





最近在做一个自动化测试项目,遇到公众号元素定位无法找到的情况,通过uiautomator查看元素,按钮有text值,试了很多方法,通过xpath的@text方法没找到,后来也通过层级也没找到,而且找元素的等待时间我也都设置的30s,姑且认为我的xpath写法是正确的,总之就是没找到的这个元素
 接下来验证我们复制的xpath路径,在console控制台下,输入
$x('复制的xpath路径粘贴到这里'),可以很明显看到标题内容被我们提取到
接下来验证我们复制的xpath路径,在console控制台下,输入
$x('复制的xpath路径粘贴到这里'),可以很明显看到标题内容被我们提取到

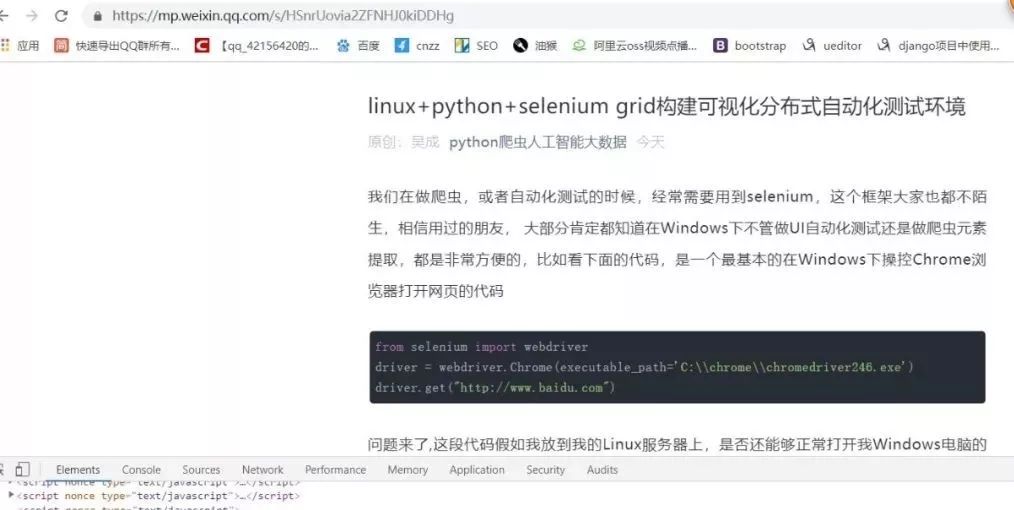
接下来验证我们复制的xpath路径,在console控制台下,输入
$x('复制的xpath路径粘贴到这里'),可以很明显看到标题内容被我们提取到

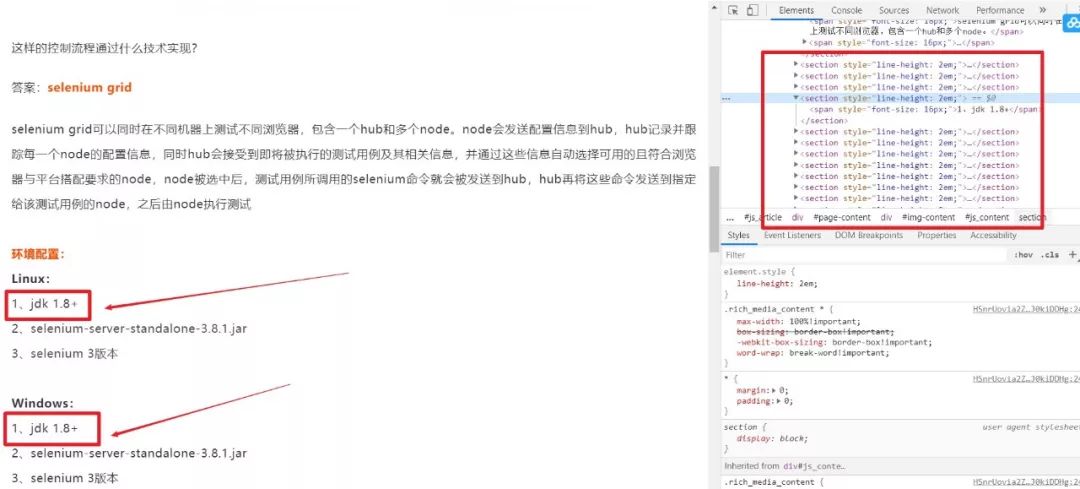

总结:
这种方法如果感兴趣可以用用,一般爬虫和web上我一般很少用,也是在测H5页面的时候走投无路了,才用这个方法,不过有个缺点,有些时候,你复制的xpath路径可能很长很长,不利于直观的去看python爬虫人工智能大数据公众号















 4484
4484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









