





pstree
pstree - display a tree of processes , 进程树查看。
[root@localhost /]# pstree
systemd─┬─agetty
├─auditd───{auditd}
├─bash
├─crond
├─dbus-daemon
├─dnsmasq───dnsmasq
├─dockerd─┬─docker-containe─┬─docker-containe─┬─tini───exim
│ │ │ └─9*[{docker-containe}]
│ │ ├─docker-containe─┬─tini───[celery beat] r───{[celery beat] r}
│ │ │ └─11*[{docker-containe}]
│ │ ├─docker-containe─┬─memcached───9*[{memcached}]
│ │ │ └─11*[{docker-containe}]
│ │ ├─docker-containe─┬─tini───uwsgi─┬─2*[uwsgi───3*[{uwsgi}]]
│ │ │ │ ├─uwsgi───4*[{uwsgi}]
│ │ │ │ └─uwsgi
│ │ │ └─10*[{docker-containe}]
│ │ ├─docker-containe─┬─tini───[celeryd: celer─┬─4*[[celeryd: celer───{[celeryd: celer}]
│ │ │ │ └─{[celeryd: celer}
│ │ │ └─9*[{docker-containe}]
│ │ ├─docker-containe─┬─redis-server───2*[{redis-server}]
│ │ │ └─10*[{docker-containe}]
│ │ ├─docker-containe─┬─postgres───9*[postgres]
│ │ │ └─9*[{docker-containe}]
│ │ └─40*[{docker-containe}]
│ ├─docker-proxy───6*[{docker-proxy}]
│ └─55*[{dockerd}]
ps
ps命令用于报告当前系统的进程状态。可以搭配kill指令随时中断、删除不必要的程序。ps命令是最基本同时也是非常强大的进程查看命令,使用该命令可以确定有哪些进程正在运行和运行的状态、进程是否结束、进程有没有僵死、哪些进程占用了过多的资源等等,总之大部分信息都是可以通过执行该命令得到的。
- 语法
ps (选项)- 常用选项
-a: 与终端相关的进程
-x: 与终端无关的进程
-u: 以用户为中心组织进程状态信息显示
aux:常用组合
-e: 显示所有进程
-f: 显示完整格式的进程信息
-e: 显示完整格式的所有进程信息
-F: 显示完整格式的进程信息
-H: 以进程层级格式显示进程信息
efH:常用组合
-eo:以指定的格式显示进程信息(-eo pid,tid,class,rtprio,ni,pri,psr,pcpu,stat,wchan:14,comm)
axo:axo(stat,euid,ruid,tty,tpgid,sess,pgrp,ppid,pid,pcpu,comm)- 进程显示各参数说明
[root@localhost 1]# ps -aux | head -1
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND| 各参数解释如下:
USER: 进程属主
PID: 进程id号
CPU: 该进程使用CPU占比
%MEM: 该进程使用内存占比
VSZ(Virtual Memory Size) : 虚拟内存集
RSS(ReSident Size) :常驻内存集
TTY: 进程启用的终端
TAT: 进程状态
ni: nice值
pri: priority-优先级
psr: processor-处理器
rtprio: 实时优先级- 进程状态
R: running-运行态
S: interruptable sleeping-可中断睡眠状态
D: uninterruptal sleeping-不可中断睡眠状态
T: stopped-停止态
Z: zombie-僵死态
+: 前台进程
1: 多线程进程
N: 低优先级进程
<: 高优先级进程 pgrep
pgrep命令以名称为依据从运行进程队列中查找进程,并显示查找到的进程id。每一个进程ID以一个十进制数表示,通过一个分割字符串和下一个ID分开,默认的分割字符串是一个新行。对于每个属性选项,用户可以在命令行上指定一个以逗号分割的可能值的集合。
- 语法
pgrep(选项)(参数)- 参数
-o:仅显示找到的最小(起始)进程号;
-n:仅显示找到的最大(结束)进程号;
-l:显示进程名称;
-P:指定父进程号;
-g:指定进程组;
-t:指定开启进程的终端;
-u:指定进程的有效用户ID。- 参数
进程名称:指定要查找的进程名称,同时也支持类似grep指令中的匹配模式。
- 示例
pgrep -lo httpd
4557 httpd
[root@localhost ~]# pgrep -ln httpd
4566 httpd
[root@localhost ~]# pgrep -l httpd
4557 httpd
4560 httpd
4561 httpd
4562 httpd
4563 httpd
4564 httpd
4565 httpd
4566 httpd
[root@localhost ~]# pgrep httpd
4557
4560
4561
4562
4563
4564
4565
4566pkill
pkill命令可以按照进程名杀死进程。pkill和killall应用方法差不多,也是直接杀死运行中的程序;如果您想杀掉单个进程,请用kill来杀掉。
- 语法
pkill(选项)(参数)- 选项
-o:仅向找到的最小(起始)进程号发送信号;
-n:仅向找到的最大(结束)进程号发送信号;
-P:指定父进程号发送信号;
-g:指定进程组;
-t:指定开启进程的终端。- 参数
进程名称:指定要查找的进程名称,同时也支持类似grep指令中的匹配模式。
- 示例
pgrep -l gaim
2979 gaim
pkill gaimvmstat
vmstat命令的含义为显示虚拟内存状态(“Virtual Memory Statistics”),但是它可以报告关于进程、内存、I/O等系统整体运行状态。
- 语法
vmstat (选项) (参数)- 选项
-a:显示活动内页
-f:显示启动后创建的进程总数
-m:显示slab信息
-n:头信息仅显示一次
-s:以表格方式显示事件计数器和内存状态
-d:报告磁盘状态
-p:显示指定的硬盘分区状态
-S:输出信息的单位- 参数
事件间隔:状态信息刷新的时间间隔;
次数:显示报告的次数。
[root@localhost 1]# vmstat 3 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 308992 128716 68 337964 2 14 174 47 61 45 0 0 100 0 0
0 0 308992 128724 68 337964 0 0 0 0 143 128 0 0 100 0 0- 字段说明
(1) Procs(进程)
r: 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1)
b: 等待IO的进程数量。
(2) Memory(内存)
swpd: 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。
free: 空闲物理内存大小。
buff: 用作缓冲的内存大小。
cache: 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。
(3) Swap
si: 每秒从交换区写到内存的大小,由磁盘调入内存。
so: 每秒写入交换区的内存大小,由内存调入磁盘。
注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。
(4) IO(现在的Linux版本块的大小为1kb)
bi: 每秒读取的块数
bo: 每秒写入的块数
注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。
(5) system(系统)
in: 每秒中断数,包括时钟中断。
cs: 每秒上下文切换数。
注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。
(6) CPU(以百分比表示)
us: 用户进程执行时间百分比(user time)
us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。
sy: 内核系统进程执行时间百分比(system time)
sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。
wa: IO等待时间百分比
wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。
id: 空闲时间百分比- 示例
[root@localhost ~]# vmstat -a
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free inact active si so bi bo in cs us sy id wa st
1 0 306688 102568 498476 170324 1 6 70 19 47 38 0 0 100 0 0
[root@localhost ~]# vmstat -f
7565 forks
[root@localhost ~]# vmstat -m
Cache Num Total Size Pages
isofs_inode_cache 153 153 640 51
fuse_request 80 80 400 40
fuse_inode 42 42 768 42
nf_conntrack_ffff9302b74c0000 0 0 320 51
nf_conntrack_ffffffffb0cfc900 204 204 320 51
rpc_inode_cache 51 51 640 51
...
[root@localhost ~]# vmstat -d
disk- ------------reads------------ ------------writes----------- -----IO------
total merged sectors ms total merged sectors ms cur sec
sda 62476 12425 8109275 59592 44440 80956 2191291 11455 0 23
sdb 345 0 11800 118 0 0 0 0 0 0
sr0 29 0 2100 256 0 0 0 0 0 0
dm-0 59703 0 7965200 58816 43348 0 1526779 9090 0 22
dm-1 14197 0 117280 3735 82035 0 656280 117561 0 2
dm-2 47 0 2104 23 0 0 0 0 0 0
dm-3 82 0 10464 246 4 0 4096 59 0 0
[root@localhost ~]# vmstat -w
procs -----------------------memory---------------------- ---swap-- -----io---- -system-- --------cpu--------
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 306688 102796 68 353328 1 6 68 18 47 38 0 0 100 0 0dstat
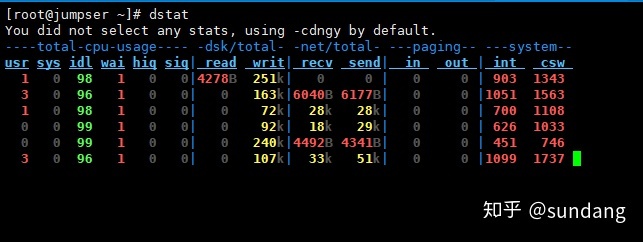
dstat命令是一个全能系统信息统计工具。拥有一个彩色的界面,在手动观察性能状况时,数据比较显眼容易观察;而且dstat支持即时刷新,譬如输入dstat 3即每三秒收集一次,但最新的数据都会每秒刷新显示。和sysstat相同的是,dstat也可以收集指定的性能资源,譬如dstat -c即显示CPU的使用情况。
直接使用dstat,默认使用的是-cdngy参数,分别显示cpu、disk、net、page、system信息,默认是1s显示一条信息。可以在最后指定显示一条信息的时间间隔,如dstat 5是没5s显示一条,dstat 5 10表示没5s显示一条,一共显示10条。
- 语法
dstat [-afv] [options..] [delay [count]]- 常用选项
-c:显示CPU系统占用,用户占用,空闲,等待,中断,软件中断等信息。
-C:当有多个CPU时候,此参数可按需分别显示cpu状态,例:-C 0,1 是显示cpu0和cpu1的信息。
-d:显示磁盘读写数据大小。
-D hda,total:include hda and total。
-n:显示网络状态。
-N eth1,total:有多块网卡时,指定要显示的网卡。
-l:显示系统负载情况。
-m:显示内存使用情况。
-g:显示页面使用情况。
-p:显示进程状态。
-s:显示交换分区使用情况。
-S:类似D/N。
-r:I/O请求情况。
-y:系统状态。
--ipc:显示ipc消息队列,信号等信息。
--socket:用来显示tcp udp端口状态。
-a:此为默认选项,等同于-cdngy。
-v:等同于 -pmgdsc -D total。
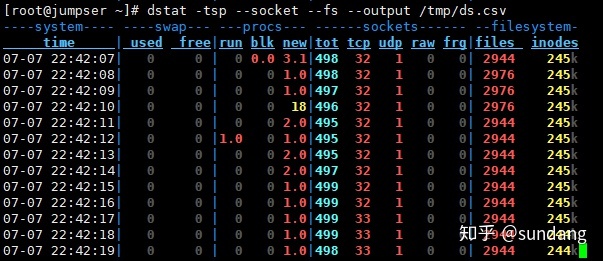
--output 文件:此选项也比较有用,可以把状态信息以csv的格式重定向到指定的文件中,以便日后查看。例:dstat --output /root/dstat.csv & 此时让程序默默的在后台运行并把结果输出到/root/dstat.csv文件中。- 实例
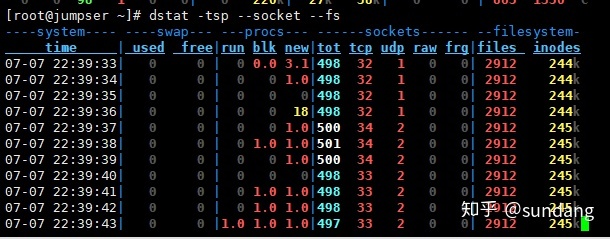
如想监控swap,process,sockets,filesystem并显示监控的时间:
将结果定向输出到文件可以加--output filename:
glances
glances- A cross-platform curses-based system monitoring tool: 一种跨平台的系统资源监控工具。
glance有许多内建命令,可以查看各部分系统资源的使用情况,一般生产中比较喜欢这款工具,一方面可视化效果做的不错,另一方面对系统资源的监控也比较全。该工具需要自行安装,这里介绍下 Centos 下的安装方法。
$ yum -y install glances 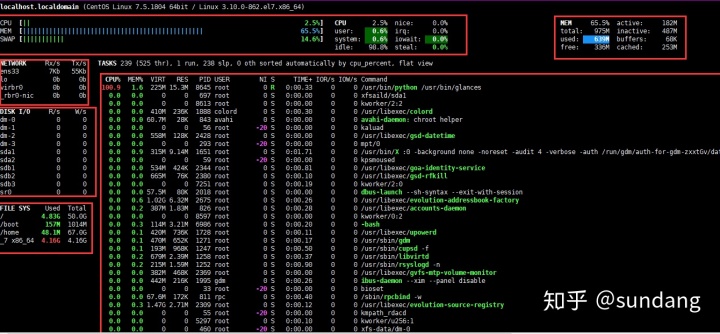
- 内建命令
a Sort process list automatically
b Switch between bit/s or Byte/s for network I/O
c Sort processes by CPU usage
d Show/hide disk I/O stats
e Enable/disable top extended stats
f Show/hide file system stats
F Switch between file system used and free space
g Generate graphs for current history
h Show/hide the help screen
i Sort processes by I/O rate
l Show/hide log messages
m Sort processes by MEM usage
n Show/hide network stats
p Sort processes by name
q Quit
r Reset history
s Show/hide sensors stats
t Sort process by CPU times (TIME+)
T View network I/O as combination
u Sort processes by USER
U View cumulative network I/O
w Delete finished warning log messages
x Delete finished warning and critical log messages
z Show/hide processes stats
z Show/hide processes list (for low CPU consumption)
0 Task's cpu usage will be divided by the total number of CPUs
1 Switch between global CPU and per-CPU stats
2 Enable/disable left sidebar
3 Enable/disable the quick look module
4 Enable/disable all but quick look and load module
/ Switch between short name/command line (processes name)
- 常用选项
-b: 以byte为单位显示网卡数据速率
-d /path/to/somefile: 设定输入文件位置
-n: 禁用网络模块
-t: 延迟时间间隔
-1: 每个CPU的相关数据单独显示总结
以上的 Linux 工具使用习惯后,对工作还是有比较大的帮助。工具比较多,适合自己的才是最好的。欢迎大家查阅评论。















 5345
5345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









