






ThriftPy 是由饿了么开源的 Apache Thrift 纯 Python 实现。它在基本兼容 Apache Thrift 的同时相比 Apache 社区的实现有以下优势:
- Apache Thrift 由 C++ 渲染 Python 模板代码实现,因此需要在更新 Thrift IDL 文件后重新生成模板代码;而 ThriftPy 充分利用了 Python 元编程的优势,可以做到在程序的运行时构造 Python 代码,省去了独立的编译过程。
- ThriftPy 相比 Apache Thrift 使用了 Cython 进行加速,因此有更强的性能。
- ThriftPy 的 Transport 内置适配了很多 Python 经典的 Web 服务架构比如 Tornado。
- 最佳实践中提供了诸如 gunicorn_thrift(并发 woker 管理), thrift_connector(连接池) 外围组件的支持。
所以 ThriftPy 可能是 Python 下 Thrift 在生产中的最佳选择了。但由于 ThriftPy 完全没有使用 Apache Thrift 的 (C++) 源码,而是自行实现了所有部分——IDL 编译器、Transport 与 Protocol 等。因此依然存在极少部分与 Apache 版不兼容而被人诟病,其中社区最常反馈的问题就是 ThriftPy 不支持递归定义:
struct Foo {
1: optional Bar test,
}
struct Bar {
1: optional Foo test,
}如果在 Thrift IDL 中定义了以上结构体,在 Apache Thrift 中可以顺利地通过编译,但在老版 ThriftPy 下你会得到一个这样的错误:ThriftParserError: No type found: 'Bar', at line 2。
当我刚入职饿了么的时候,由于对公司底层组件十分感兴趣,所以老板将这个长期以来无法得到解决的问题抛给了我。我在了解这个问题后,就着手拆开 ThriftPy 的封装,直接通过源码定位问题。ThtfitPy 对 IDL 所有的解析行为全部放在 thriftpy/parser 下,虽然包名中只有 Parser,但我们其实可以将它视作一个完整的编译器,其中严格对应 Lexer 与 Parser 部分的其实是一个三方库:Ply。Ply 是一个 Lex / Yacc 的 Python 绑定,其用法是定义一些符合其接口规范的 handler 函数,并在函数的注释中添加所需要处理的上下文无关文法的定义,那么在匹配到对应定义的语法规则时,就直接调用此 handler 函数进行处理。例如:
def parse_foo(p):
"""
foo : foo | 'END'
"""
pass而 Thriftpy 在 Ply 的基础上实现了一个 one-pass compiler,直接在 handler 函数中构造出与 Thrift IDL 定义的 “spec”。这些 spec 以 Python tuple 的结构组织起来,然后作为 thrift_spec 属性被绑定在 TPayload 的子类型上,这些 TPayload 子类型就是 Thrift 类型映射到 Python 的构造类型。Thriftpy 为 TPayload 类型设置了 TPayloadMeta 的元类。TPayloadMeta 动态地依据 thrift_spec 属性生成这些 TPayload 子类型的 __init__ 构造函数,从而达到以下效果:
"""
Thrift definition:
struct Hello {
1: optional string name,
2: optional string greet
}
"""
hello = Hello(name="test", greet="test")简单地整理一下 Thriftpy 编译过程的流水线:
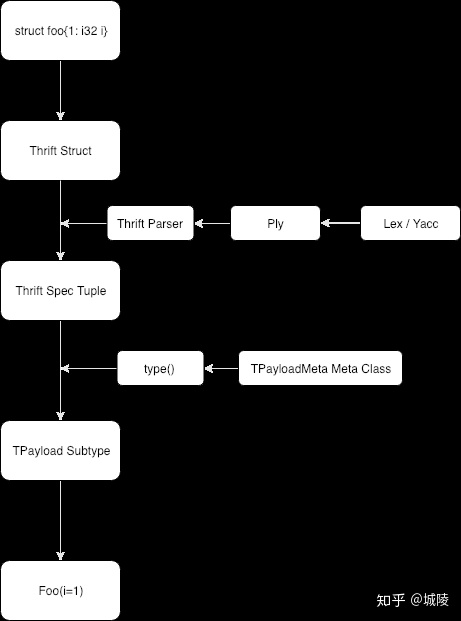
我们已经了解了 Thriftpy 基于元编程编译器的原理。那么 Thriftpy 无法支持递归定义的原因就很容易得出了:由于 Thriftpy 的整个过程只有一个 pass —— 即词法解析、语法解析、构造构造类的整个编译过程只从头到尾顺序地处理了一遍源码(或中间代码),因此当 Ply handler 从 Foo 结构体的定义中读到 Bar 类型的字段时,整个编译器还并不知道在接下来还声明了 Bar 类型。因此不只是递归定义,仅仅只是将某一个类型 A 依赖的类型 B 放在 A 后声明,也依然会有上述的问题。
要解决不依赖顺序定义的问题比较简单 —— 既然编译器只是在当前状态下无法得知后续声明的信息。那么我们使用类似语法分析器 LL(n) 的思路,允许编译器在遇到当前未定义的类型时向后 “偷看” 在接下来的定义中是否存在同名的类型声明。但是在尝试这样的思路后,我发现这并不能解决递归定义的问题,依然用文章开头的定义作为例子,在编译器遇到 Foo 中的 Bar 类型字段时,编译器按照上述思路应该向后 “偷看” 后续 Bar 类型的声明,但此时 Foo 类型还没有被 Parser 构造出来!在这样的状态下,编译器如果偷看到 Bar 的定义并转而进行处理,那么在遇到其中的 Foo 类型字段时,由于此时编译器的上下文中并不存在 Foo 类型的定义,只能选择继续向前偷看 Foo 的定义。这样编译器就陷入了无法停机的状态中。
因此,我们可以得出结论:在 one-pass compiler 中,我们几乎没有办法对递归类型进行支持。在经过长考后,我认为解决此问题的方法只能是为 Thtiftpy 的编译器再增加一个 pass,用于处理所有在第一个 pass 后依然处于未知的类型。它的思路是这样的:
- 在 Ply 的第一个 pass 中,作以下修改:
- 增加一个 incomplete types 的字典,作为上下文用于存储所有在这个 pass 中遇到的未知类型的符号(即类型的名称)。由于 Thrift 不支持局部定义,所有的类型声明都必须在 top level,因此简单地将这个上下文放在全局作用域下。
- 当编译器读到未知定义的类型时,捕获未知定义的异常,先暂且用一个全局唯一的标记填充这个类型 “空洞“(在 Thriftpy 中实际选择的是自减的负数整型)。并以未补完标记作为 key,未知类型的符号作为 value 存入 incomplete types 中。
- 输出一棵带有若干未补完标记的语法树。
- 如果在第一个 pass 结束后读到 incomplete types 不为空,那么开始第二个 pass,在其中需要处理:
- 在遇到任意的未补完标记时,查询 incomplete types 中的类型符号,然后在第一个 pass 已编译好的语法树中查询是否存在这样的类型定义,如果没有则抛出未定义异常。
- 如果查询到了定义,将定义 ”填充“ 回未补完标记中。
在新加了一个 Pass 的情景下,编译器不再有无法停机的危险,因为无论是 Foo 还是 Bar,它们都已经在第一个 pass 中被妥当地处理并且被加入语法树(尽管它们的 thrift_spec tuple 中都有一些未填充的部分),那么在第二个 pass 中仅仅需要的是将上下文中的定义填充回缺失的部位即可。
不过等等,为什么 Foo 和 Bar 可以互相补全?我相信大家都尝试过以下的小把戏:
a = []
b = [a]
a.append(b)
print a # Out: [[[...]]]在 Python 中,所有的类型都是引用语义,在一个 Python 的复合类型中,实际被保存的是指向实际堆上内存的指针而已,那么我们就可以轻松地定义一个递归包含的结构。而如上所述,经过语法解析后得到的 thrift_spec 是一个 tuple(复合类型),并且对于指定的类型,映射到的 thrift_spec 在 Thriftpy 中均为单例。那么在互相填充的过程中,我们其实构造了一个递归包含的结构。
在理清思路后,我们就可以尝试将第二个 pass 的编译过程用伪代码表示出来了,首先是在第一个 pass 中所需要的 incomplete type,它被构造为一个全局单例:
class CurrentIncompleteType(dict):
index = -1
def set_info(self, info):
"""每次调用后返回一个全局唯一的标记"""
self[self.index] = info
self.index -= 1
return self.index + 1
incomplete_type = CurrentIncompleteType() # 全局的单例
def parse_some_type(p):
"""某一个 Ply 的 handler"""
some_field = getattr(p, name, None) # 尝试获取字段类型
if some_field is None: # 如果没有找到该类型的声明
return incomplete_type.set_info((p[1], p.lineno(1))) # 先用标记填充,等待第二个 pass 进行处理接下来是第二个 pass,首先由于在第一个 pass 的返回中我们已经拿到了处理过了的语法树,因此我们不必再使用 Ply 重复进行词法解析与语法解析的部分了。为了方便手写,我们直接使用递归下降解析语法树:
def second_pass(syntax_tree):
return fill_incomplete_type(syntax_tree)
def fill_incomplete_type(syntax_tree):
"""填充未定义类型"""
for key, value in syntax_tree.thrift_spec.items():
# 遍历子节点,如果其中有未补完标记,尝试处理
if value in incomplete_type:
# 在获取到的将要被填充类型中,也有可能存在需要被填充的标记(例如上例中 Bar 的定义内 Foo 类型字段)
# 因此直接递归下降处理之
syntax_tree.thrift_spec[key] = fill_incomplete_type(
get_definition(syntax_tree, value.symbol)
)
def get_definition(syntax_tree, symbol):
"""获取当前语法树中的定义"""
ttype = getattr(syntax_tree, symbol, None)
if not ttype:
raise ThriftParserError('No type found')
return ttype这就是第二个 pass 的骨架,经过这样的处理,syntax_tree 变量指向的语法树中所有的未补完标记都可以被补全了。但实际工程中我们还有更细致地内容要处理,比如我们的 fill_in_complete_type 仅仅只处理的 struct 类型的声明。在 Thrift 中 还有 type alias, module, service, const 等等类型内部可能出现未补完标记而需要被填充。因此实际的定义可能和以下类似:
def fill_incomplete_type(syntax_tree):
if syntax_tree.ttype == "SERVICE":
# ...
pass
elif syntax_tree.ttype == "MODULE":
# ...
pass
# ...
elif syntax_tree.ttype = "STRUCT":
for key, value in syntax_tree.thrift_spec.items():
if value in incomplete_type:
syntax_tree.thrift_spec[key] = fill_incomplete_type(
get_definition(syntax_tree, value.symbol)
)这样看起来就很像一个粗糙的解析器了 :-D 。Thriftpy 中实际具体的实现在这个 pull request,按照以上的结构去理解,就可以理解完整的代码是如何工作的了。
至此我顺利地解决了 Thriftpy 依赖 IDL 定义顺序的问题,这是我第一次在实际工作(是工作吗...?)中遇到与编译原理相关的问题。在思考问题的解决方法时,我也没有找到相关如何处理该问题的中英文资料,因此我认为这个解决方案应该有被记录下来的价值,所以将此整理为这篇文章以供参考。














 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









