






作者:Kirill Goltsman
编译:毛十三(才云)
Kubernetes 是一个开源的容器编排工具,可用来自动化部署、扩展和运维应用容器。关于这个平台本身的各组件及具体功能,本文暂不讨论,在这里,我们将对 Kubernetes 网络的概念、架构、策略、解决方案进行探讨,就 Kubernetes 网络与普通 Docker 方法的区别及它对网络实施的要求做详细介绍。为了方便读者学以致用,文章最后提供了一个小实验,欢迎大家一起尝试。
Kubernetes 集群网络可能是 Kubernetes 基础架构中最为复杂的组件之一,它涉及很多东西(Container-to-Container 网络、Pod 网络、Service、Ingress、负载均衡器)。Kubernetes 网络真正的目标就是将容器和 Pod 转变为真正的“虚拟主机”,它们之间可以实现跨节点相互通信,同时将 VM 的优势与微服务架构、容器化相结合。
Kubernetes 网络基于几个层次,所有这些都服务于以下几个目的:
- Container-to-Container 通信(可以使用localhost和 Pod 的网络命名空间来实现)。这种网络级别使容器网络接口适用于紧密耦合的容器。这些容器可以在指定的端口上相互通信,就像传统应用程序通过localhost进行通信一样;
- Pod-to-Pod 通信,支持跨节点的 Pod 通信;
- Service,这个概念抽象定义了由其他应用程序访问 Pod 的策略(微服务);
- Ingress,负载均衡和 DNS。
通过本文你将了解到:
- Kubernetes 网络基本概念;
- Docker 网络模型概述;
- Pod 如何跨节点进行通信;
- Kubernetes 中的网络策略;
- 教程:如何在集群内部、外部限制访问 Pod。
Kubernetes 网络基本概念
Kubernetes 旨在通过创建扁平网络结构来简化集群网络。通过该结构,用户无需设置动态端口就能分配协调端口,不用设计自定义路由规则和子网,并可以使用 NAT 来跨不同网段移动数据包。为实现这一目标,Kubernetes 禁止涉及任何有意的网络分段策略的实施。换句话说,Kubernetes 旨在简化终端用户的网络架构。
Kubernetes 有以下网络规则:
- 所有容器都应该在没有 NAT 的情况下相互通信;
- 所有节点都应该与所有没有 NAT 的容器通信;
- 一个容器看到的 IP 应该与另一个容器看到的 IP 相同;
- 无论 Pod 是在哪个 Node 上,它们都应该可以相互通信。
为了帮助读者理解 Kubernetes 如何实现这些规则,本文将从 Kubernetes 网络参考的 Docker 模型开始为大家解释。
Docker 网络模型概述
Docker 支持多种网络架构,如 Overlay、Macvlan,但其默认网络解决方案是基于bridge网络驱动程序实现的 host-private 网络。
Docker 网络与任何其他的专用网络模型一样,Docker 的 host-private 网络模型基于私有 IP 地址空间,任何人都可以在未经 Internet 注册批准的情况下自由使用,但如果网络需要连接到 Internet,就必须使用 NAT 或代理服务器。host-private 网络是一种私有网络,它只存在于一个主机上,不像 multi-host 私有网络可以覆盖在多个主机上。
在这个模型的控制下,Docker的bridge驱动程序实现了以下功能:
- 首先,Docker 创建了一个虚拟网桥(docker0),并从该网桥的一个专用地址块中分配到一个子网(网桥是由多个网络或网段创建的单个合并网络设备)。就虚拟网桥而言,你可以将它类比为在虚拟网络中的物理网桥。像docker0这样的虚拟网桥是允许将 VM 或容器连接到单个虚拟网络中的。这正是 Docker 桥接驱动程序的设计目标;
- 为了将容器连接到虚拟网络中,Docker 会分配一个名为veth的虚拟以太网设备连接到网桥上。与虚拟网桥类似,veth是以太网技术的虚拟类比,该技术用于将主机连接到 LAN 或 Internet 或包上,并使用多种协议传递数据。veth可以被映射到eth0网络接口上,eth0是 Linux 的以太网接口,管理以太网设备、主机与网络之间的连接。在 Docker 中,每个容器内eth0都提供了来自网桥地址范围的 IP 地址。通过这种方式,每个容器都可以从这个范围获得自己的 IP 地址。
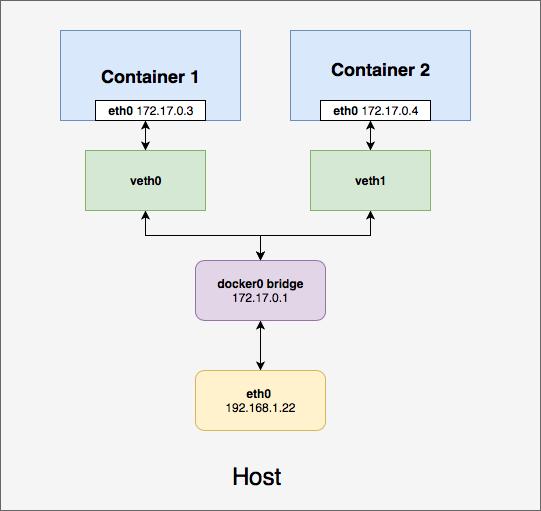
在此图中,我们看到 Container 1 和 Container 2 都是docker0网桥创建的虚拟专用网络的一部分。每个容器都有一个连接到docker0网桥的veth接口 。由于两个容器及其veth接口位于同一逻辑网络上,因此如果它们设法发现彼此的 IP 地址,则可以轻松进行通信。
但是,由于两个容器都分配了一个独特的veth,它们之间并没有共享的网络接口,这就阻碍了协调通信、容器隔离以及将它们封装在单个 Pod 中的能力。Docker 可以通过分配端口来解决此问题,然后将端口转发或代理到其他容器上。但这有一个限制,即容器需要协调端口或动态分配它们。
Kubernetes 解决方案
面对上述问题,Kubernetes 可以通过为容器提供共享网络接口来绕过上述限制。将 Kubernetes 与 Docker 模型做类比,我们可以发现 Kubernetes 允许容器共享单个veth接口。
Kubernetes 模型通过以下列方式增强了默认的 host-private 网络方法:
- 允许两个容器在veth上寻址 ;
- 允许容器通过localhost上已分配的端口进行相互访问。实际上,这与在主机上运行应用程序相同。同时,Kubernetes 模型能获得容器隔离以及紧密耦合容器架构的额外好处。
为了实现此目的,Kubernetes 为每个 Pod 创建了一个特殊的容器,并为其他容器提供网络接口。此容器以“pause”命令启动,该命令为所有容器提供虚拟网络接口,允许它们相互通信。
Pod 如何跨节点进行通信?
Kubernetes 中最令人兴奋的功能之一是即使 Pod 落在不同的节点上,Pod 中的容器也可以相互通信。默认情况下,此功能未在 Docker 中实现。在深入研究 Kubernetes 如何实现 Pod-to-Pod 网络之前,大家不妨先来了解一下,网络是如何在 Pod 级别上工作的。
Pod 可以封装容器以提供 Kubernetes 服务,如共享存储、网络接口、部署和更新。当 Kubernetes 创建一个 Pod 时,它会为其分配一个 IP 地址。该 Pod 中的所有容器可以共享这个 IP,并允许它们使用localhost相互通信。这种方式被称为“IP-per-Pod”模型。这是一个非常方便的模型,从端口分配、服务发现、负载均衡、迁移等角度来看,Pod 可以像物理主机或 VM 一样被对待。
到目前为止,这个模型真的很好用!但是,如果你希望你的 Pod 能够跨节点进行通信,这个模型就变的有些复杂了。
Kubernetes 如何解决这个问题?
Kubernetes 可以优雅解决 Pod 的跨节点通信问题。如下图所示,veth、custom bridge、eth0和连接两个节点的网关,它们现在是以网关(10.100.01)为中心的共享专用网络命名空间的一部分。这种配置意味着 Kubernetes 以某种方式设法创建了一个覆盖两个节点的独立网络。你可能还注意到,现在桥的地址根据桥所在的节点分配。
例如,10.0.1…地址空间由自定义桥接和 Node 1 的veth共享;10.0.2 ...地址空间由 Node 2 上的相同组件共享。同时,两个节点上的eth0可以共享公共网关的地址空间,使两个节点可以进行通信(10.100.0.0地址空间)。
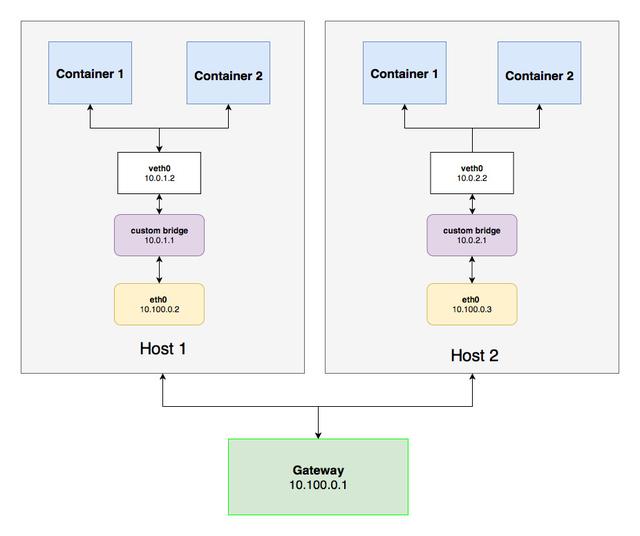
该网络的设计类似于 Overlay(简而言之,Overlay 是建立在另一个底层网络之上的网络)。Kubernetes 中的 Pod 网络是 Overlay 的一个示例,它将每个节点内的各个专用网络转换为具有共享命名空间的新软件定义网络(SDN),允许 Pod 跨节点进行通信。
Kubernetes 中的网络策略
正如前文所说,Kubernetes 网络模型允许不同节点上运行的 Pod 可以和容器进行相互通信。
容器可以通过localhost相互访问,并且 Pod 可以使用服务名称或 FQDN 访问其他 Pod(如果它们位于不同的命名空间中)。在这两种情况下,kube-dns或部署到集群的任何其他 DNS 服务都将保证正确解析 DNS,Pod 之间可以相互访问。
当你希望所有 Pod 都可以相互访问时,这种扁平网络模型非常棒。但是,在一些情况下,你可能会希望可以限制对某些 Pod 的访问。例如,你可能希望将某些 Pod “隔离”并禁止对它们进行任何访问,或限制某些 Pod 和服务的访问。在 Kubernetes 中,你可以使用NetworkPolicy资源实现此目的。
教程:如何在集群内部、外部限制访问 Pod?
读到这里,有条件的读者可以打开电脑,开始动手实践。这里有一个小实验,如果想完成它,你需要满足以下 2 个要求:
- 一个正在运行的 Kubernetes 集群(可以使用 Minikube > = 0.33.1 在本地系统上安装单节点 Kubernetes 集群);
- 安装与配置 kubectl 命令行工具。
网络策略只是一个 API 资源,它定义了一组 Pod 访问规则。但是,如果要启用这个网络策略,你就需要一个支持它的网络插件,如以下 5 种选择:
- Calico;
- Cilium;
- Kube-router;
- Romana;
- Weave Net。
如果你运行的是 Minikube,Cilium 是测试网络策略最简单的解决方案。本实验将以 Cilium 为例。
第 1 步:将 Cilium 部署到 Minikube
如果你想要部署 Cilium,你应该使用 Minikube > = 0.33.1 并通过以下参数启动:
minikube start --network-plugin=cni --memory=4096启动 Minikube 后,实验人员就需要部署 Cilium DaemonSet、CiliumRBAC以及 etcd 实例的必要配置 。
首先,找到你的 Kubernetes 版本。启动 Minikube 时,它会显示在控制台中:
minikube start --network-plugin=cni --memory=4096Starting local Kubernetes 1.13.3 cluster...如果你需要特定的 Kubernetes 版本来运行 Minikube,请使用--kubernetes-version标志和你的首选版本。
*注:使用 Kubernetes v1.8 和 v1.9 部署 Cilium 时存在一些问题,在这里查看详细信息[2]。
接下来,在 Cilium 官方的开始教程中找到对应你的 Kubernetes 版本的 YAML 清单文件,使用你的版本清单将 Cililum 部署到 Minikube 中(例如,本实验运行 Kubernetes v 1.13.0):
kubectl create -f https://raw.githubusercontent.com/cilium/cilium/1.4.0/examples/kubernetes/1.13/cilium-minikube.yamlconfigmap/cilium-config createddaemonset.apps/cilium createdclusterrolebinding.rbac.authorization.k8s.io/cilium createdclusterrole.rbac.authorization.k8s.io/cilium createdserviceaccount/cilium created将 Cilium 部署到kube-system命名空间中。要查看此 Cilium Pod 列表,你可以运行:
kubectl get pods --namespace=kube-systemNAME READY STATUS RESTARTS AGEcilium-jf7f8 0/1 Running 0 65s在生产多节点环境中,CiliumDaemonSet将在每个节点上运行一个 Pod。然后,每个 Pod 将使用 BPF 对流量实施网络策略。另外,请注意,如果你想要让 Cilium 在生产上使用,需要一个 key-value 存储(如 etcd)。
第 2 步:部署 Apache Web 服务器
接下来,你需要部署一个由网络策略管理的应用程序。你需要创建一个包含两个副本的简单 Apache HTTPD 部署,部署清单如下:
apiVersion: apps/v1kind: Deploymentmetadata: name: httpd-deployment labels: app: httpdspec: replicas: 2 selector: matchLabels: app: httpd template: metadata: labels: app: httpd spec: containers: - name: httpd image: httpd ports: - containerPort: 80创建部署:
kubectl create -f httpd.yamldeployment.apps/httpd-deployment created在部署中访问 Pod 的最佳方法是使用服务公开它们,可以用这样一个简单的单线程来做:
kubectl expose deployment httpd-deployment --port=80service/httpd-deployment exposed检查一切是否按预期工作:
kubectl get svc,podNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEservice/httpd-deployment ClusterIP 10.101.89.201 80/TCP 2m51sservice/kubernetes ClusterIP 10.96.0.1 443/TCP 18mNAME READY STATUS RESTARTS AGEpod/httpd-deployment-84d45fbd4-cxg7d 1/1 Running 0 6m39spod/httpd-deployment-84d45fbd4-vh8lz 1/1 Running 0 6m39sApache 部署和服务已准备就绪,现在可以应用NetworkPolicy了!
第 3 步:定义网络策略
在默认情况下,集群中的所有 Pod 都是非隔离的,这意味着任何其他 Pod 都可以访问它们。但是,如果实验人员将NetworkPolicy应用于特定的 Pod ,该 Pod 将拒绝使用NetworkPolicy不允许的所有连接。你可以使用以下规范定义网络策略:
apiVersion: networking.k8s.io/v1kind: NetworkPolicymetadata: name: test-np namespace: defaultspec: podSelector: matchLabels: app: httpd policyTypes: - Ingress - Egress ingress: - from: - namespaceSelector: matchLabels: project: dev - podSelector: matchLabels: role: frontend ports: - protocol: TCP port: 80 egress: - to: - ipBlock: cidr: 10.0.0.0/24 ports: - protocol: TCP port: 5978此示例与上面的清单不同,其中namespaceSelector和podSelector是彼此独立的两个单独的匹配规则。它适用于 ORing 两种流量源类型。
你可以使用ipBlock字段允许来自或者到达特定 IP CIDR 范围的 Ingress 或 Egress 流量。Pod IP 是临时的,因此这些 IP 应该是集群外部的 IP。
最后,可以指定允许网络连接到 Apache Pod 的端口。从上面的清单显示,该实验允许网络连接到 TCP 80 端口,即 HTTPD 服务器侦听连接的端口。
Egress 规则与 Ingress 规则非常相似,只是它们定义了流量的目的地。与 Ingress 的情况一样,Egress 规则可以基于podSelector、namespaceSelector和 ipBlock。
总结一下,它可以用以下两种方式允许网络连接到default命名空间中的 TCP 80 端口上所有带有app=httpd(Apache web 服务器)标签的 pod:
- 任何具有标签role=frontend的 Pod;
- 任何命名空间中具有标签label project=dev的 Pod 。
实验中,Egress 规则允许从“默认”命名空间中的任何 Pod(标签为app=httpd)连接到 TCP 端口为5978上的 CIDR(范围10.0.0.0/24)。
你现在应该已经了解了NetworkPolicy的工作原理,继续创建它:
kubectl create -f npolicy.ymlnetworkpolicy.networking.k8s.io/test-np created第 4 步:测试网络策略
在此之前,该实验已经部署了 Cilium,大家可以期待一下NetworkPolicy之后的工作情况。现在,实验人员通过使用标签app:busybox创建了一个不同于在 Ingress Pod 选择器指定的 Pod 进行测试 。
使用wget命令:
apiVersion: v1kind: Podmetadata: name: pod1 labels: app: busyboxspec: containers: - name: busybox image: busybox command: ["/bin/sh
















 4155
4155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









