





十大算法 —— Apriori
1、基本介绍
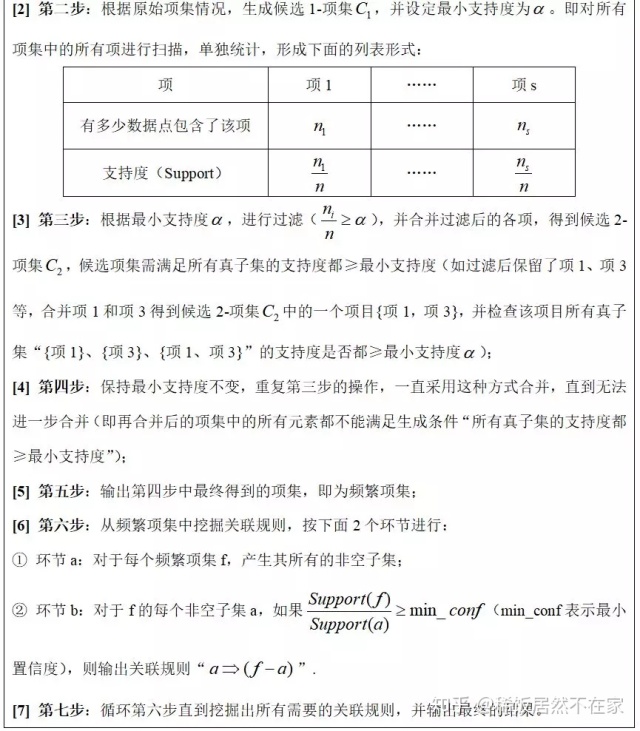
(1)概述:Apriori算法是一种通过频繁项集来挖掘关联规则的算法。该算法既可以发现频繁项集,又可以挖掘物品之间关联规则。分别采用支持度和置信度来量化频繁项集和关联规则。其核心思想是通过候选集生成和情节的向下封闭检验检测两个阶段来挖掘频繁项集。
其最常见的改进算法为AprioriTid算法,该改进算法与原算法的主要区别在于对数据集的更新方式不一样。当数据量较大时,使用改进算法得到的新数据集会比原始数据集小很多,这样在进行遍历的时候就节省了很多时间。
(2)优点
[1] 该算法的关联规则关联规则是在频繁项集基础上产生的,这可以保证这些规则的支持度达到指定的水平,具有普遍性和令人信服的水平;
[2] 算法简单,易于理解,对数据的要求低。
(3)缺点
[1] 在每一步产生候选项目集的时候循环产生的组合过多,没有排除不应参与组合的项;
[2] 每次计算项集的支持度的时候,都对数据库中的全部数据进行了一遍扫描比较,I/O负载很大。
2、算法流程
(1)问题说明

(2)算法步骤(文字描述版)

(3)算法步骤(数学描述版)

3、详细例子
(1)例子一(靠嘴模拟)
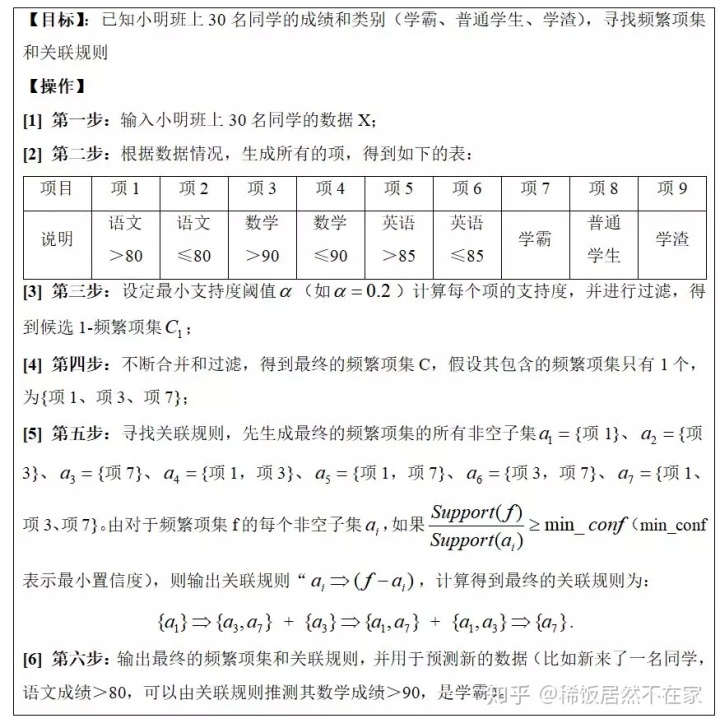
(2)例子二(R语言实操)
[1] 代码
library(arules) # 加载arules包,里面包含了apriori函数
data(Groceries) # 调用里面的关联分析常用的数据集Groceries
f1<-eclat(Groceries,parameter=list(support=0.05,maxlen=10)) # 求频繁项集
inspect(sort(f1,by="support")[1:10]) # 先根据支持度降序排序,然后查看支持度前10的频繁项集
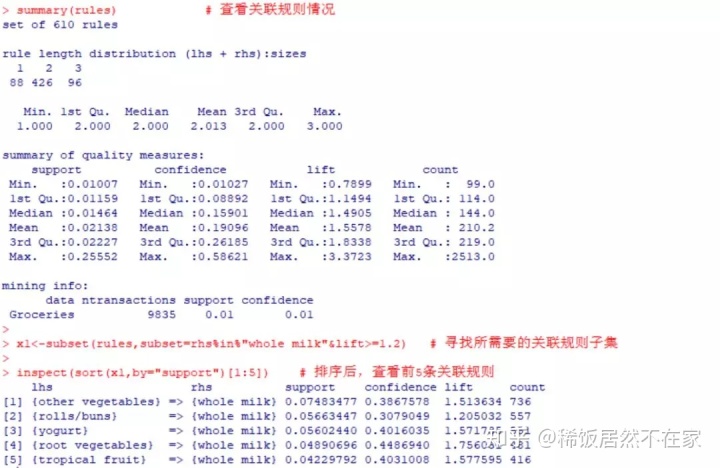
rules<-apriori(Groceries,parameter=list(support=0.01,confidence=0.01)) # 求关联规则
summary(rules) # 查看关联规则情况
x1<-subset(rules,subset=rhs%in%"whole milk"&lift>=1.2) # 寻找所需要的关联规则子集
inspect(sort(x1,by="support")[1:5]) # 排序后,查看前5条关联规则[2] 结果
















 2200
2200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









