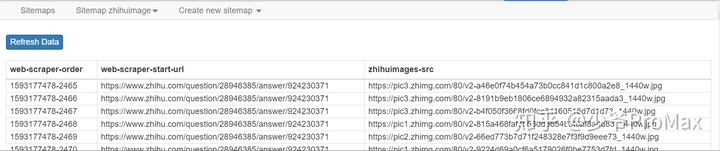
- 点击refresh可以看刚刚爬到的数据
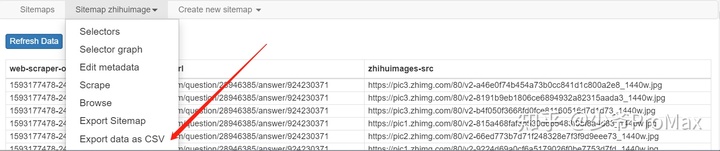
- 如下图选择Export data as CSV可以将数据下载下来
- 最后一步,
- 下载上面的文件,解压后,将刚刚下载的数据复制到解压后的文件夹中
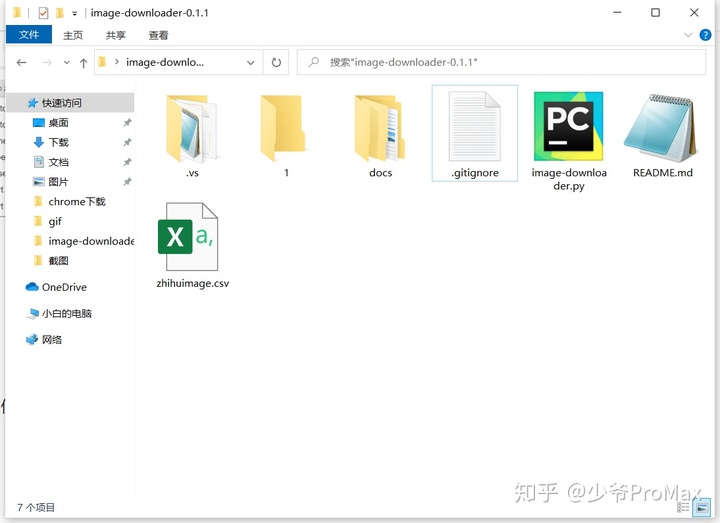
- 按住[Shift]加右键,打开powershell
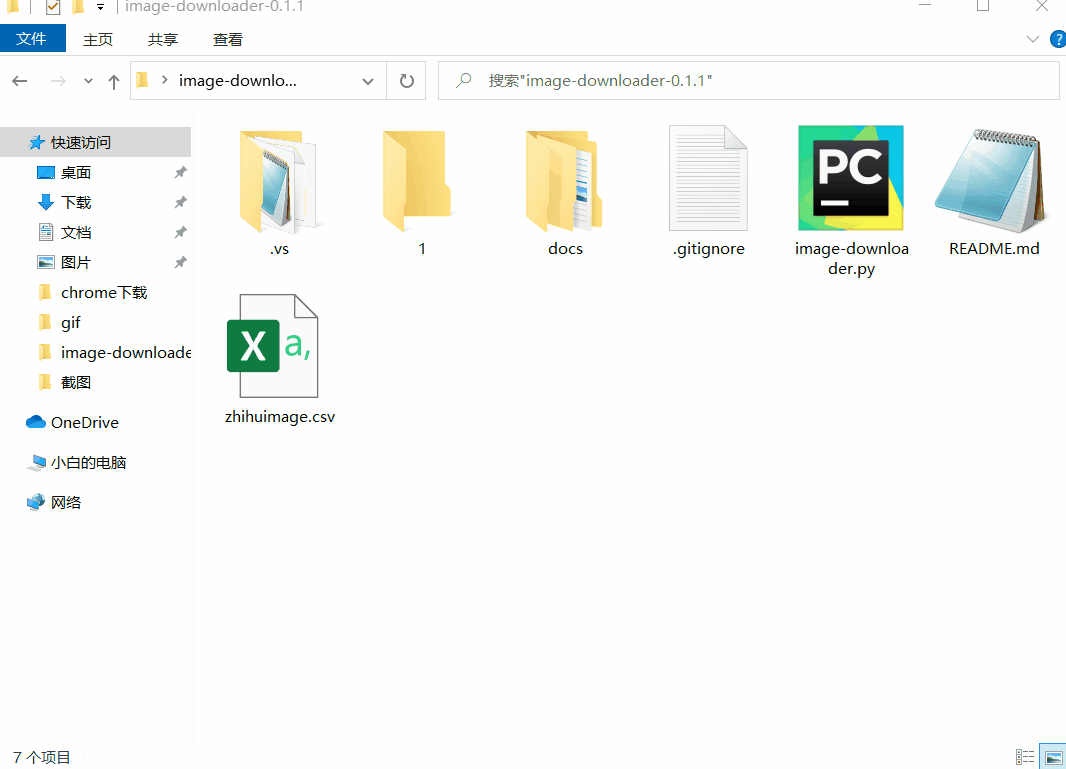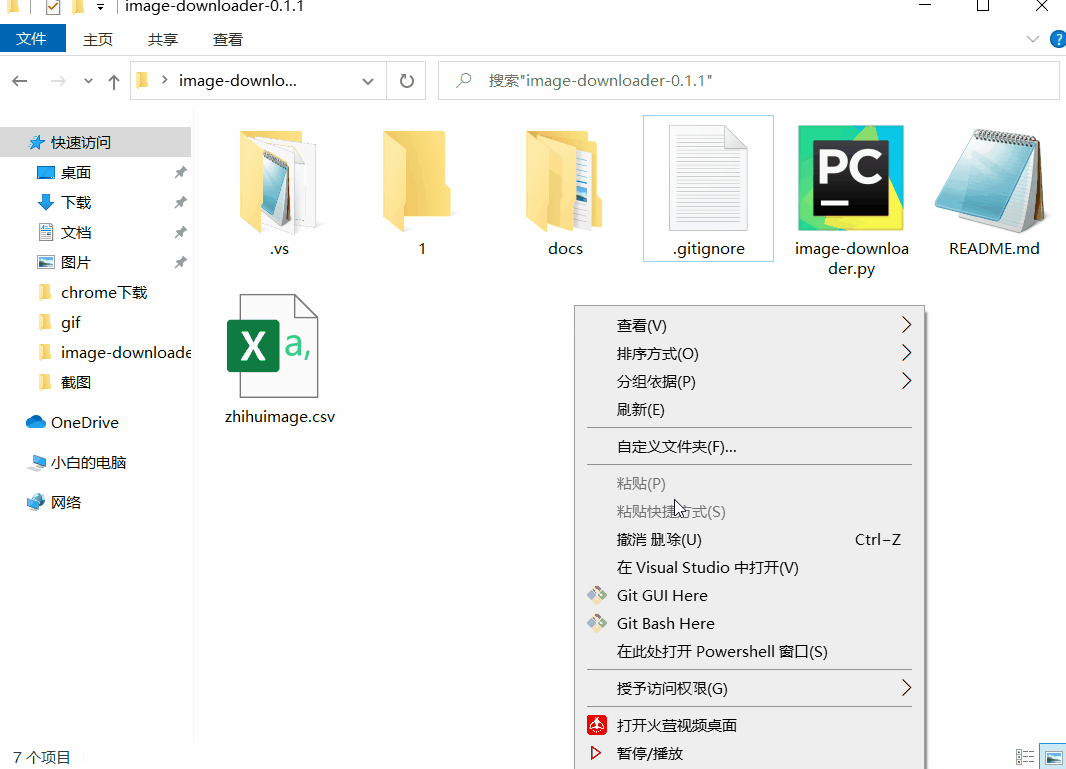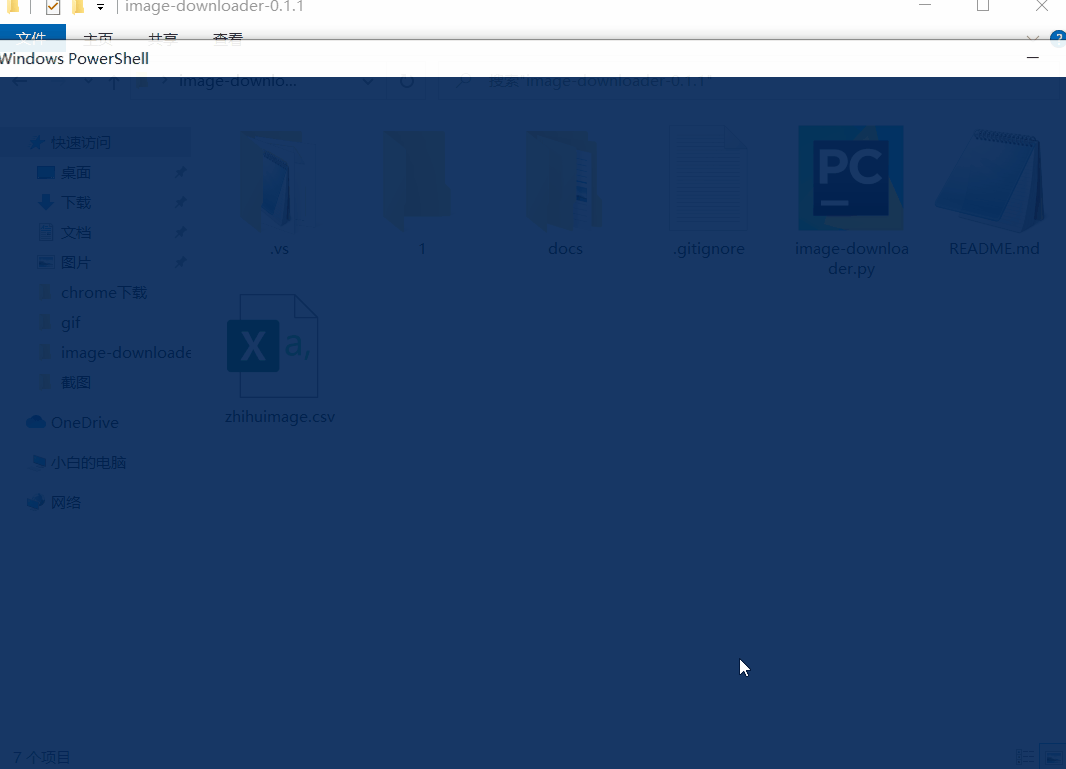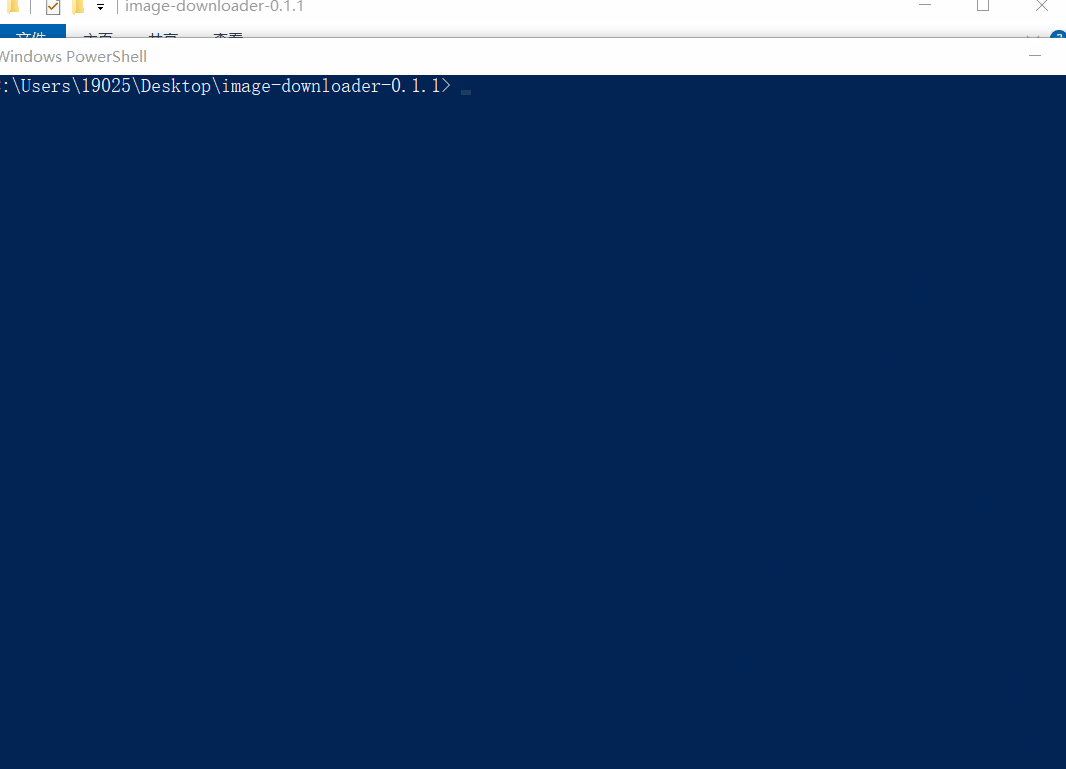
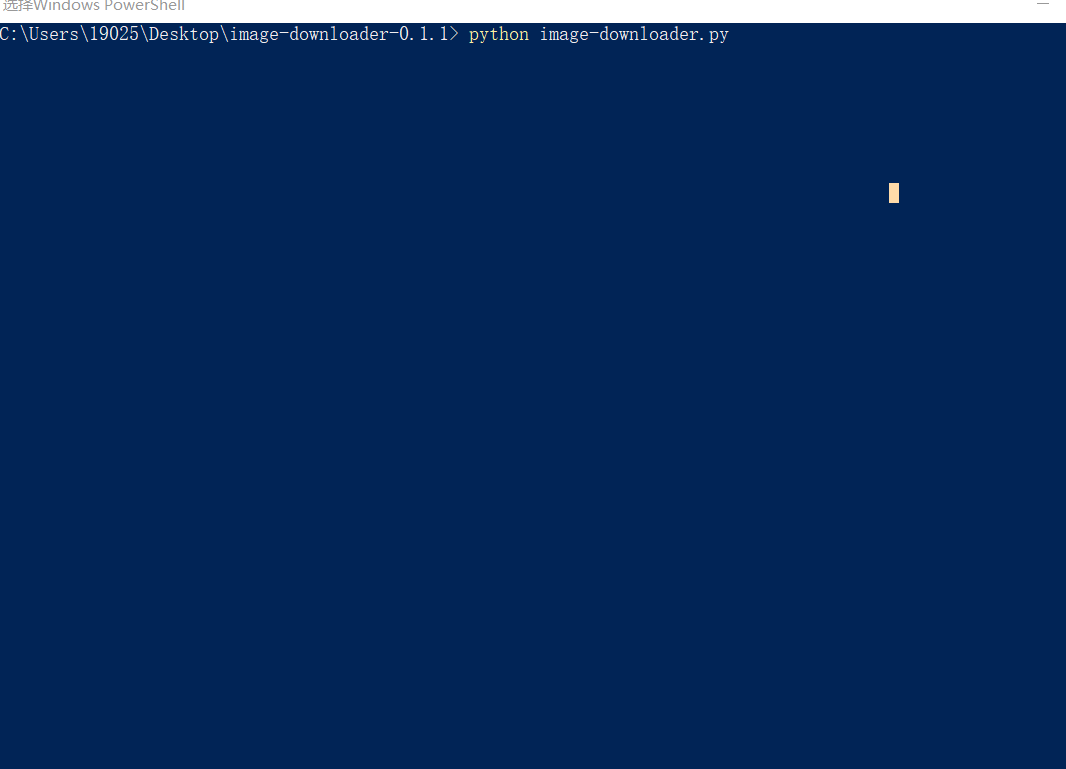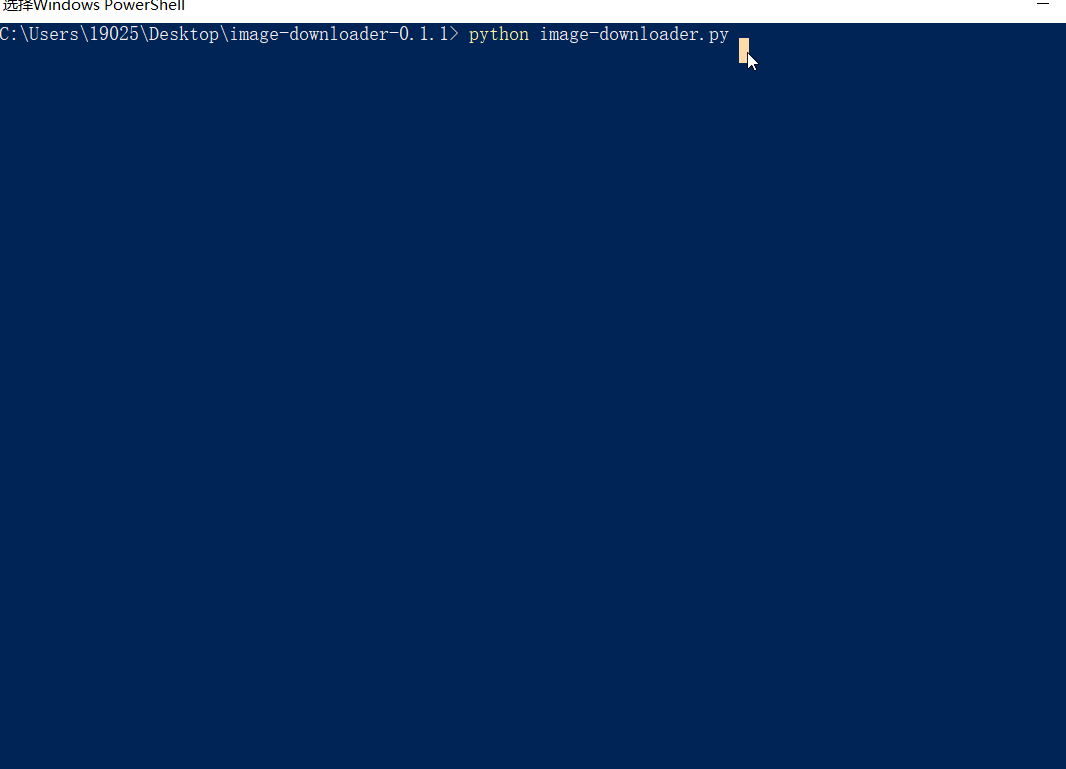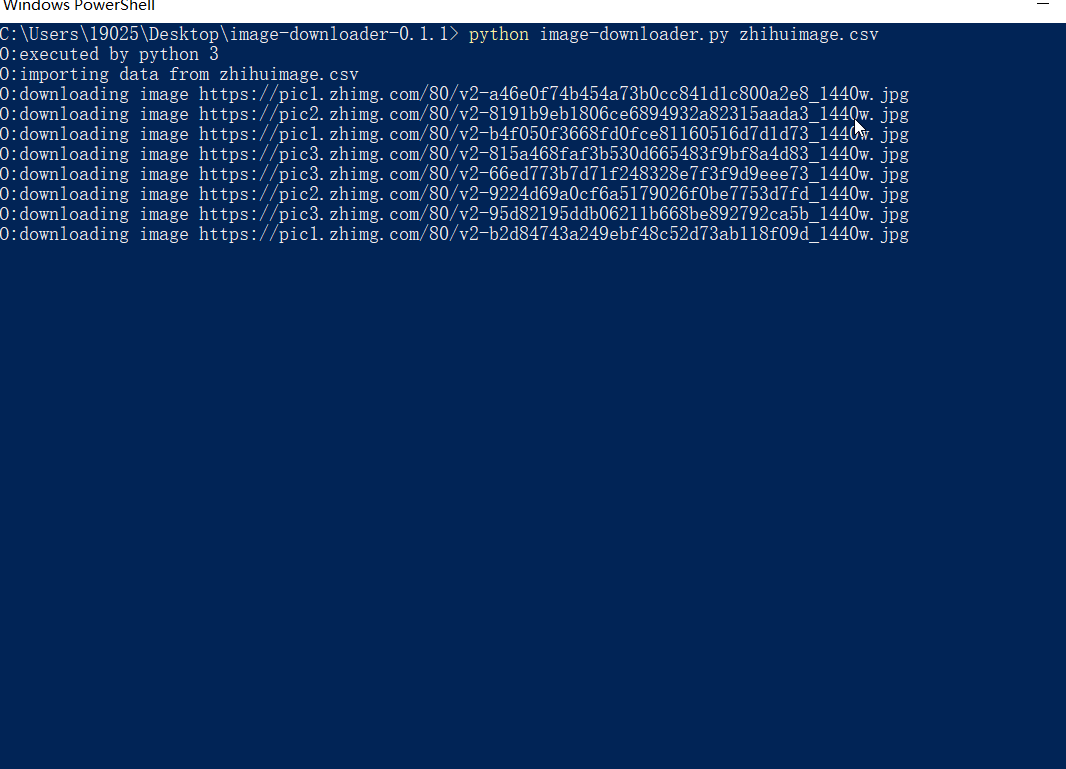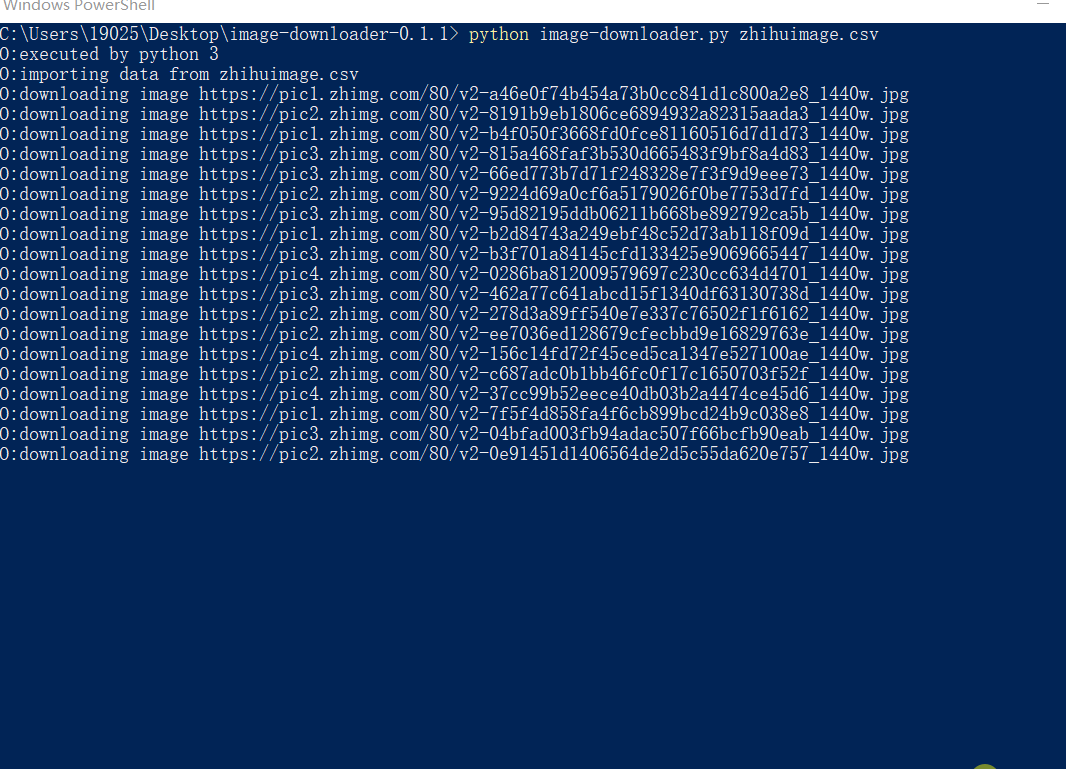
- 输入 "python image-downloader.py" + 数据文件的名字,回车就可以下载了

其实除了上面用python,你直接将图片链接复制到迅雷之类的下载工具里面也可以。

都看到这了,求点个赞不过分吧,最后祝大家牛逼!


















 8158
8158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









