





(文章首发于微信公众号:效率视界)
前瞻云
前瞻云是一个企业信息查询接口平台,可以快速获取主体、人员、裁判文书、专利等信息,但是需要按量付费的,前瞻云就是企查猫网站的数据源。
官网地址:https://open.qianzhan.com/
为什么我先尝试前瞻云?不是打广告,只是因为便宜。企业基础信息查询只要一次3分钱,详细查询价格一次2毛钱,首次注册送1元用于测试,但是后续充值最低100元,我比较了一下其他平台,应该是最便宜的了,不过相比天眼查、企查查平台,数据更新速度没有那么快,所以准确度差一点。

申请接口
我编写了两个版本:基础版和详细版
- 基础版:0.03元/次,包含主体信息。
- 详细版:0.20元/次,包含主体信息、联系方式、股东、成员、对外投资和分支机构等信息。
所以,进入官网注册账号后,需要对应的申请这两个接口。
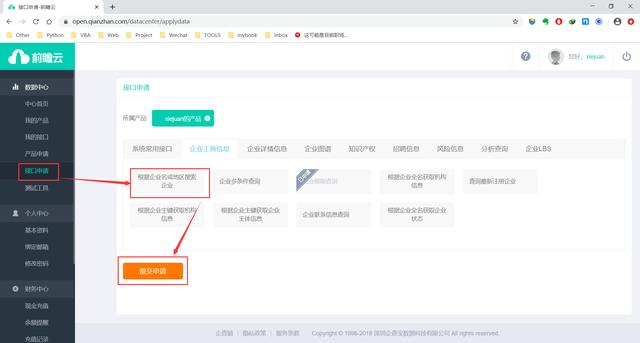
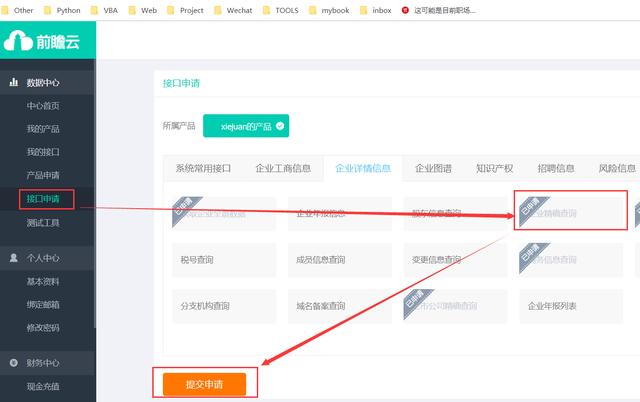
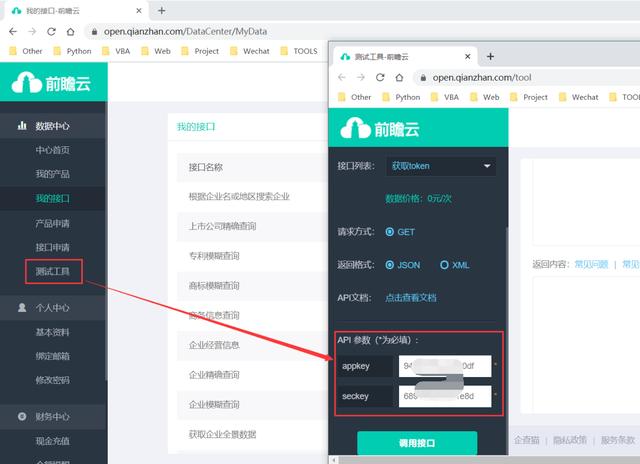
填写配置
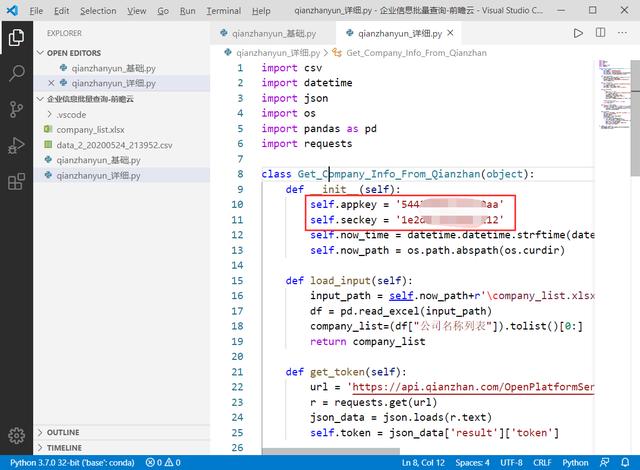
选择「测试工具」会看到 API 参数信息,appkey 和 seckey ,并且需要把这两个信息填入 Py 文档中。
运行代码
把 appkey 和 seckey 填入之后,需要保存 Py 文件。
如果之前 pandas 包没有安装,我们需要单独安装。就像玩英雄联盟有没有想玩的英雄,那就先购买这个英雄。我们可以在cmd终端输入conda install pandas或者pip install pandas安装 pandas 包。
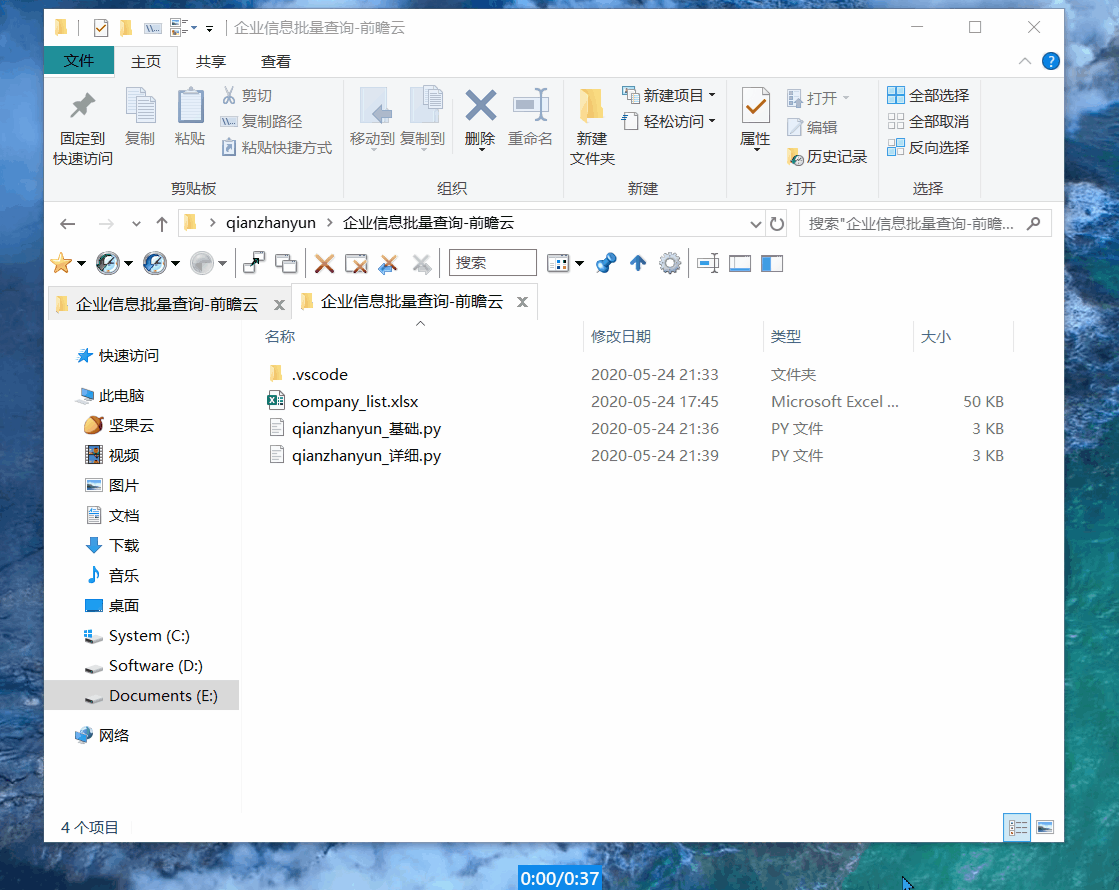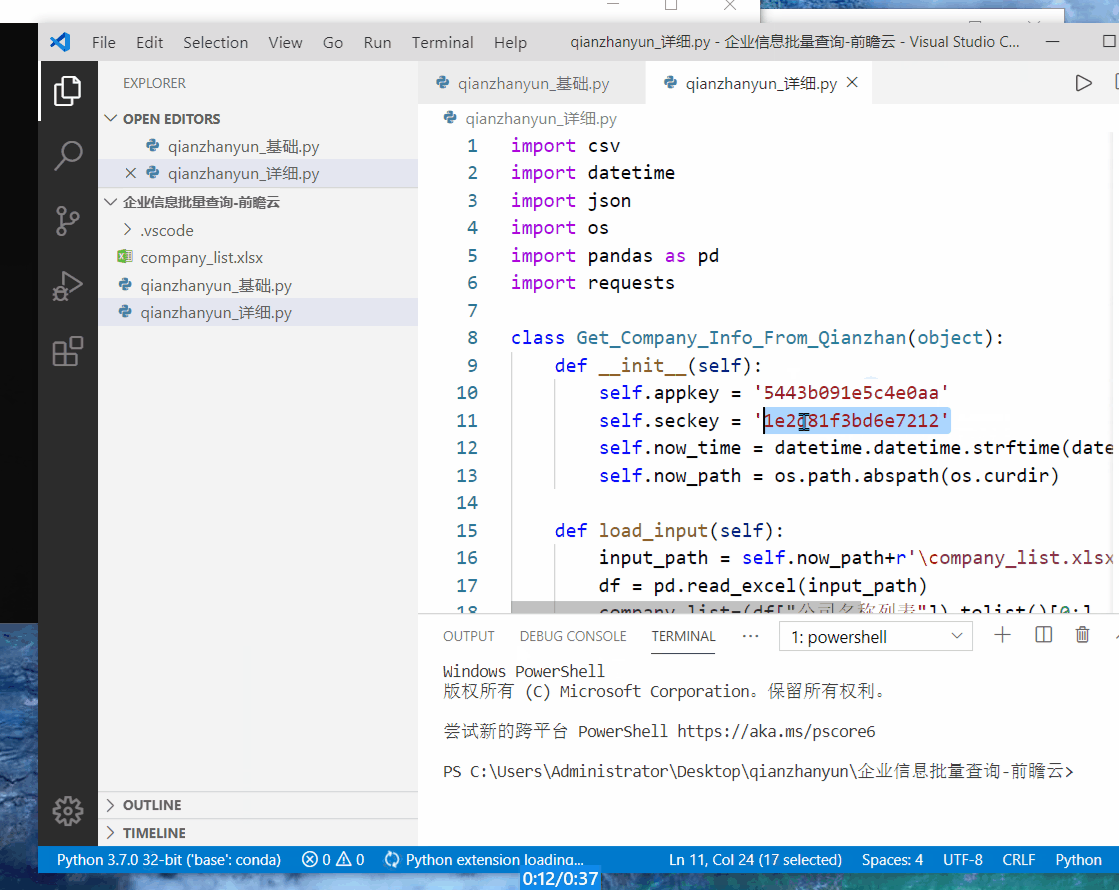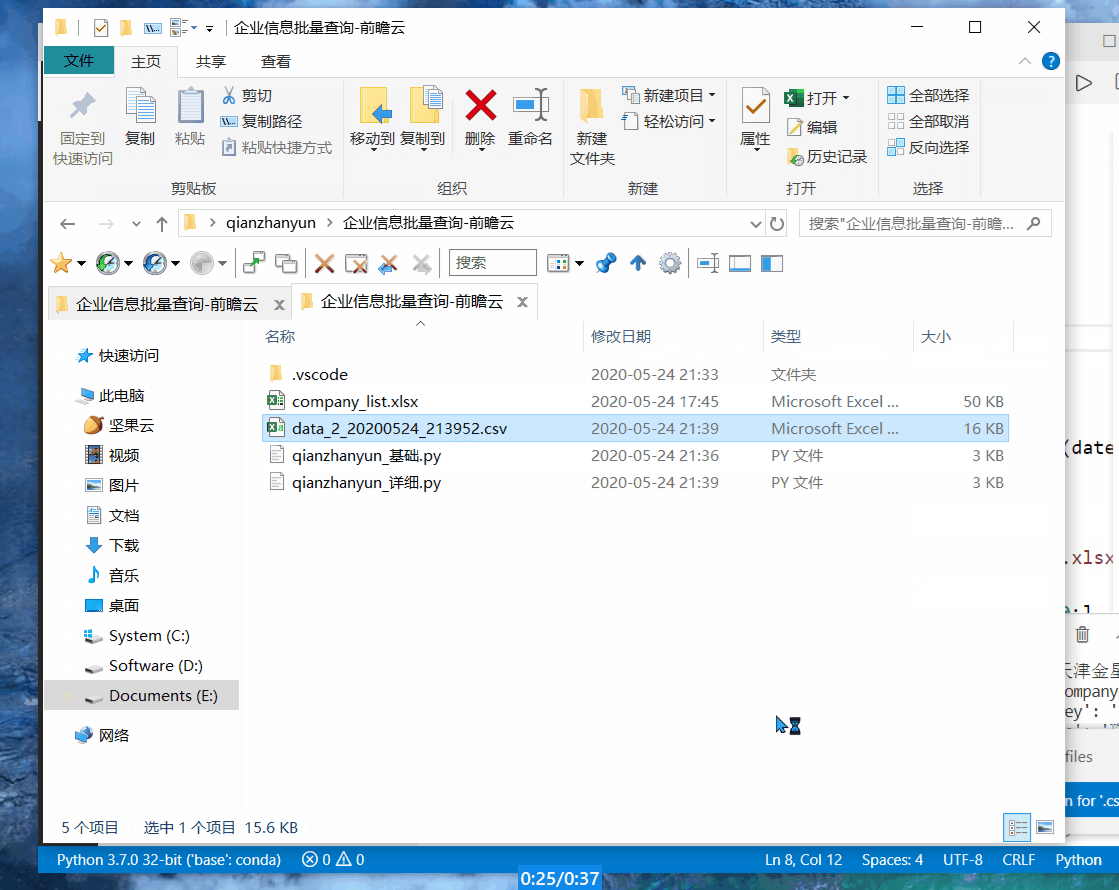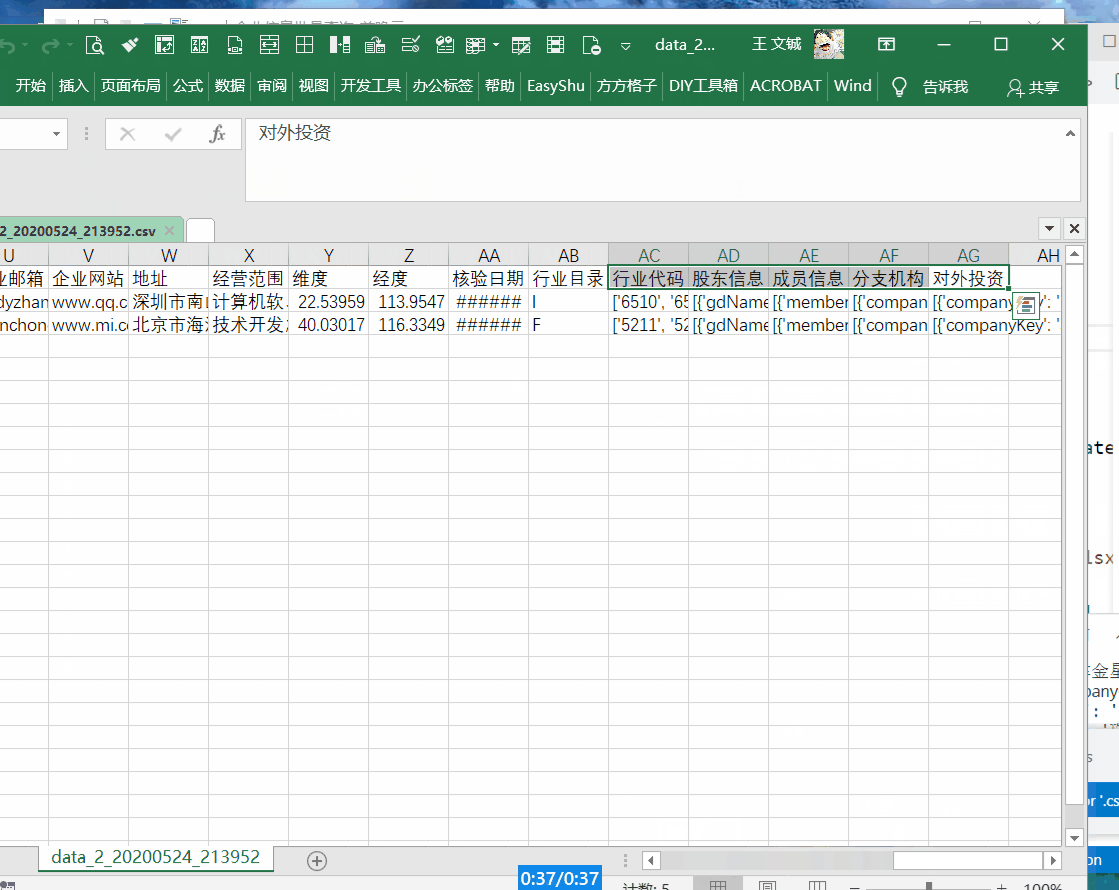
运行结果
详细版,包含主体、联系方式、股东、成员、对外投资和分支机构等信息。100 元可以查询详细版 500 次,或者基础版 3333 次。建议对比一下其他平台,同时考虑数据的准确率。

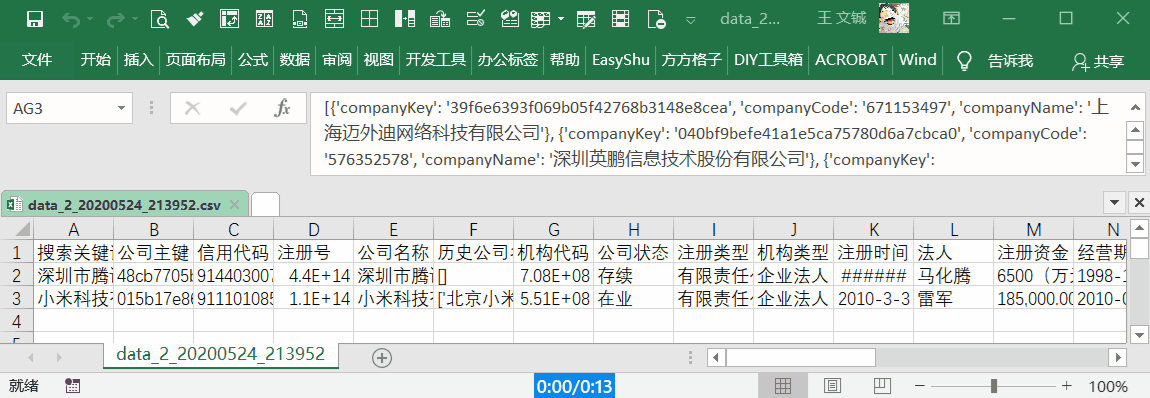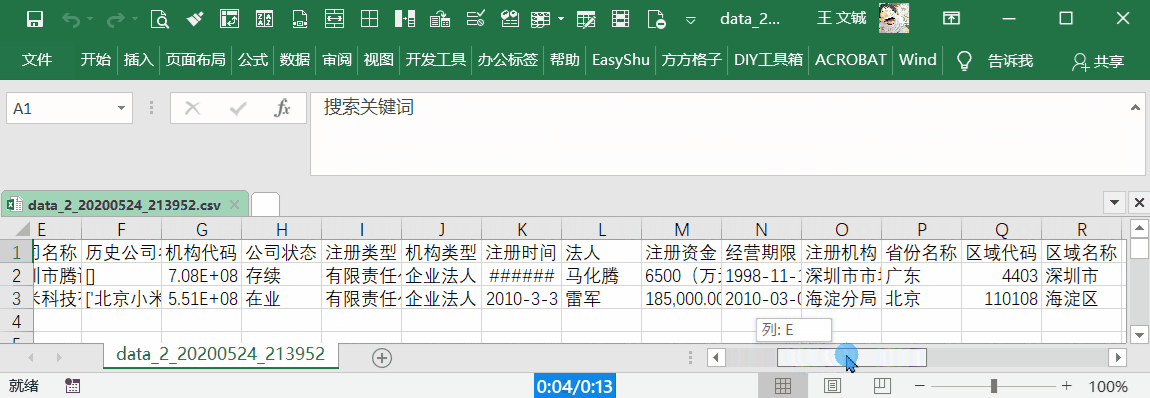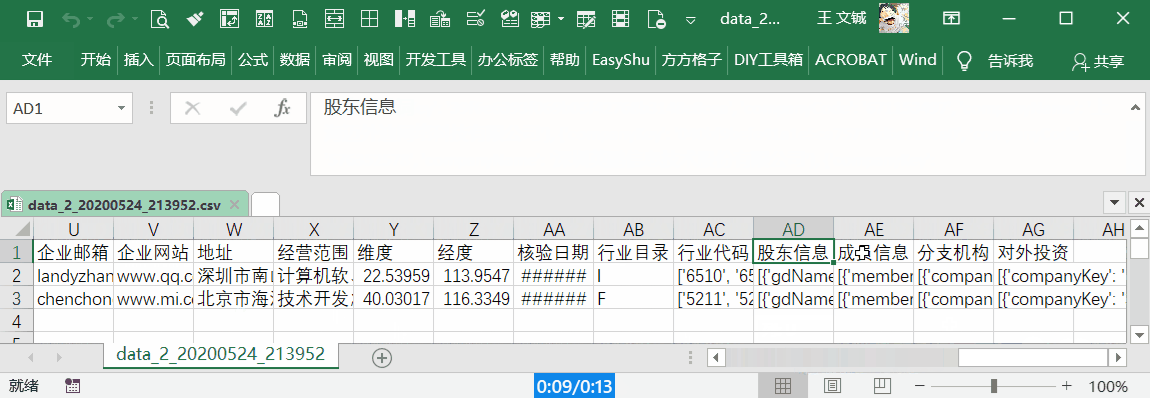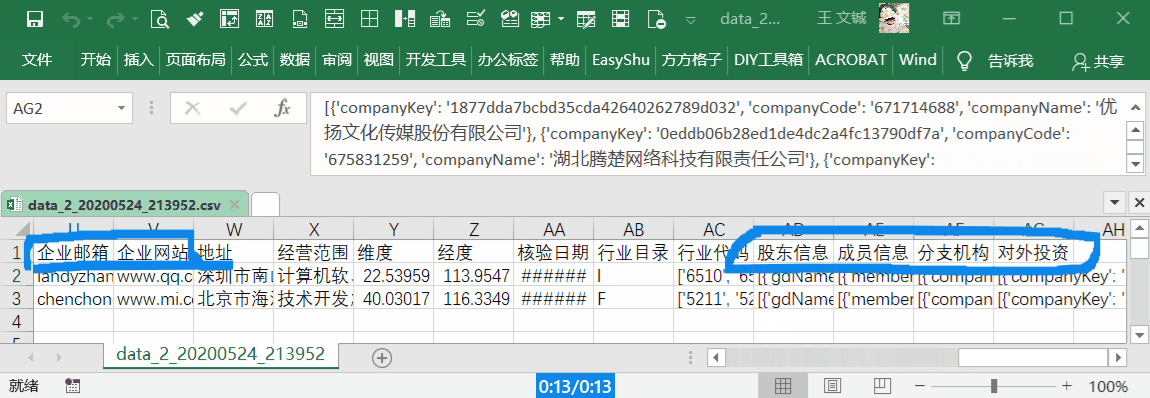
下载工具
基础版和详细版工具代码如何获取?请长按识别下方二维码关注「效率视界」,在公众号后台回复「tools」或者单击后台菜单栏「工具合集」获取本文工具。
基础版完整代码
import csvimport datetimeimport jsonimport osimport pandas as pdimport requestsclass Get_Company_Info_From_Qianzhan(object): def __init__(self): self.appkey = '填入你的appkey' self.seckey = '填入你的seckey' self.now_time = datetime.datetime.strftime(datetime.datetime.now(), '%Y%m%d_%H%M%S') self.now_path = os.path.abspath(os.curdir) def load_input(self): input_path = self.now_path+r'company_list.xlsx' df = pd.read_excel(input_path) company_list=(df["公司名称列表"]).tolist() return company_list def get_token(self): url = 'https://api.qianzhan.com/OpenPlatformService/GetToken?type=JSON&appkey={}&seckey={}'.format(self.appkey,self.seckey) r = requests.get(url) json_data = json.loads(r.text) self.token = json_data['result']['token'] def get_data(self): try: data_list = ['']*18 url = 'http://api.qianzhan.com/OpenPlatformService/OrgCompany?token={}&type=JSON&companyName={}&areaCode=&page=1&pagesize=2'.format(self.token,self.search_name) r = requests.get(url) json_data = json.loads(r.text) company_data = json_data['result'][0] data_list = [company_data[key] for key in company_data.keys()] except Exception as e: print('"get_data" error: '+ str(e)) return data_list def data_to_csv(self,data): filename = self.now_path + r'data_1_{}.csv'.format(self.now_time) with open( filename ,"a+",newline="") as datacsv: csvwriter = csv.writer(datacsv,dialect = ("excel")) csvwriter.writerow(data) def main(self): title = ['搜索关键词','机构代码','公司主键','公司名称','登记证号','统一社会信用代码','省份名称','区域代码','区域名称','机构类型','登记日期','登记机关','经营范围','经营状态','企业法定代表人','注册资本','注册资本(带单位)','主体类型','公司地址'] self.data_to_csv(title) self.get_token() company_list = self.load_input() for i in range(len(company_list)): self.search_name = company_list[i] print('进度:{}/{} 正在查询 {} 的企业信息'.format(str(i+1),str(len(company_list)),self.search_name)) data_list = self.get_data() data = [self.search_name] + data_list self.data_to_csv(data)if __name__ == "__main__": Get_Company_Info = Get_Company_Info_From_Qianzhan() Get_Company_Info.main()














 2269
2269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









